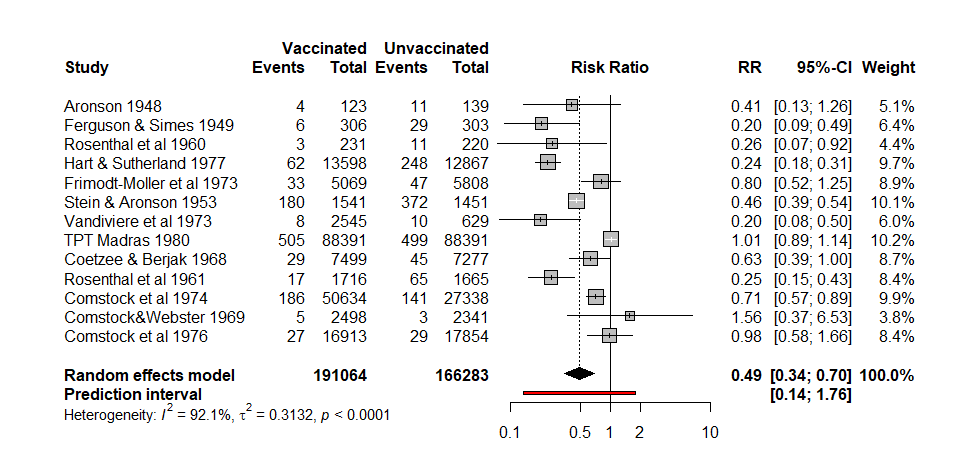
メタアナリシスでは複数の研究の効果推定値の統合値とその95%信頼区間が計算されます。ランダム効果モデルでは研究間のばらつきの指標としてτ2値が計算され、予測区間Prediction Intervalの計算は統合値の分散にτ2(タウ二乗)を加算した値を元に計算されます。そのため予測区間は信頼区間よりも幅広くなり、τ2が大きいほど、またI2が大きいほどその差が大きくなります。ただし、予測区間に意味があるのはランダム効果モデルの場合です。
また信頼区間は正規分布を元に計算するのが一般的で、95 %信頼区間であればZ値1.96を統合値の標準誤差に掛け算して±して計算します。一方、予測区間の場合も、正規分布を用いることが可能ですが、正規分布ではなくt分布に基づいて計算することが一般的で、研究数-1の自由度のt分布におけるp = 0.975(累積確率が0.975)のt値を統合値の標準誤差に掛け算して±して計算します。Rのメタアナリシス用のパッケージであるmetaでのmetabin等の関数のデフォルトの設定は、t分布を用いる様になっています。
信頼区間に正規分布、予測区間にt分布を用いると、τ2値が0の場合でも、これら二つの区間は違う値になり、t分布の方が幅が広くなります。もし、両方とも正規分布あるいはt分布を用いれば、τ2値が0の場合は、同じ値になるはずです。また、τ2値の計算にDersimonian-Laird法を用いる場合と、REML(Restricted Maximum Likelihood)法を用いる場合でも異なる値になる可能性があります。(現在は、REML法の使用が推奨されています。)
Rのメタアナリシス用のパッケージであるmetaforでは予測区間の計算はrma関数の結果に対してpredict関数で処理することで行われますが、デフォルトでは正規分布に基づいて計算されるようになっています。metaforの場合は、rma関数で引数test=”t”に設定すると、信頼区間がt分布に基づいて計算され、その結果をpredict関数で処理するとt分布に基づく予測区間が得られます。信頼区間をデフォルトの設定で正規分布に基づいて計算した場合、予測区間をt分布に基づいて計算するには自分で計算する必要があります。
正規分布の場合の計算式は以下のとおりですが、t分布の場合は、z1-α/2をt1-α/2に置き換えて計算します。t分布の自由度は、研究数をkとした場合k – 1です。95%予測区間の場合は、α=0.05です。
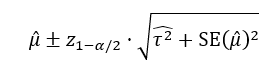
metaforの場合、例えばrma関数で処理した結果を変数resに格納したとすると、t分布に基づく予測区間の計算は以下のスクリプトで計算できます。resから統合値b、その標準誤差se、τ2値 tau2、研究数kを得て、qt関数で得たt値 tvalを合わせて95%予測区間を計算します。この例は、リスク比の場合なので、b、se、τ2値は対数スケール上で計算されているので、変数convlogを1に設定し、上限値uppert、下限値lowertからExponentialを計算し、predupt、predlowtを計算しています。
#Prediction Interval based on t-distribution.
