・FDAのStructured Benefit-Risk Framework: 医薬品評価における透明性と一貫性の確保 PDF
・FDAのStructured Benefit-Risk Frameworkと患者選好情報 (PPI) PDF
用語を確認しておきましょう:
Importance of outcome アウトカムの重要性/重要度、Values価値観、Preferences選好の関係は以下の様に表現されると思います。GRADE Working Groupはアウトカムの重要度と患者の価値観は同じことを意味しており、文脈により使い分けると述べています。
文献: Ho M, Saha A, McCleary KK, Levitan B, Christopher S, Zandlo K, Braithwaite RS, Hauber AB: A Framework for Incorporating Patient Preferences Regarding Benefits and Risks into Regulatory Assessment of Medical Technologies. Value Health. 2016;19:746-750. doi: 10.1016/j.jval.2016.02.019 doi: 10.1016/j.jval.2016.02.019 PMID: 27712701
•Boyd CM, Singh S, Varadhan R, Weiss CO, Sharma R, Bass EB, Puhan MA. Methods for Benefit and Harm Assessment in Systematic Reviews. Methods Research Report. (Prepared by the Johns Hopkins University Evidence-based Practice Center under contract No. 290-2007-10061-I). AHRQ Publication No. 12(13)-EHC150-EF. Rockville, MD: Agency for Healthcare Research and Quality; November 2012. Link
