ネットワークメタアナリシスの基礎について解説し、解析の結果えられる情報すなわちアウトプットについて解説し エビデンスの確実性の評価のGRADEアプローチについて解説します。
まずネットワークメタアナリシスの基礎です。
通常のペア比較メタアナリシスとネットワークメタアナリシスをシステマティックレビューの段階で比べてみると、ペア比較メタアナリシスでは、二つの介入のうちどちらの方が効果が優れているかを解析することが目的であるのに対し、ネットワークメタアナリシスでは、介入が三つ以上ある場合で、最も効果が優れているのはどれかを解析することが目的になります 。
臨床決断の場面では、ペア比較メタアナリシスは二つの介入のうち、どちらを選択すべきかという問題に解答を与えてくれますが、ネットワークメタアナリシスは三つ以上の介入のうちどれを選択すべきか、言い換えると最善の介入はどれかという問題に解答を与えてくれる可能性があります。いずれの場合も、それぞれのアウトカムについて、効果の大きさと、確実性に関する情報を与えてくれますが、益と害のバランス、あるいは、正味の益については、さらに複数のアウトカムに渡る解析が必要になります。
診療ガイドラインにおいては、ペア比較メタアナリシスは二つの介入のうちのどちらを推奨すべきかを決めるために必要になるのに対し、ネットワークメタアナリシスは三つ以上の介入のうちどれを推奨すべきか を決めるために有用だと言えます。
また、理論的には、同じペア比較であっても、ネットワークメタアナリシスは直接比較の情報に加え、間接的な比較の情報も活用することで、より確実性の高いエビデンスが得られることが利点と考えられています。
ネットワークメタアナリシスを使う場合には、Transitivity 移行性の概念を理解しておく必要があります。移行性は、介入の相対的効果に影響し得る要素について 介入と対象者が、含める研究間で類似していることを表します。移行性が保たれていることはネットワークメタアナリシスの前提になります。
研究選択の段階で、研究手法、臨床的事項、介入、アウトカムが類似していることを確認します。特に、効果を修飾し得る因子が類似していることを確認します。研究数が多ければ(少なくとも5件)統計学的にそれらの因子の分布を検討することも可能です。
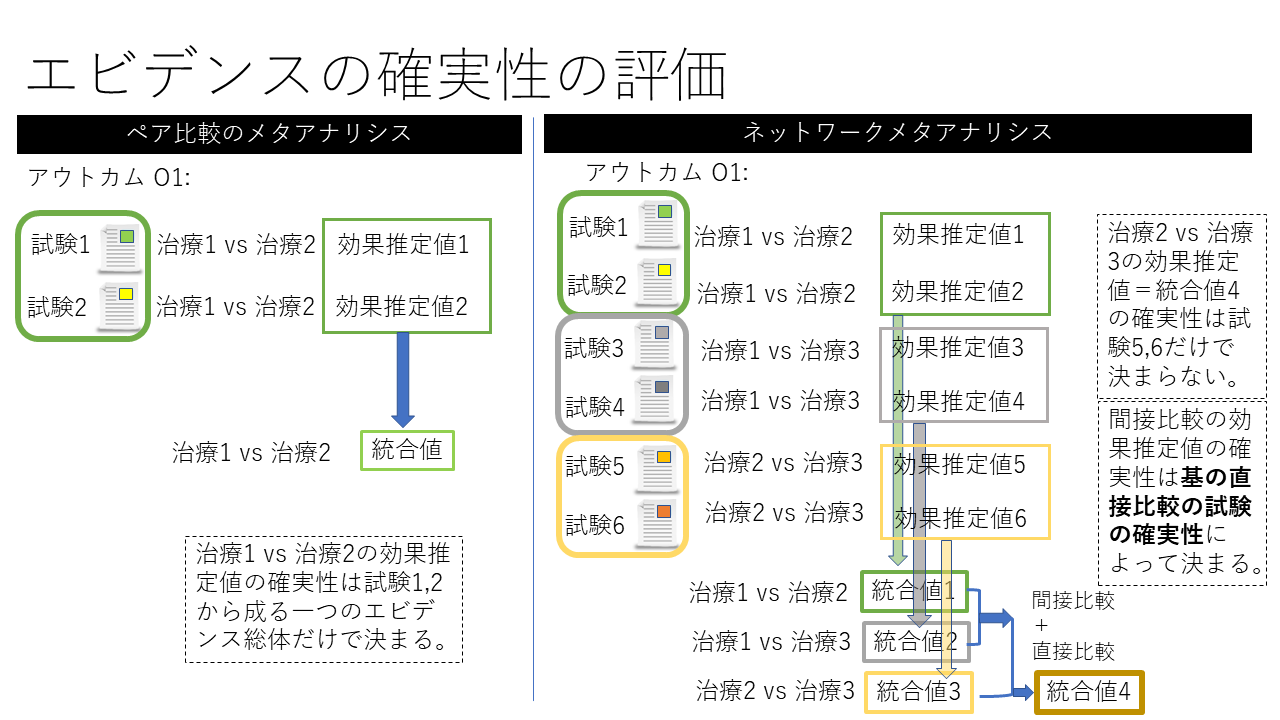
さらにコヒレンスが保たれていることもネットワークメタアナリシスの前提になります。コヒレンスというのは、移行性が保たれていることを前提として、ネットワークの中のペア比較で、直接比較と間接比較の 結果が 一致していることを言います。ネットワークメタアナリシスのエビデンスの確実性の評価には コヒレンスが保たれていないこと、すなわちインコヒレンスの評価が必要になります 。インコヒレンスの評価は通常の ペア比較のメタアナリシスで行なわれることはありません。