mu_hat = res$b
se_mu = res$se
tau2 = res$tau2
k = res$k
tval = qt(0.975, df = k - 1)
lowert = mu_hat - tval * sqrt(se_mu^2 + tau2)
uppert = mu_hat + tval * sqrt(se_mu^2 + tau2)
predlwt=lowert
predupt=uppert
if(convlog==1){
predlwt=exp(lowert)
predupt=exp(uppert)
}すでに述べたように、τ2値が0の場合は、95%信頼区間も95%予測区間も同じ正規分布、あるいはt分布を用いて計算すれば同じ値になるはずです。しかし、例えばmetaの場合であれば、デフォルトでは信頼区間は正規分布で予測分布はt分布なので、同じ値にはなりません。
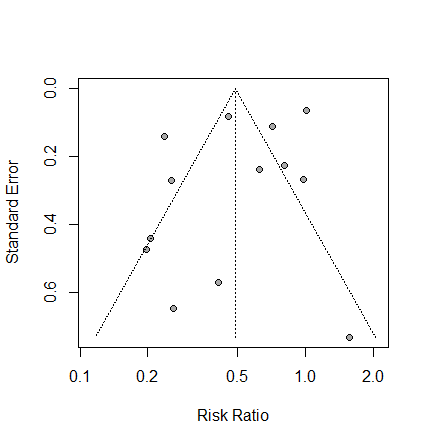
Cochrane Handbook for Systematic Reviews of Interventionsによるとメタアナリシスの結果を提示する際に、統合値の信頼区間(Confidence Interval)に加えて予測区間(Prediction Interval)を含めることは、必須とまでは明記されていませんが、特にランダム効果モデルを用いたメタアナリシスにおいては、それを含めることが強く推奨されており、適切でない解釈を避けるために重要であるとされています。ただし、ソースは、研究数が適切(例:5つ以上)で、ファンネルプロットに明確な非対称性がない場合に、予測区間の使用を推奨しています。そして、研究数が少ない場合、予測区間は見せかけ上、広く見えたり狭く見えたりする可能性があり、問題となることがあるとされています。(10.10.4.2 Interpretation of random-effects meta-analyses)
また、metaやmetaforでは、頻度論派Frequentistの方法でメタアナリシスを実行していますので、信頼区間は真の効果推定値の分布を表しているわけではありません。同じことを繰り返したら、そのたびに異なる信頼区間の値が得られますが、95%の場合は、真の値がその間に含まれているという意味です。例えば、リスク比が1.0以上になる確率を知りたい場合、頻度論派の信頼区間に基づいて推測するのではなく、ベイジアンメタアナリシスの確信区間に基づいて推測する必要があります。前者の場合、信頼区間と確信区間がほぼ同じということを前提にしていることになります。
文献:
Higgins JP, Thompson SG, Spiegelhalter DJ: A re-evaluation of random-effects meta-analysis. J R Stat Soc Ser A Stat Soc 2009;172:137-159. doi: 10.1111/j.1467-985X.2008.00552.x PMID: 19381330
URL: https://pubmed.ncbi.nlm.nih.gov/19381330/
Cochrane Handbook for Systematic Reviews of Interventions
URL: https://www.cochrane.org/authors/handbooks-and-manuals/handbook
metafor https://cran.r-project.org/web/packages/metafor/index.html
Viechtbauer W (2010). “Conducting meta-analyses in R with the metafor package.” Journal of Statistical Software, 36(3), 1–48. doi:10.18637/jss.v036.i03.
meta https://cran.r-project.org/web/packages/meta/index.html
Balduzzi S, Rücker G, Schwarzer G (2019). “How to perform a meta-analysis with R: a practical tutorial.” Evidence-Based Mental Health, 153–160.
ランダム効果モデルのメタアナリシスの結果を臨床に適用する場合、Prediction Intervalも含め結果の解釈には注意が必要です。YouTube チャンネル IZ statに「メタアナリシスの臨床応用:ランダム効果モデルの解釈-ダイアログ- 」の動画を公開しています。
IZ stat URL:https://www.youtube.com/channel/UCqzzJbfQwKDvValptCAM4gg