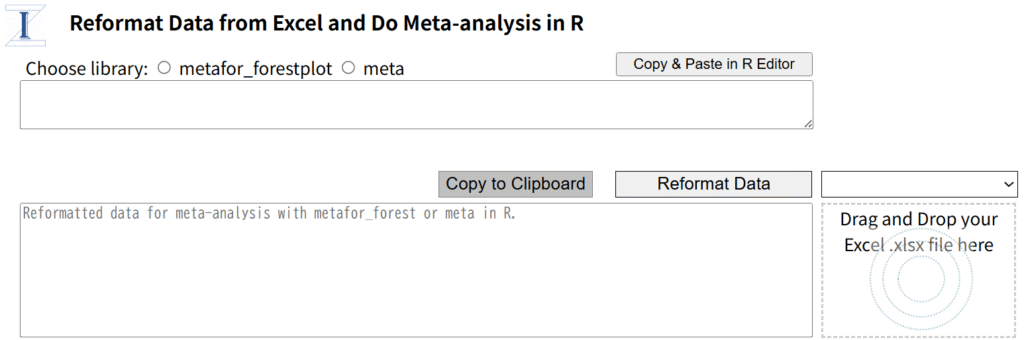
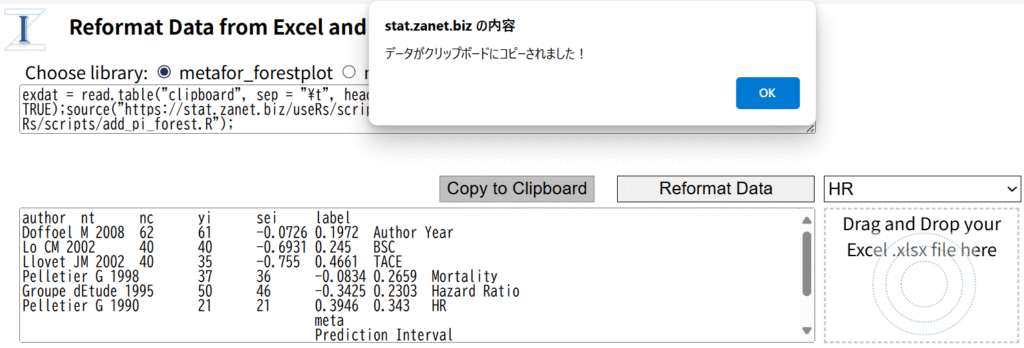
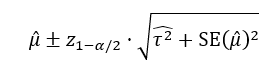Excelファイルをドラグアンドドロップすることで、各シートのデータを読み込み、ドロップダウンメニューのシート名の一覧からシートを選択し、Reformat Dataでmetaあるいはmetaforで処理できる形式にreformatするウェブページに、上記のRスクリプトを選択するパネルを設定したウェブページを作成しました。Reformat Data from Excel and Do Meta-analysis URL: https://stat.zanet.biz/sr/drop_ex_cb.htm
図1.Reformat Data from Excel and Do Meta-analysis in R.
Reformat Data from Excel and Do Meta-analysis URL: https://stat.zanet.biz/sr/drop_ex_cb.htmを使う利点は、複数のシートを含むExcelファイルを1回読み込ませると、各シートのデータに対してメタアナリシスをセルの範囲を選択することなく、連続して、実行できる点です。