文献 https://ebmh.bmj.com/content/ebmental/20/3/88.full.pdf
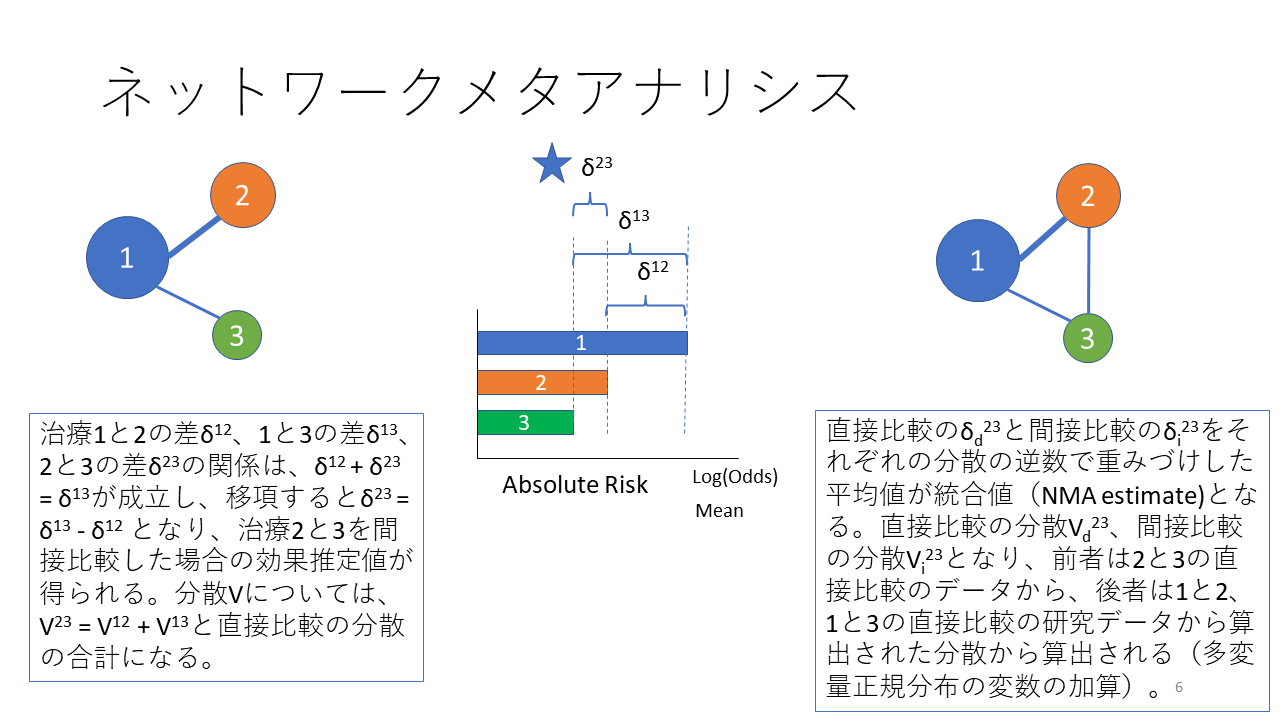
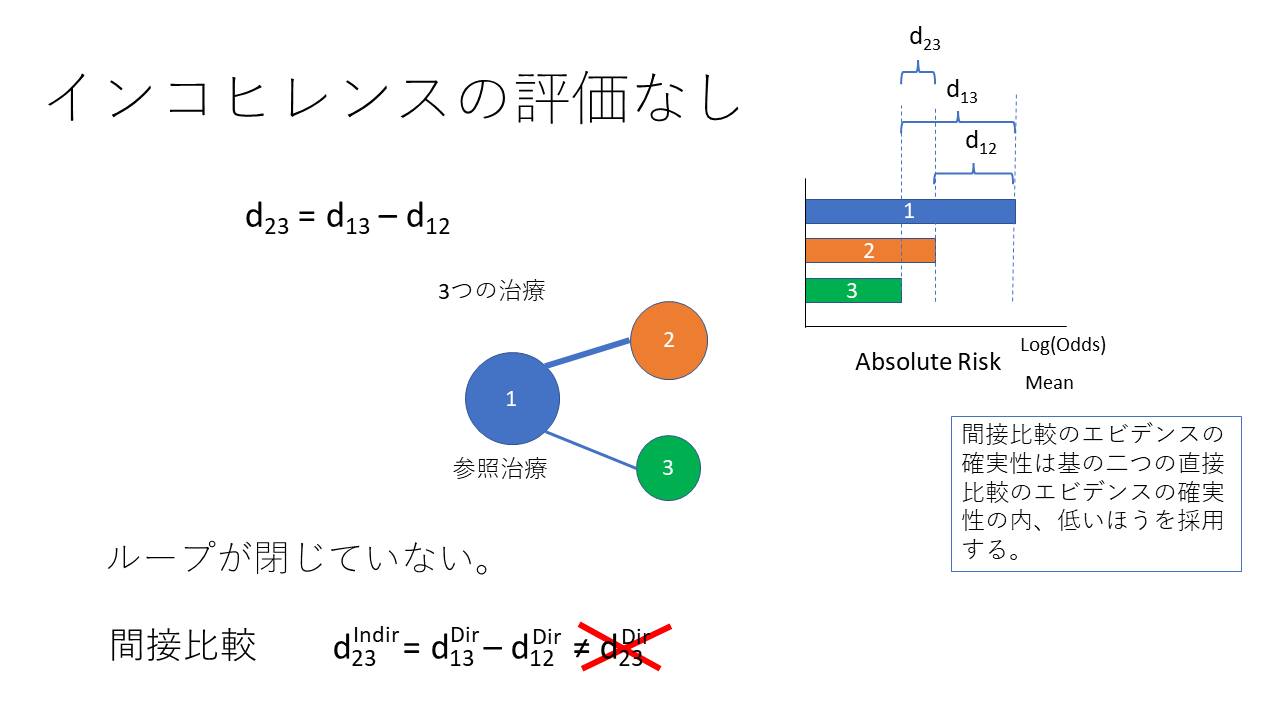
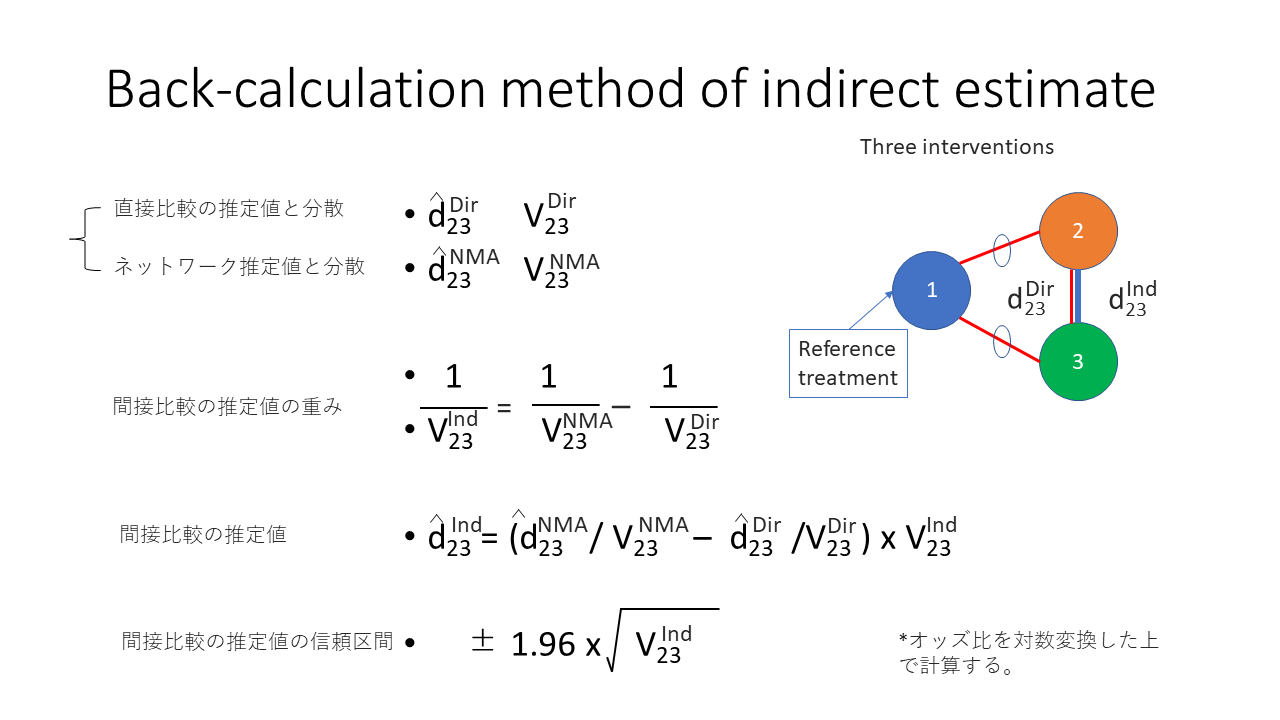
ネットワークメタアナリシスの原理を示します。例えば、左側の図に示すように、治療1と2、治療1と3を直接比較したランダム化比較試験があったとします。その場合、治療2と3を間接的に比較することが可能になります。中央のグラフで示すように、治療1と2の絶対リスク、例えばイベント率の差は、δ12で表すことができます。そして治療1と3の間の絶対リスクの差はδ13で表すことができます。中央の図に示すように、 δ13からδ12を引き算するとδ23の値が 得られます。すなわち直接比較のデータから、間接比較の データを推定することが可能になります。この間接比較のデータの分散は、治療12、治療1,3の直接比較の分散の合計した値になります。
右側のネットワークの場合には、治療2と治療3の直接比較のデータもあるので、治療13 治療12から間接的に得られた、治療23の比較のデータと直接比較のデータを、それぞれの分散の逆数で重みづけして平均値を統合値として求めます。この統合値のことを、ネットワーク推定値と呼んでいます。
ここでいう絶対リスクの差は、例えば、それぞれの治療群のオッズの自然対数の差であれば、オッズ比の自然対数になります。リスク比、ハザード比についてもそれぞれの治療群のイベント率、あるいは、ハザード率の自然対数の差です。これらの差のエクスポネンシャルを計算すると、それぞれオッズ比、リスク比、ハザード比が得られます。
ネットワークメタアナリシスの場合も、クリニカルクエスチョンに基づいて、包括的な文献検索を行ないます。比較する治療あるいは介入は3つ以上になるので、それぞれの研究は二つまたは三つ以上の介入の効果を比較した研究になります。すべての研究が、同じ疾患あるいは病態の対象者で同じアウトカムを測定しているものである、必要があります。
まず最初に、比較すべき全ての治療をリストアップします。そして、クリニカルクエスチョンで設定された対象者およびアウトカムが共通のランダム化比較試験で、その治療の効果を解析した研究を検索することになります。もし見つかった研究が、三つ以上の治療を比較した研究であって、そのうちの一つあるいは二つ以上が目的の治療でない場合は、その介入は、解析データから除いて、その研究を解析に含めます。 その上で、繋がったネットワークが出来た場合には、そこで検索を終了します。