Alper BS, Oettgen P, Kunnamo I, Iorio A, Ansari MT, Murad MH, Meerpohl JJ, Qaseem A, Hultcrantz M, Schünemann HJ, Guyatt G, GRADE Working Group: Defining certainty of net benefit: a GRADE concept paper. BMJ Open 2019;9:e027445. PMID: 31167868
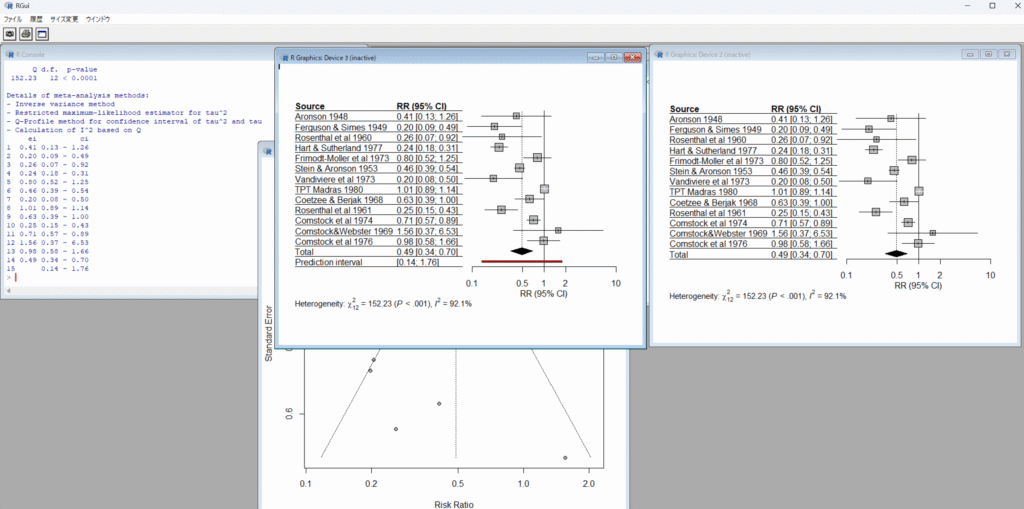
ネットワークメタアナリシス用のソフトウェアとして、頻度論派メタアナリシスのためにはnetmetaというRのパッケージがありますが、gemtcはベイジアンネットワークメタアナリシスのためのRのパッケージで、rjagsというRのパッケージを介してJAGS (Just Another Gibbs Sampler)でMCMC(Malkov Chain Monte Carlo)シミュレーションを実行させます。JAGSとrjagsはあらかじめインストールしておきます。Rで使用する際には、library(rjags);library(gemtc)を最初に実行する必要があるのは、他のRのパッケージと同じです。
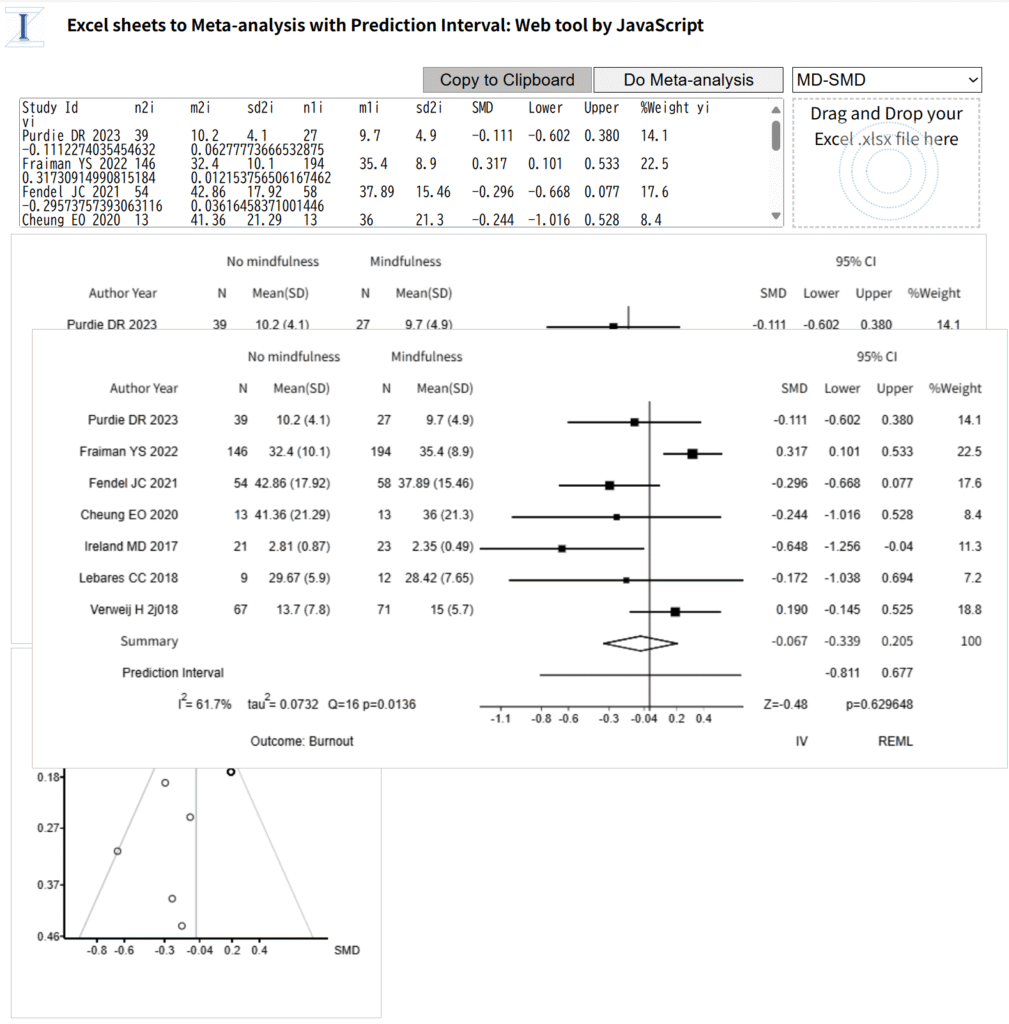
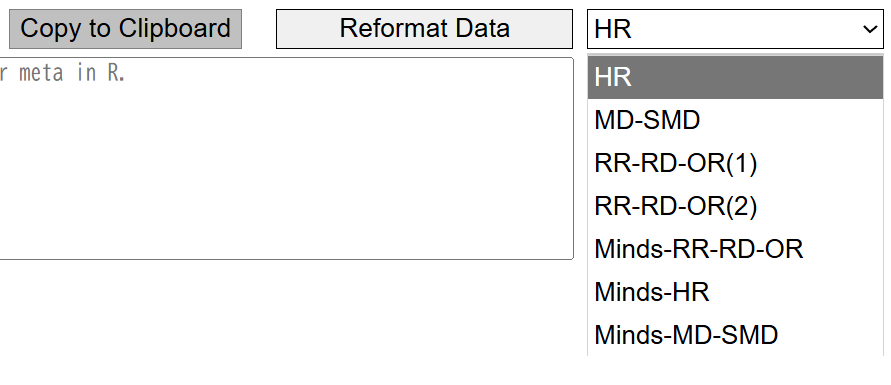
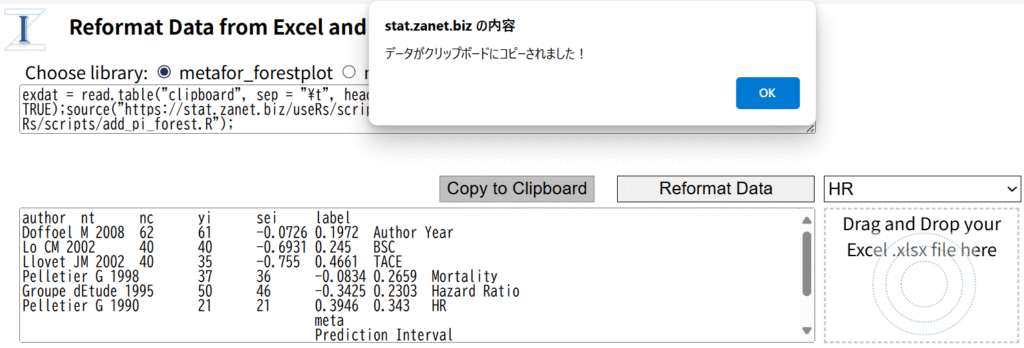
Excelファイルをドラグアンドドロップすることで、各シートのデータを読み込み、ドロップダウンメニューのシート名の一覧からシートを選択し、Reformat Dataでmetaあるいはmetaforで処理できる形式にreformatするウェブページに、上記のRスクリプトを選択するパネルを設定したウェブページを作成しました。Reformat Data from Excel and Do Meta-analysis URL: https://stat.zanet.biz/sr/drop_ex_cb.htm
図1.Reformat Data from Excel and Do Meta-analysis in R.