益と害の複数のアウトカムに対するメタアナリシスを行う場合、それぞれのアウトカムに対してひとつのシートにデータが入力されていると思いますが、それらに対するメタアナリシスを続けて実行できます。
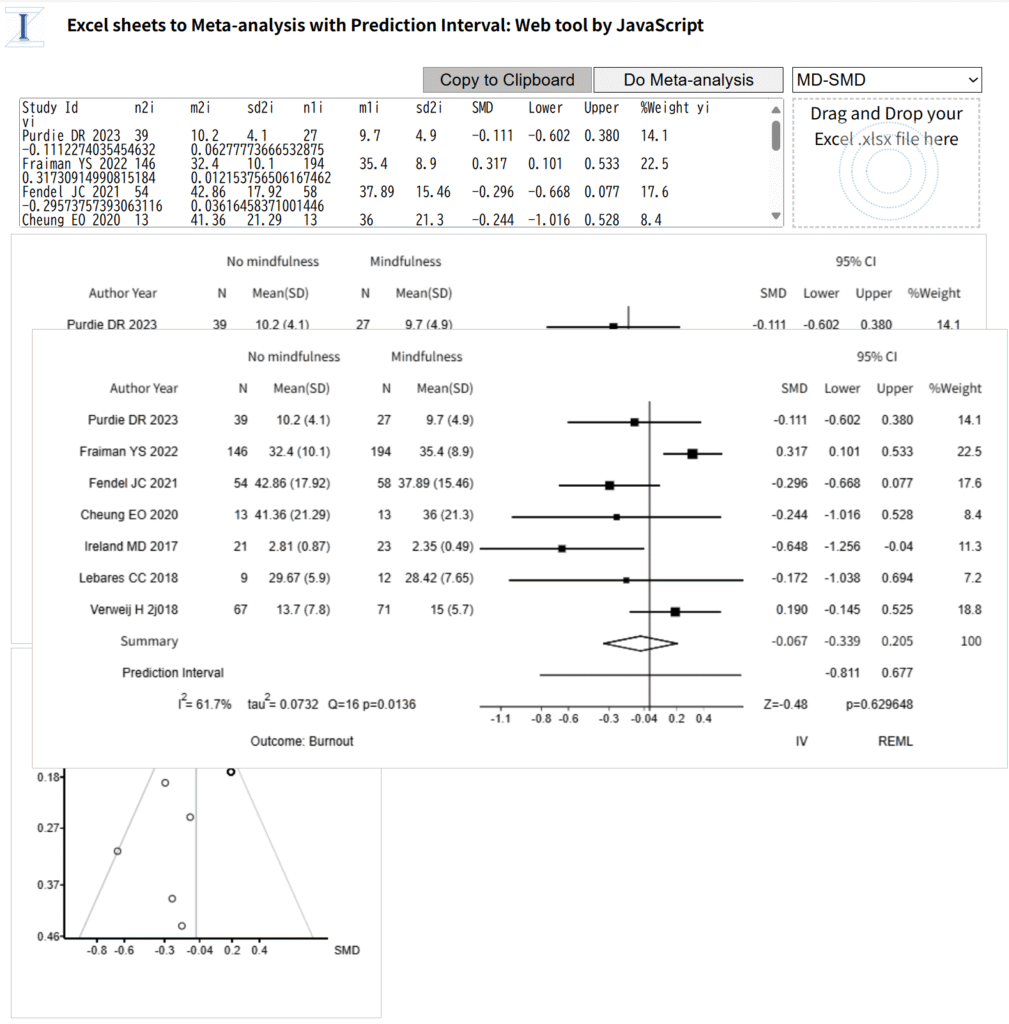
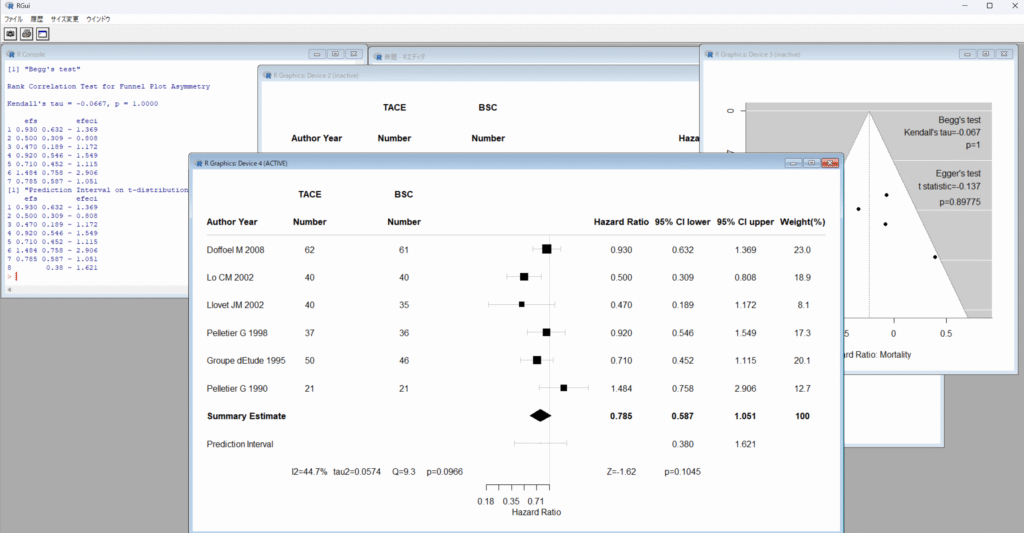
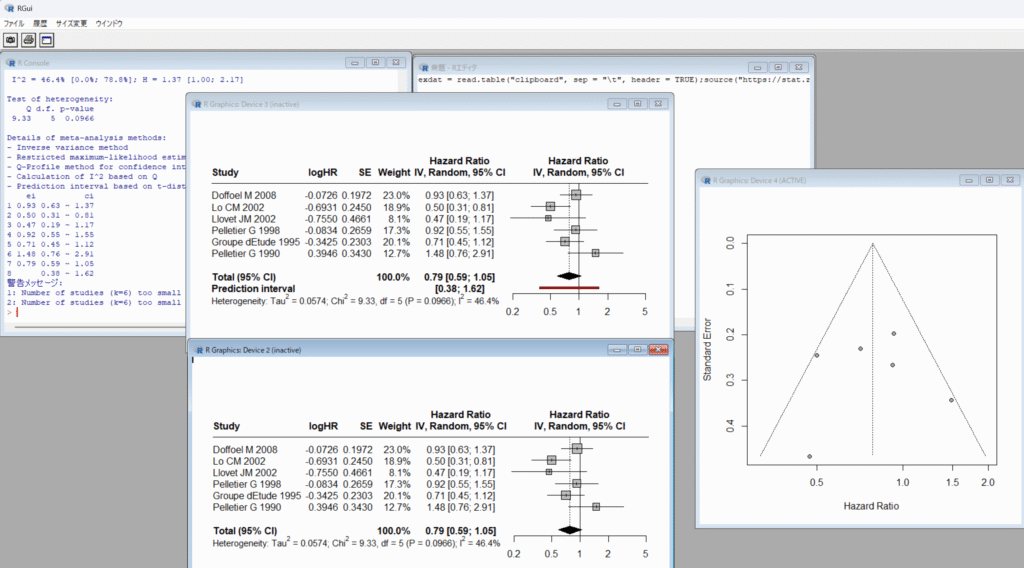
信頼区間に正規分布、予測区間にt分布を用いると、τ2値が0の場合でも、これら二つの区間は違う値になり、t分布の方が幅が広くなります。もし、両方とも正規分布あるいはt分布を用いれば、τ2値が0の場合は、同じ値になるはずです。また、τ2値の計算にDersimonian-Laird法を用いる場合と、REML(Restricted Maximum Likelihood)法を用いる場合でも異なる値になる可能性があります。(現在は、REML法の使用が推奨されています。)
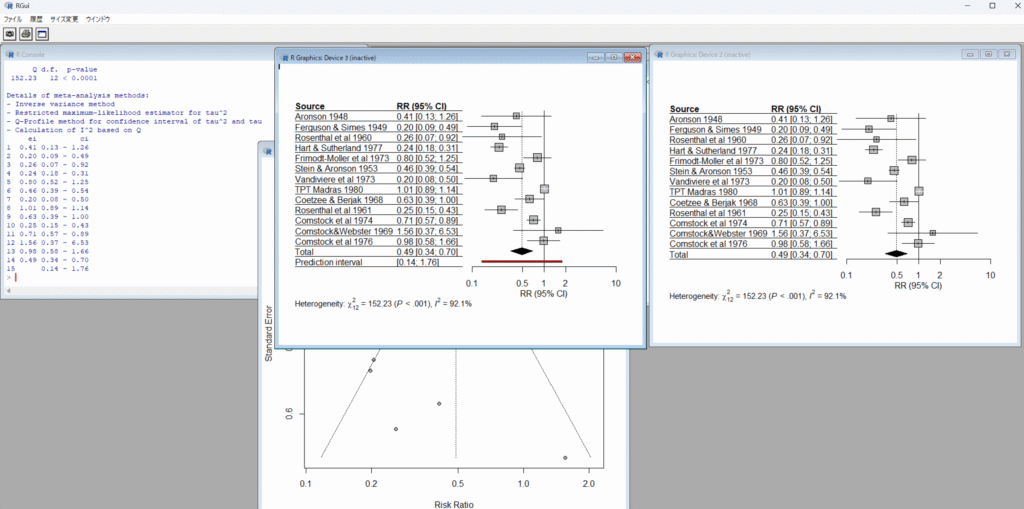
Cochrane Handbook for Systematic Reviews of Interventionsによるとメタアナリシスの結果を提示する際に、統合値の信頼区間(Confidence Interval)に加えて予測区間(Prediction Interval)を含めることは、必須とまでは明記されていませんが、特にランダム効果モデルを用いたメタアナリシスにおいては、それを含めることが強く推奨されており、適切でない解釈を避けるために重要であるとされています。ただし、ソースは、研究数が適切(例:5つ以上)で、ファンネルプロットに明確な非対称性がない場合に、予測区間の使用を推奨しています。そして、研究数が少ない場合、予測区間は見せかけ上、広く見えたり狭く見えたりする可能性があり、問題となることがあるとされています。(10.10.4.2 Interpretation of random-effects meta-analyses)
Higgins JP, Thompson SG, Spiegelhalter DJ: A re-evaluation of random-effects meta-analysis. J R Stat Soc Ser A Stat Soc 2009;172:137-159. doi: 10.1111/j.1467-985X.2008.00552.x PMID: 19381330 URL: https://pubmed.ncbi.nlm.nih.gov/19381330/