それぞれの治療を、ORで結合した検索式を用いることになりますが、検索結果で得られた研究で、繋がったネットワークができない場合もあり得ます。もし、最初にリストアップした治療では、ネットワークができない場合には、さらに別の治療を追加して、文献検索を進め、より拡大した治療比較のセットについて 、同様に文献検索を行い、つながったネットワークができて来る場合もあります。そのように検索範囲を拡大するかどうかは、臨床的な観点からの検討も必要になり、ペア比較のメタアナリシスだけを前提とする場合と、検索戦略が異なってきます。
ここでは当該クリニカルクエスチョンに対応する研究の集合をエビデンスベースとよんでいます。
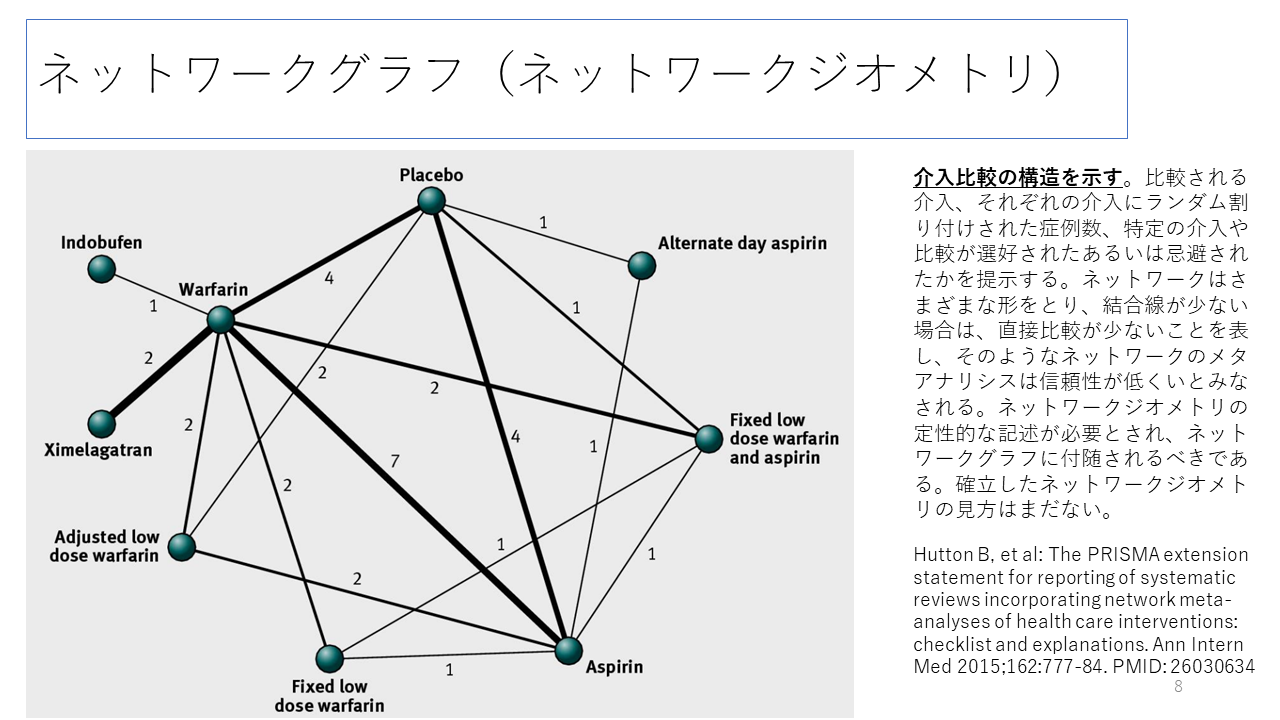
この図はネットワークグラフあるいはネットワークジオメトリーなどと呼ばれ、各ノードが治療法、それらを結んだ実線は直接比較、線の太さは研究の数を表しており、この例では、その線上に研究数が示されています。結合線が少ない場合には、直接比較が少ないことを表し、ネットワーク全体としては、ネットワークメタアナリシスの結果の信頼性が低いとみなされます。ネットワークグラフについて、それを解説する、定性的な記述をつけることが望ましいとされています。
Quiz
それぞれの研究から、メタアナリシスに必要なデータすなわち症例数とイベント数、あるいは症例数と平均値、標準偏差、ハザード比と標準誤差などの データを抽出し、それらを解析することで、ネットワークメタアナリシスのさまざまな結果が、アウトプットとして得られます 。
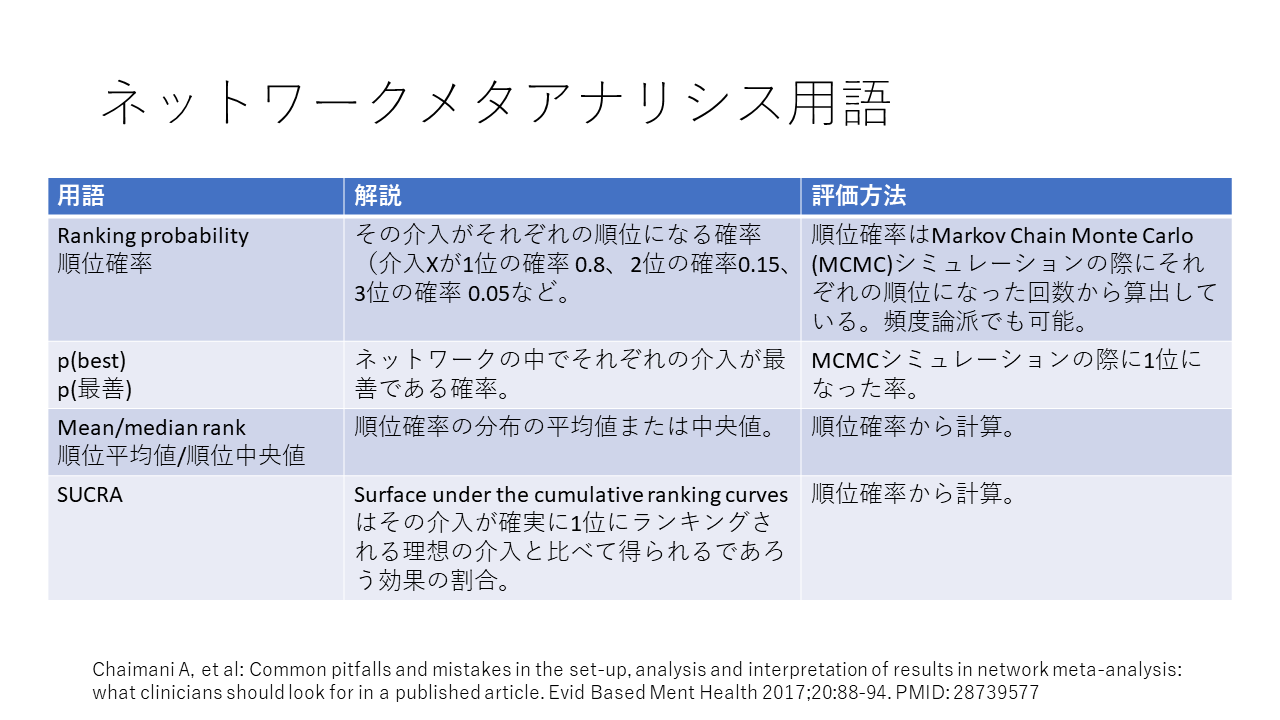
Cochrane Handbook for Systematic Reviews of Interventions version 6.3によると、ネットワークメタアナリシスのアウトプットとして、ここにリストアップした情報が得られます。これらのうち、ネットワークグラフ、フォレストプロット、ランコグラム、SUCRA (Surface Under the Cumulative Ranking Curve)が重要です。
また、ここには含まれていませんが、直接比較と間接比較の推定値と95%確信区間あるいは信頼区間、および、ネットワーク推定値とその95%確信区間あるいは信頼区間、さらに直接比較と間接比較の有意差検定の結果を表形式あるいはグラフ表示したデータはインコヒレンスの評価に有用です。
なお、ベイジアンアプローチを用いた場合は、95%確信区間 Credible Interval、頻度論派アプローチを用いた場合は、95%信頼区間Confidence Intervalという用語が用いられます。
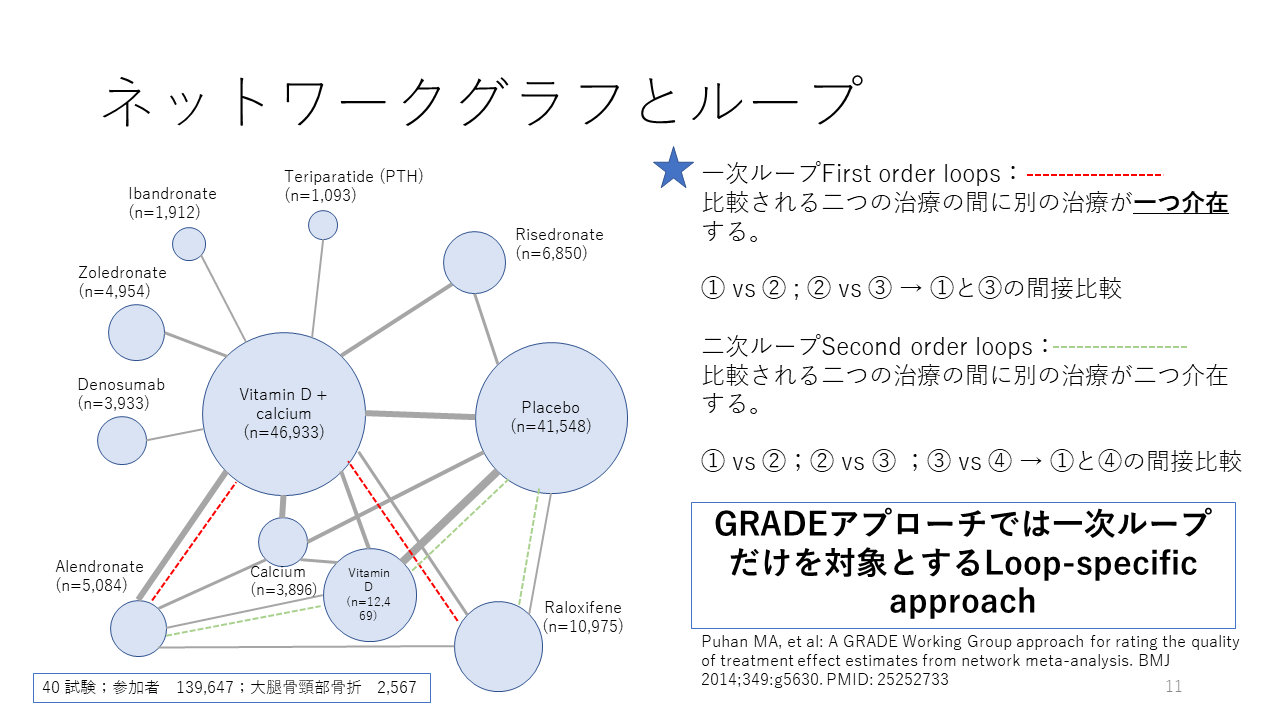
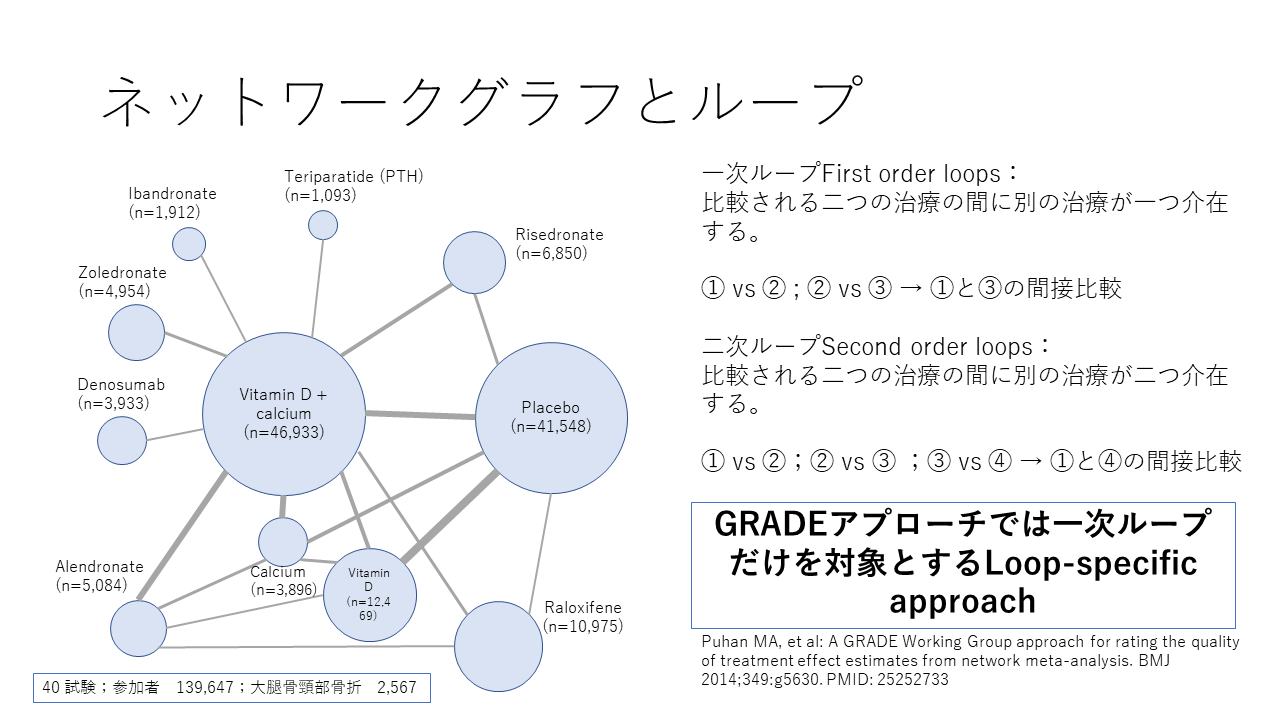