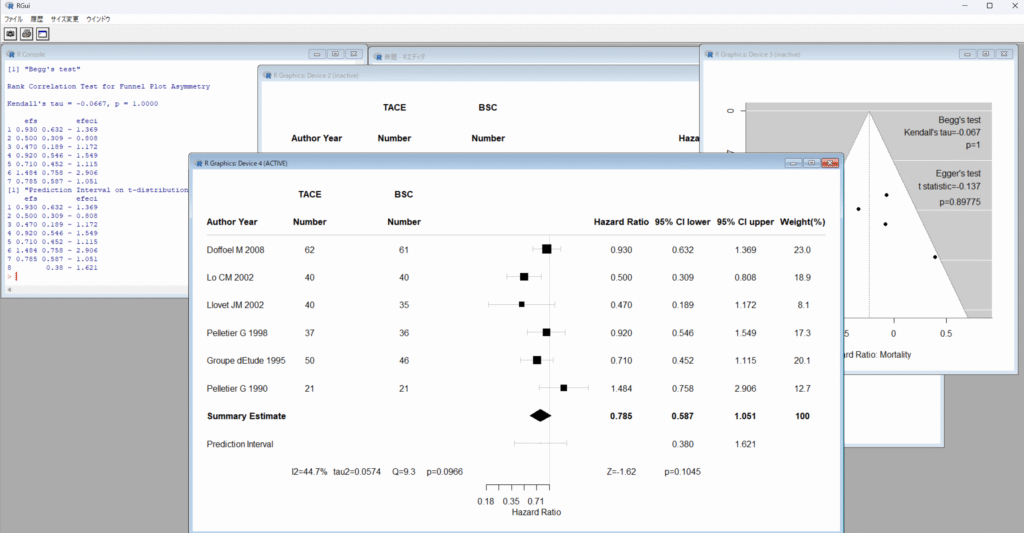
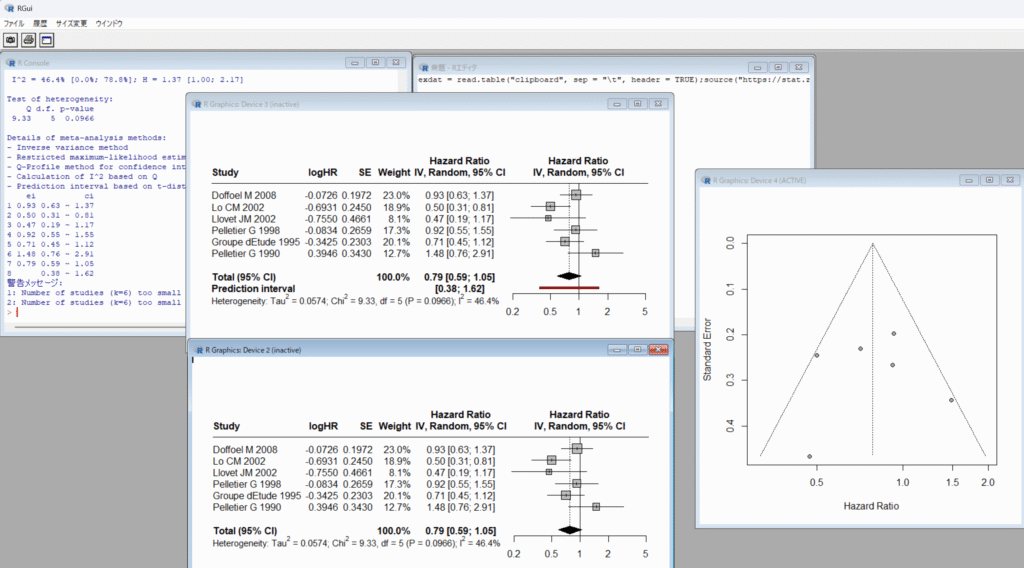
Reformat Data from Excel and Do Meta-analysis URL: https://stat.zanet.biz/sr/drop_ex_cb.htmを使う利点は、複数のシートを含むExcelファイルを1回読み込ませると、各シートのデータに対してメタアナリシスをセルの範囲を選択することなく、連続して、実行できる点です。益と害の複数のアウトカムに対するメタアナリシスを行う場合、それぞれのアウトカムに対してひとつのシートにデータが入力されていると思いますが、それらに対するメタアナリシスを続けて実行できます。