Excelで一定の形式でデータを入力して、アドインメニューからDo Meta-analysisをクリックすると、ブラウザが開かれ、Forest plot、Funnel plot、結果の数値データが表示されるMeta-analysis IZ exというExcel bookを作りました。インターネットに接続された環境で使用します。
VBAで書かれたプロブラムで、メタアナリシスに必要なデータを結合して、GETメソッドで送信し、PHPのプログラムで受信し、JavaScriptのプログラムで解析して、ブラウザに結果を表示します。Forest plot、Funnel plotは右クリックしてコピーしたりPENGファイルとして保存できます。
VBAのプロブラムを動かすには、Excelでマクロが動作する設定にする必要があります。必要な場合、Excelファイルを開いてから、ファイルメニュ–>オプション–>トラストセンター–>トラストセンターの設定(T)…ーー>マクロの設定–>VBAマクロを有効にするをチェックしてください。一度閉じて、再度開いてください。このマクロに関する設定は、他のExcelファイルに対しても適用されるので、他のExcelファイルでマクロが付いている場合も、無条件にマクロが実行可になります。セキュリティ上は、電子署名されたマクロを除き、VBAマクロを無効にする(G)の設定が望ましいので、さまざまなソースのExcelファイルを使用する方は、あとで設定をそのように変更してください。
このExcel bookのファイル名は2025_meta-analysis_ex.xlsmです。下記のLinkからダウンロードして、ダウンロードしたファイルを開いてください。上記のごとく、最初に、マクロを有効化して使用してください。
また、Mindsの評価シートをBookとしてまとめた、2025_excel_book_for_sr.xlsmというファイルと、そこから必要なシートをコピーして、システマティックレビューに使用するシートを集めたBookを各自作るための2025_My_SR Book.xlsmというファイルも入れてあります。システマティックレビュー用の評価シートに必要なデータを入力後、アドインメニューからMeta-analysis → Do Meta-analysisをクリックするとブラウザが開かれ、結果が表示されます。これらのBookの評価シートは、Rのパッケージmetafor, forestpolotを用いて、Rで動作するメタアナリシスを行うのスクリプトも含んでいるのでRを使ってメタアナリシスをすることもできますし、後述するMeta-analysis IZ rというウェブツールを使ってメタアナリシスをすることもできます。
Link: 2025_meta-analysis_ex.zip
2025.2.2 より前にダウンロードされた方、一部修正しましたので再度ダウンロードしてください。ZIPファイルから外に保存してから使ってください。
ここからは、2025_meta-analysis_ex.xlsmについての解説です。最初のシートに使い方の解説があります。二値変数アウトカムの場合、リスク比、オッズ比、リスク差、生存分析の場合、ハザード比、連続変数アウトカムの場合は、平均値差、標準化平均値差を扱えます。
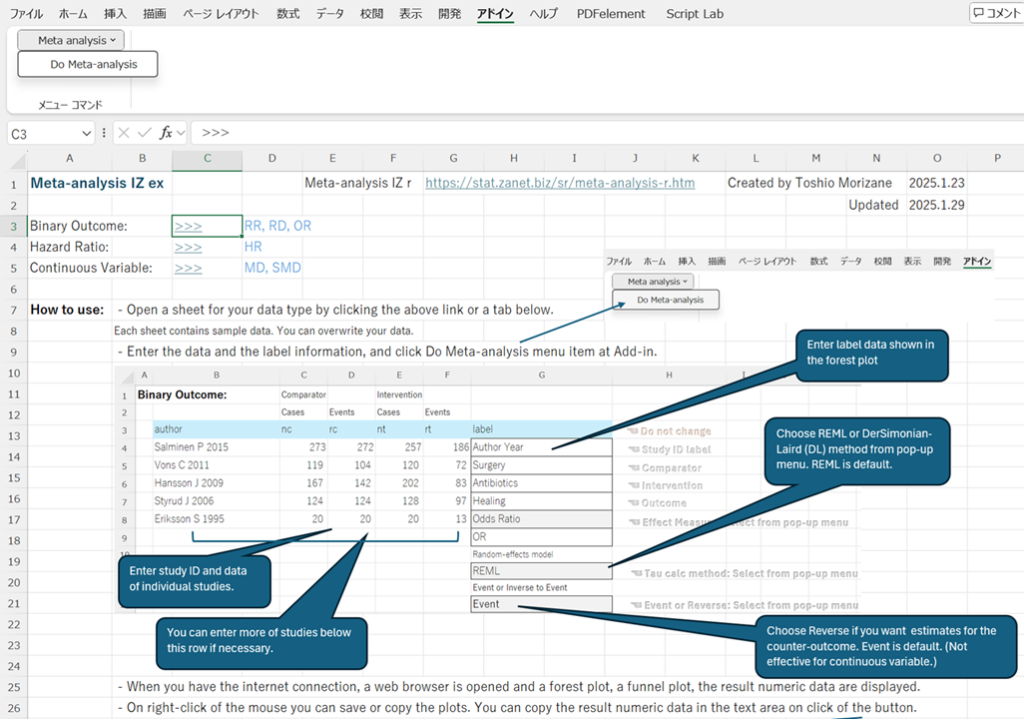
それぞれのシートにはサンプルデータが入力されているので、自分のデータに書き換えて使用してください。
また、シートの任意のセルを選択した状態で、Shift keyを押しながら、Do Meta-analysisをクリックするとその場所に二値変数アウトカム用のデータ入力フレームワークが作成されます。Altキーを押しながら同様の操作でハザード比用、Shift keyとAltキーの両方を押しながら同様の操作をすると連続変数アウトカム用のデータ入力フレームワークが作成されます。それらの位置にデータを入力して、それに対してメタアナリシスを実行する場合は、authorのセルを選択してから、Do Meta-analysisをクリックしてください。その範囲のデータでメタアナリシスを実行します。新規に追加したシートでも同じことができます。デフォルトの位置はセルB3です。新規に追加したシートではまずそこにフレームワークを作成して、使用しましょう。
メタアナリシスの方法は、分散逆数法Inverse-variance method、ランダム効果モデルRandom-effects model、研究間の分散の計算はRestricted Maximum Likelihood (REML)法またはDerSimonian -Laird法です。Rのパッケージのmetaforと同じ結果が得られることを確認してあります。
DerSimonian -Laird法は古典的な方法でRevManはこの方法を用いています。REMLとDerSimonian -Lairdはほぼ同じ結果になりますが、数値は若干異なり、REMLの方をデフォルトにしています。
このExcel bookを用いると、データをコピーしてウェブサイトに貼り付けて、解析するというステップがワンステップで済みます。
YouTubeチャンネルIZ statで解説動画をアップロードしました。Link
Meta-analysis IZ rというメタアナリシスのためのウェブツールでも同じJavaScriptのプログラムで解析しています。Meta-analysis IZ rはこちらのLinkです。
参照リンク:
Rのメタアナリシス用のパッケージ by Viechtbauer W Link
Viechtbauer W (2010). “Conducting meta-analyses in R with the metafor package.” Journal of Statistical Software, 36(3), 1–48. Link
Cochrane RevManの統計学的手法 Deeks JJ and JPT Higgins: Statistical algorithms in Review Manager 2022. PDF