これは、骨粗鬆症の患者さんが対象で、大腿骨頚部骨折をアウトカムとした、11種類の治療法のネットワークグラフの例です。結合線は直接比較(head-to-head comparison)を示しますが、間接比較される二つの治療の間に別の治療が一つ介在する場合は一次ループと呼び、間接比較される二つの治療の間に別の治療が二つ介在する場合は二次ループと呼びます。 赤の点線は一次ループの例で、緑の点線が二次ループの例です。
GRADEアプローチでは、原則として、一次ループだけをエビデンス評価の対象とすることになっています。すなわち、エビデンスの確実性の評価の対象は、一次ループまでとなっています。エビデンス評価の対象になる場合は、間接比較のみの場合と直接比較と間接比較の両方ある場合とがあります。後者は、直接比較と間接比較の間の不一致、すなわちインコヒレンスの程度の評価が必要になります。
結合線の太さは研究数を表します。また、このネットワークグラフの例ではノードの大きさが症例数を表しています。
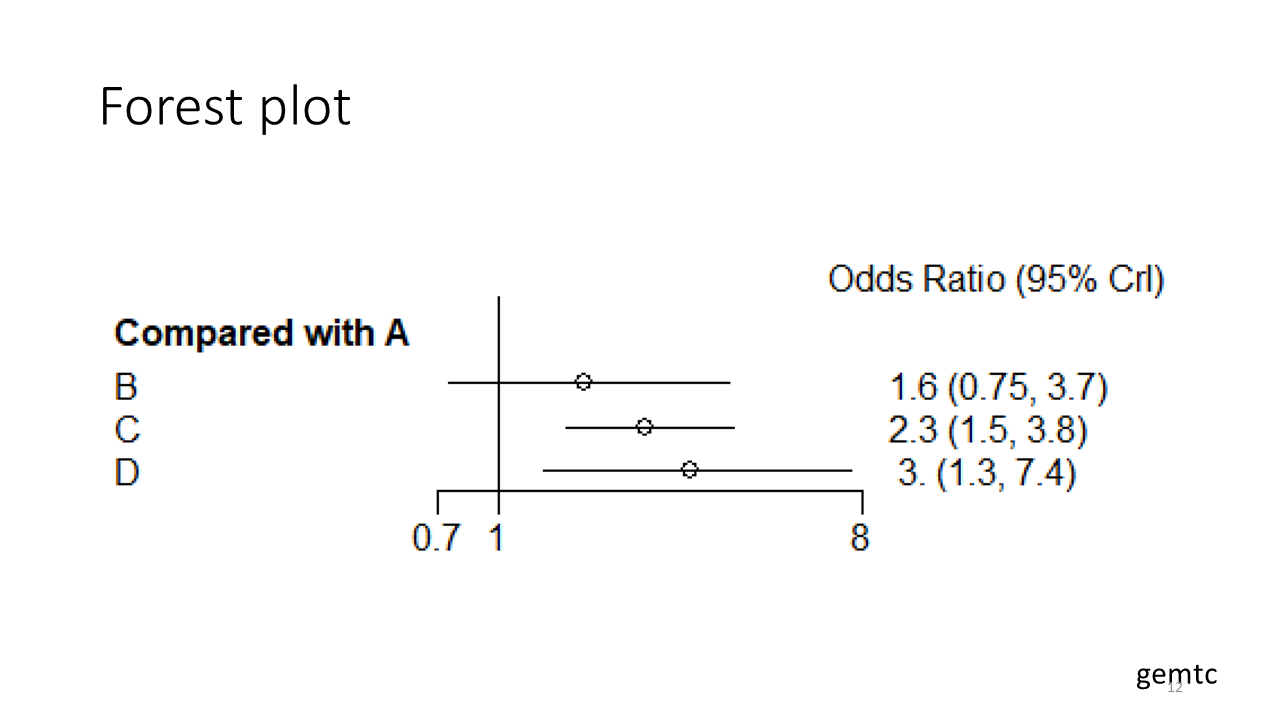
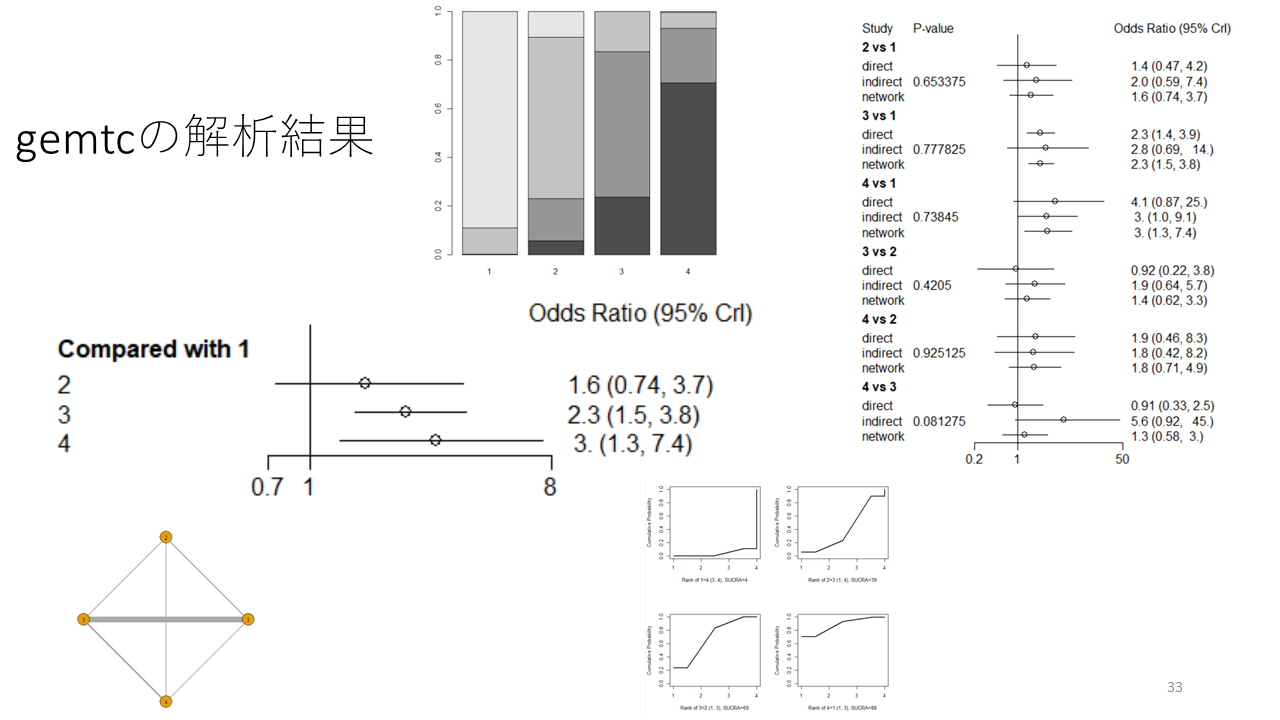
これは、ABCD、四つの治療を比較したネットワークメタアナリシスのフォレストプロットの例です。治療Aを対照として、BCDに対するオッズ比と95%確信区間をグラフ表示しています。
通常のペア比較のメタアナリシスの場合は、点推定値と95%確信区間あるいは信頼区間のバーは、一つの研究の効果指標の値に対応していますが、ネットワークメタアナリシスの場合は、複数の研究の統合値とその確信区間あるいは信頼区間を表しています。統合値は間接比較の場合の値と、直接比較の場合と、それらを統合した“ネットワーク推定値”(あるいはネットワークメタアナリシス推定値)です。
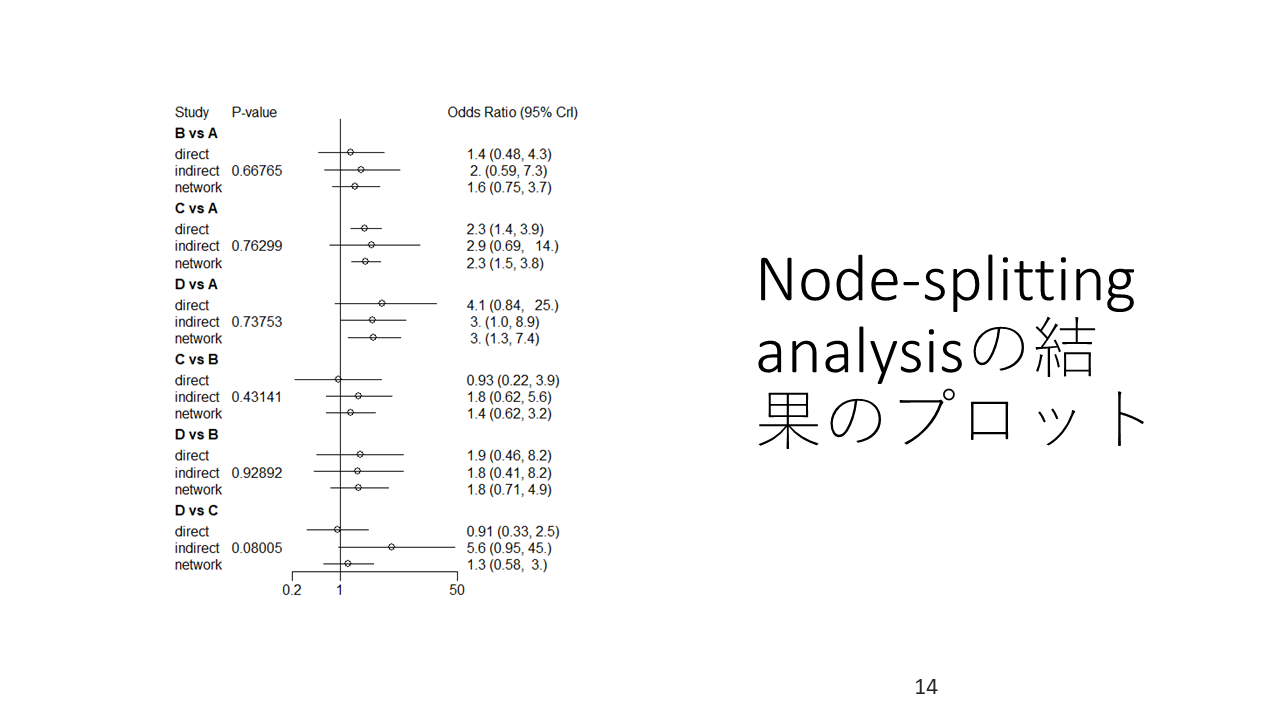
直接比較と間接比較の両方の推定値が得られる場合、例えば、この図で治療2と治療3の比較のような場合、両方を統合したネットワーク推定値network estimateだけでなく、直接比較の推定値と間接比較の推定値、全部で3種類の推定値を算出することができます。それを自動的に、直接比較と間接比較のデータが得られるすべてのペアについて算出する方法が結節分割法Node-splitting methodです。
Rのパッケージgemtcでは、この方法を実行し、結果のグラフ表示、直接比較と間接比較の有意差検定の結果も得られるので、それをインコヒレンスの評価に用いることができます。
これはNode-splitting analysisの結果をグラフ表示したものです。それぞれのペア比較に対して、直接比較、間接比較それぞれの統合値、ネットワーク推定値とそれらの95%確信区間が 示されています。
さらに、直接比較と間接比較のそれぞれの統合値の有意差検定のP値が示されています。
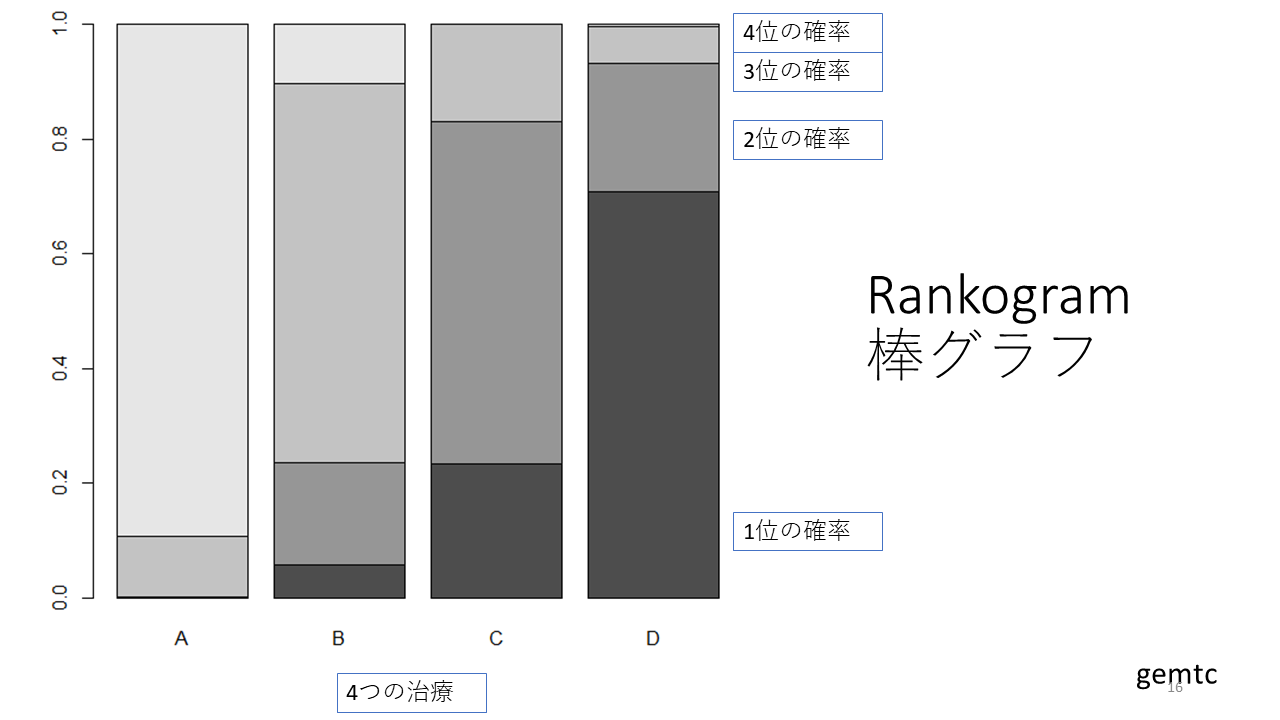
ネットワークメタアナリシスでは、それぞれの治療がそれぞれの順位になる確率が計算されます。例えば、ここに示す例では、治療Dの効果の大きさが1位になる確率0.7、水平方向に見て、2位になる確率が0.22、3位になる確率が0.06、4位になる確率が0.004です。
また、垂直方向に見ると、例えば、1位になる確率は高い順に、治療D、C、B、Aであることが分かります。
これら順位確率の値をグラフ化したものとして、ランコグラムとSUCRAがあります。
これはランコグラムですが、それぞれの治療がそれぞれの順位になる確率を積み上げ棒グラフの形で表したものです。1位の確率は黒で 表されており、1位になる確率が最も高いのは治療Dであることがわかります。 一方、治療Aは、4位になる確率が最も高いことがわかります。なお、ランコグラムは、このような積み重ね棒グラフだけでなく、折れ線グラフとすることもできます。
また、1位か2位のどちらかになる確率を見てみると、治療CとDは大きな差が無いことが分かります。もし、1位の治療Dと2位の治療Cの効果の大きさがわずかの場合は、1位の確率が一番高い、治療Dを用いても、2位の確率が一番高い治療Cを用いても、アウトカムに大きな差がないことが推定されます。
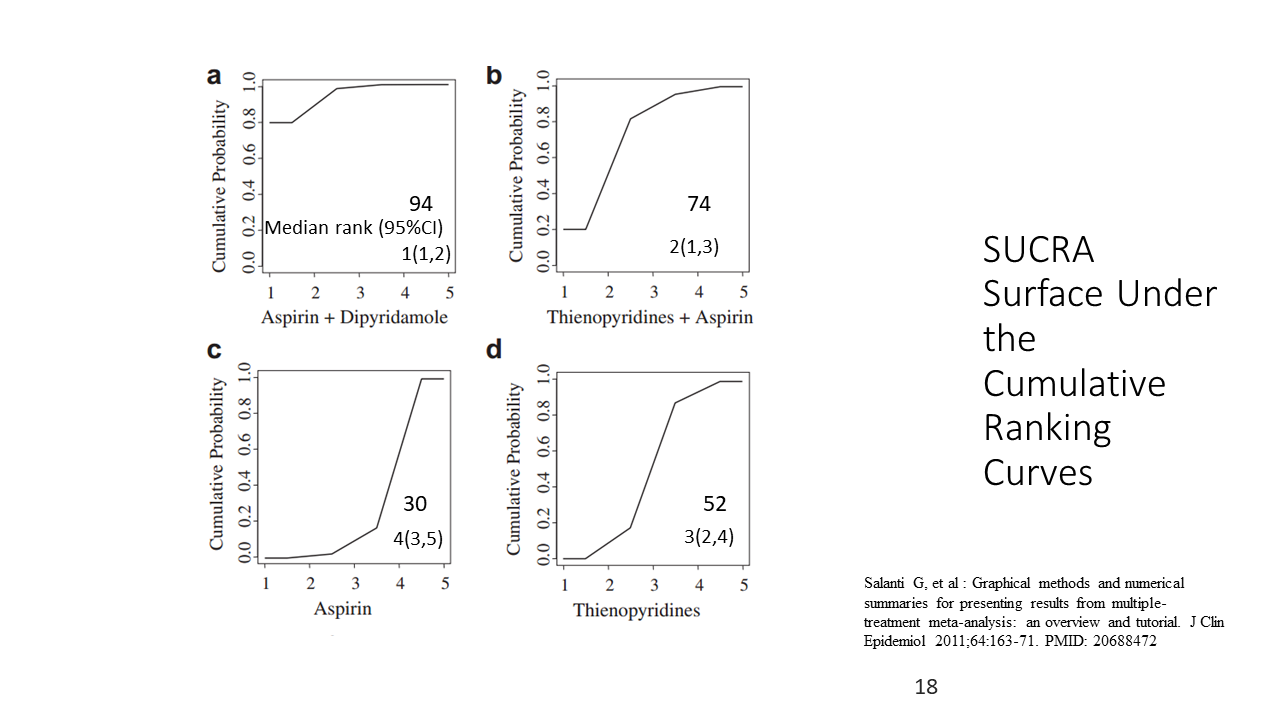
これは4つの治療を比較した別の例ですが、順位確率の値から、順位の中央値と95%信頼区間(または確信区間)を算出しています。
SUCRAも、ネットワークメタアナリシスの結果について治療効果の順位を表す一つの指標です。累積順位曲線下面積という意味になります。それぞれの治療について累積順位確率を縦軸に、順位を横軸にして描かれる曲線で、治療の効果の大きさの順位付けに、曲線下の面積を用います。
SUCRAの値は、最下位の順位をKとした場合、(K-順位の値)を順位確率で重みづけして、合計値を求め、最大値が100、最小値が0になるように標準化した値に相当します。つまり、1位の値に最大値を設定し、等間隔でそれより小さな値を設定し、それらを順位確率で重みづけして、合計値を求め、最大値が100、最小値が0になるように標準化した値であれば、どのような最大値を設定しても同じ結果が得られます。
順位の値は絶対効果の値そのものではなく、その順位です。したがって、SUCRAの値も順位の判断に用いることは問題ありませんが、1位と2位の絶対効果の大きさの差と、2位と3位の絶対効果の差は同じとは限りません。また、1位の治療と2位の治療の絶対効果の差がわずかしかない場合もあり得ます。
さらに、一つのアウトカムに対する効果の大きさの順位なので、他のアウトカム、特に害のアウトカムに対する効果の大きさを考慮する場合は、絶対効果で評価しないと誤った結論を出す可能性があります。
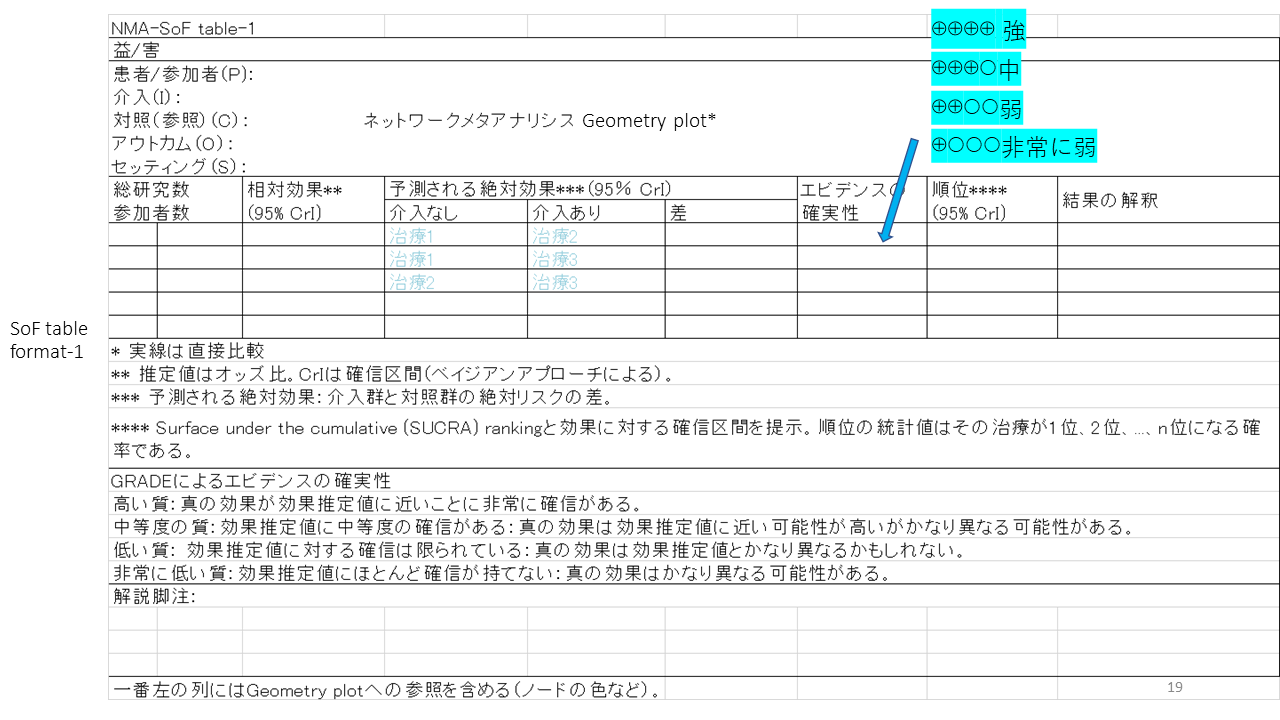
ネットワークメタアナリシスの結果に基づく、SoFテーブル(Summary of Findings Table)には2種類のフォーマットが 提案されています。これはその一つですが 一行に一つのペア比較の結果を記述するように構成されています。比較する 治療の数が多い場合にはこの形式のほうがまとめやすいでしょう。
各行の一番左側に、ネットワークグラフの対応するノードの色などを提示すると、ネットワークグラフとの関係がわかりやすくなります。
各ペアの、介入なし、介入ありの欄に、それぞれペア比較される治療の名称を記入します。
クリニカルクエスチョンを記述する欄に、ネットワーク グラフ(ネットワークメタアナリシスGeometry plot)を提示するようになっています。また、順位と95%確信区間、SUCRAの値を記入するようになっています。
効果推定値はオッズ比などの相対効果の指標と各群の絶対リスクとその群間の差、すなわち絶対効果の大きさを記入するようになっています。
通常のSoFテーブルには無い項目として、順位と95%確信区間およびSUCRA値があります。
絶対効果の大きさは、ベースラインリスクの値を疾患レジストリなどから得て、オッズ比、リスク比、ハザード比から計算することも可能ですし、ベースラインリスクに、高・中・低などあり得る推定値を設定して、計算する場合もあります。
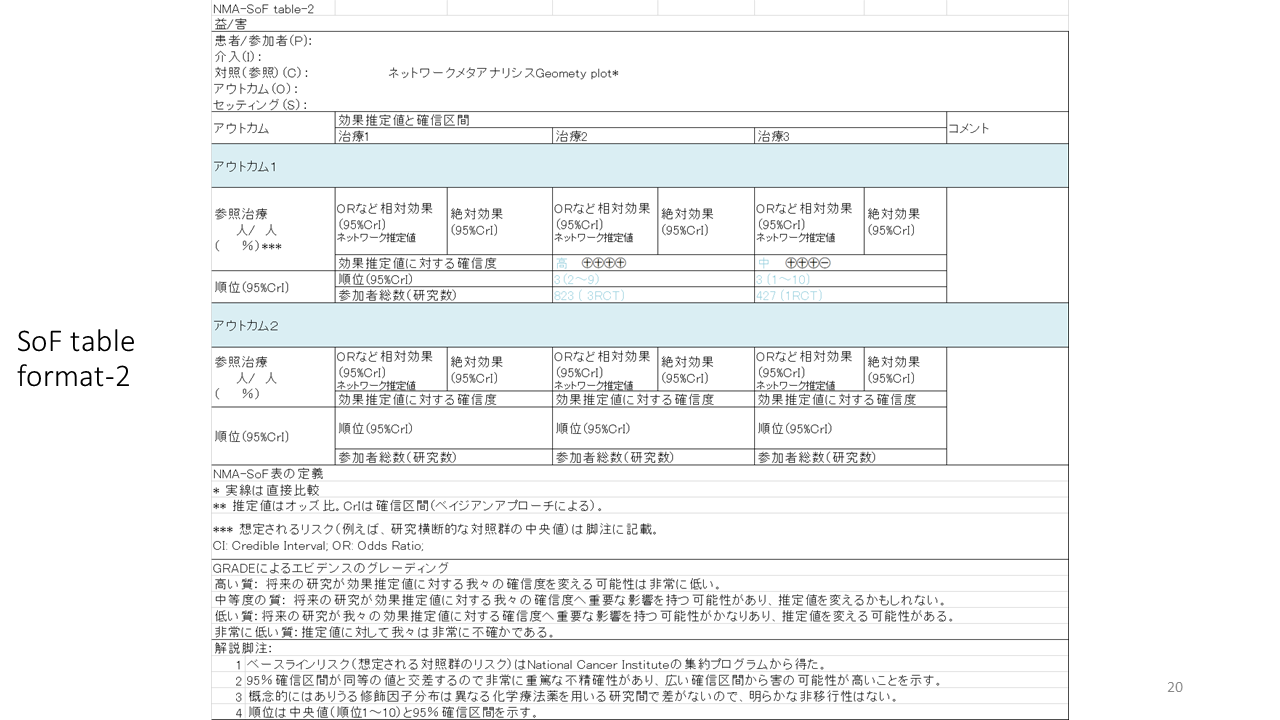
SoFテーブルの、もう一つのフォーマットがこちらです。このフォーマットは比較する治療の数が少ない場合に使うことができます。一つの行に比較される治療のそれぞれの効果推定値を記入するようになっています。複数のアウトカムに対する効果を一覧しやすいことが利点です。
以上2つのフォーマットのいずれも、ネットワーク推定値を記入するようになっていますが、間接比較、直接比較だけの場合は、その旨を記述する必要があるでしょう。
Quiz
ネットワークメタアナリシスのエビデンス評価のGRADEアプローチについて解説します。
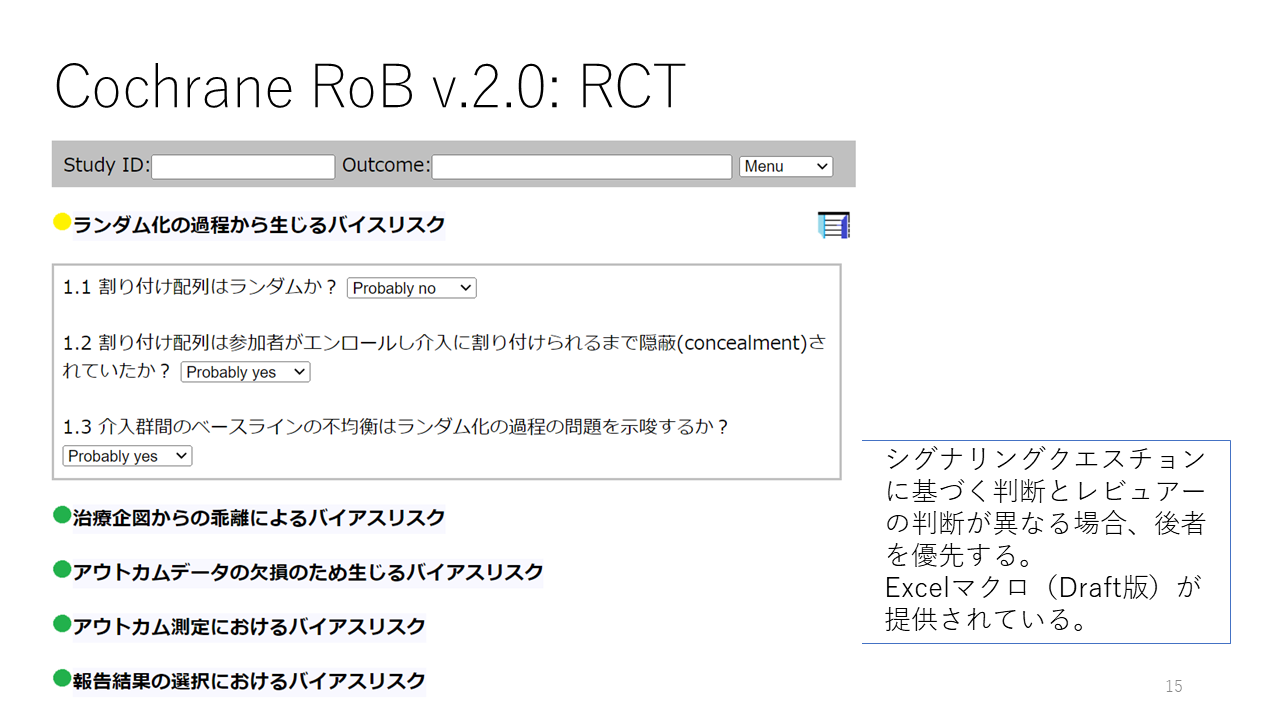
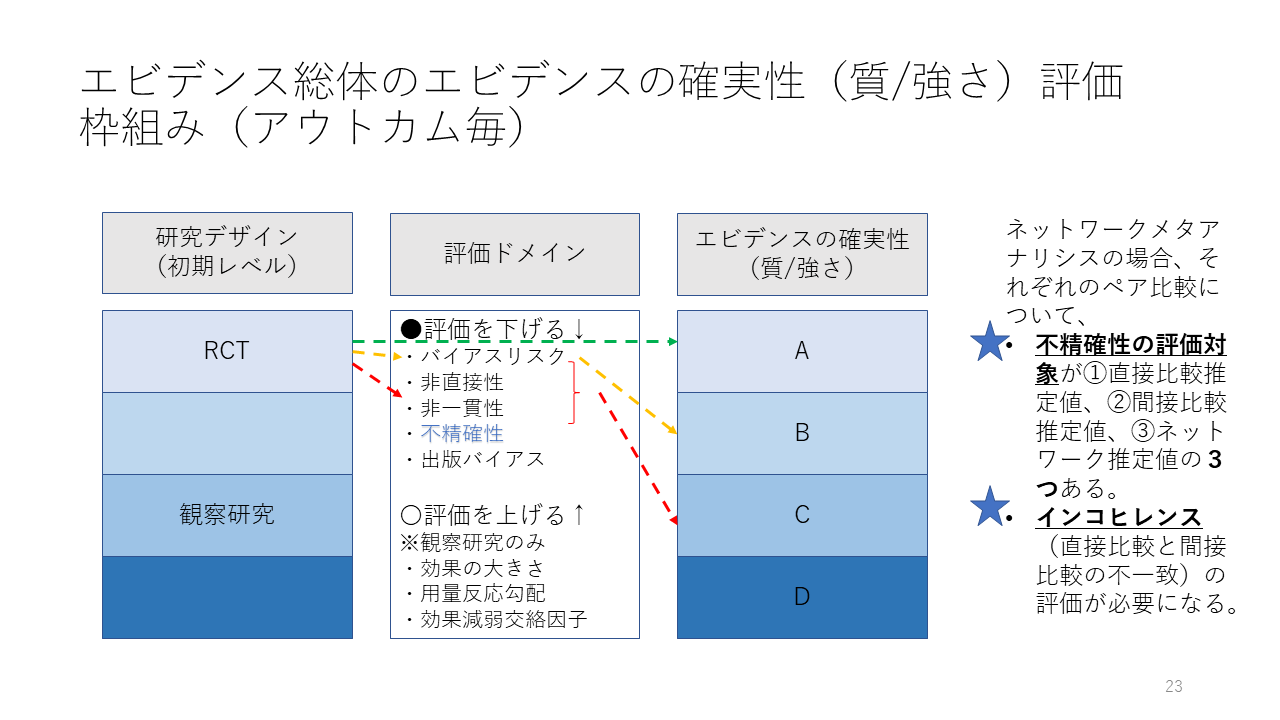
ランダム化比較試験の場合、複数の研究をまとめたエビデンス総体の評価ドメインは、バイアスリスク、非直接性、非一貫性、不精確性、出版バイアスの5ドメインですが、ネットワークメタアナリシスの場合は、それぞれのペア比較について不精確性の評価対象が、直接比較推定値、間接比較推定値、ネットワーク推定値の3つになります。そして直接比較と間接比較の不一致、すなわちインコヒレンスの評価が必要になってきます。
ネットワークメタアナリシスに対するGRADEアプローチは4つのステップからなっています。まず、直接比較と間接比較の効果推定値をそれぞれ提示します。二番目に 直接比較と間接比較の効果推定値の質をレーティングします。三番目に エビデンスネットワークのそれぞれの比較についてネットワークメタアナリシス効果推定値(ネットワーク推定値)を提示します。四番目にそれぞれのネットワーク推定値の質をレーティングします。
Puhan MA, et al: A GRADE Working Group approach for rating the quality of treatment effect estimates from network meta-analysis. BMJ 2014;349:g5630. PMID: 25252733 https://www.bmj.com/content/349/bmj.g5630
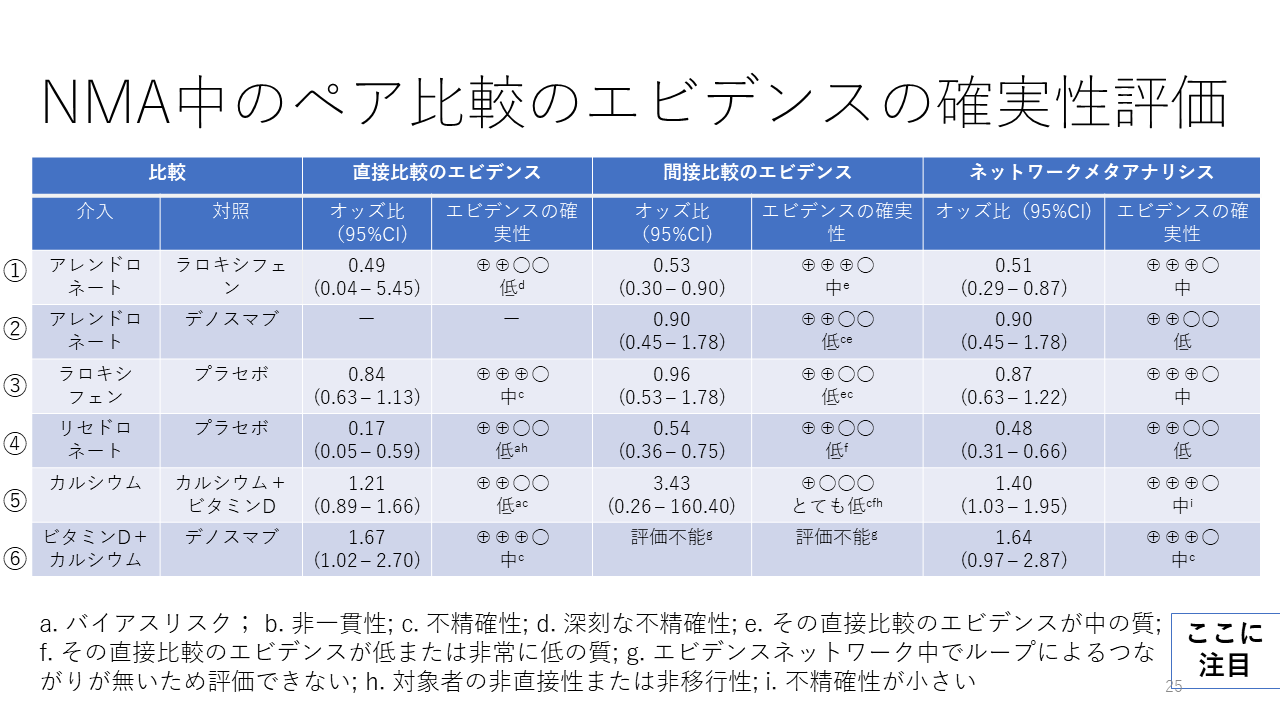
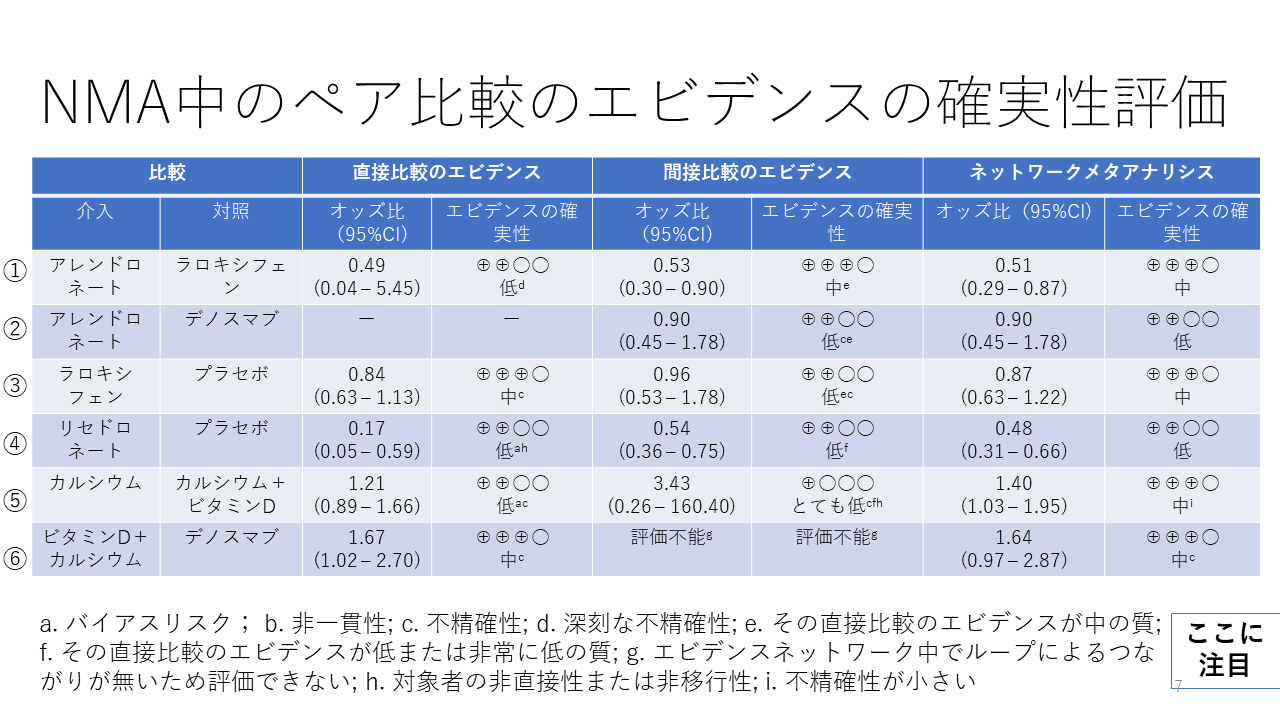
ネットワークメタアナリシス中のペア比較のエビデンスの確実性の評価のひとつの例を示します。
比較①は、直接比較のエビデンスの確実性が低、ABCDのCの評価です。コメントdの意味は、“深刻な不精確性”となっています。すなわち、オッズ比の95%確信区間が1をはさんで、しかも0.04から5.45と幅広くなっているため“深刻”と判定したと考えられます。この低の評価は、エビデンス総体の評価なので、おそらく、“深刻な不精確性”とそれ以外のドメイン、例えば、バイアスリスクが“深刻”との判断があって、Aから2段階レートダウンして、低(C)になったのだろうと考えられます。
比較①の間接比較のエビデンスの確実性は中(B)となっており、コメントeは、“その直接比較のエビデンスが中の質”となっています。ここでいう、その直接比較というのは、上述した直接比較のエビデンスのことではなく、この間接比較の元になった直接比較の意味です。それが、バイアスリスク、非直接性、非一貫性、出版バイアスのいずれか、あるいは、非移行性に深刻な問題があると判定したため、AからBへレートダウンしたと考えられます。不精確性は“深刻でない“と判定したと考えられます。
比較①のネットワークメタアナリシスのエビデンスの確実性は、中(B)となっています。コメントは特に付けられていません。ここでは、直接比較と間接比較の効果推定値の点推定値、すなわちオッズ比は0.49と0.53で、ほぼ同じであり、95%確信区間も重なっているので、インコヒレンスは“深刻でない“と判定され、ネットワーク推定値の95%信頼区間が0.29~0.87で1を十分下回っているため、不精確性も深刻でないと判定され、間接比較の貢献度が直接比較の貢献度より大きい(信頼区間の幅から間接比較の重みが大きいと考えられた)ので、間接比較のエビデンスの確実性をネットワーク推定値のエビデンスの確実性に設定したと考えられます。
比較②は直接比較のエビデンスがない場合です。
Puhan MA, et al: A GRADE Working Group approach for rating the quality of treatment effect estimates from network meta-analysis. BMJ 2014;349:g5630. PMID: 25252733より一部抜粋翻訳(Table 1)。 https://www.bmj.com/content/349/bmj.g5630
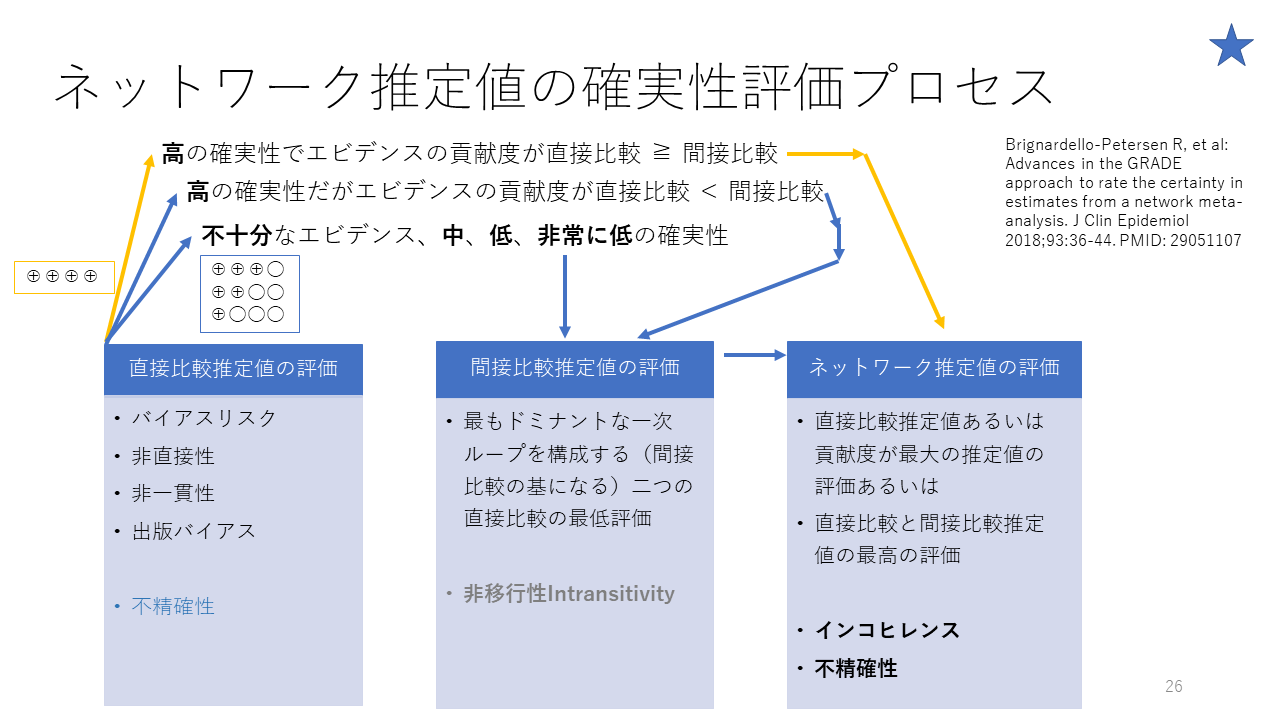
GRADE working groupが提言している、ネットワークメタアナリシスで得られるネットワーク推定値の、エビデンスの確実性の評価の、より詳細な手順を示します。
一つの例を説明すると、比較するペアに直接比較のデータがある場合、そのエビデンスの確実性が高であれば、ネットワーク推定値のエビデンス評価を行いますが、直接比較の貢献度が大ききければそのエビデンスの確実性をネットワーク推定値のエビデンスの確実性とします。もし、直接比較と間接比較の貢献度が同じ場合は、高い方のエビデンスの確実性をネットワーク推定値のエビデンスの確実性とします。その際にインコヒレンスとネットワーク推定値の不精確性を考慮し、これらが深刻な場合は、レートダウンすることを考慮します。
もう一つの例として、間接比較しかない場合、直接比較の不十分なエビデンスに該当するとみなし、間接比較推定値の評価へ進みます。二つの直接比較のエビデンスの確実性の低い方を採用して、非移行性も評価し、ネットワーク推定値の評価へと進みます。そこで、不精確性を考慮し、これらが深刻な場合は、レートダウンすることを考慮します。
Brignardello-Petersen R, et al: Advances in the GRADE approach to rate the certainty in estimates from a network meta-analysis. J Clin Epidemiol 2018;93:36-44. PMID: 29051107 https://pubmed.ncbi.nlm.nih.gov/29051107/
同じ疾患の患者さんを対象にし、同じ介入の効果を調べた研究でも、まったく同じ効果推定値が得られることはありません。研究結果は、偶然による偏りに加え、バイアス、非直接性の影響を受けています。複数の研究の間で、偶然によるばらつき以上の、異なる効果推定値が得られた場合、研究間に異質性Heterogeneityがあると考えられます。
インコヒレンスは異質性に含まれますが、直接比較と間接比較の効果修飾因子(研究デザイン、研究実施、バイアス、非直接性など)の分布の違いによって生じる効果の違いに限定して用います。通常のペア比較のメタアナリシスでは問題になることはありませんが、ネットワークメタアナリシスは間接比較のデータと直接比較のデータの両方を用いるため、それらが乖離する場合が起きうることになり、効果推定値の確実性に影響を及ぼす因子になります。
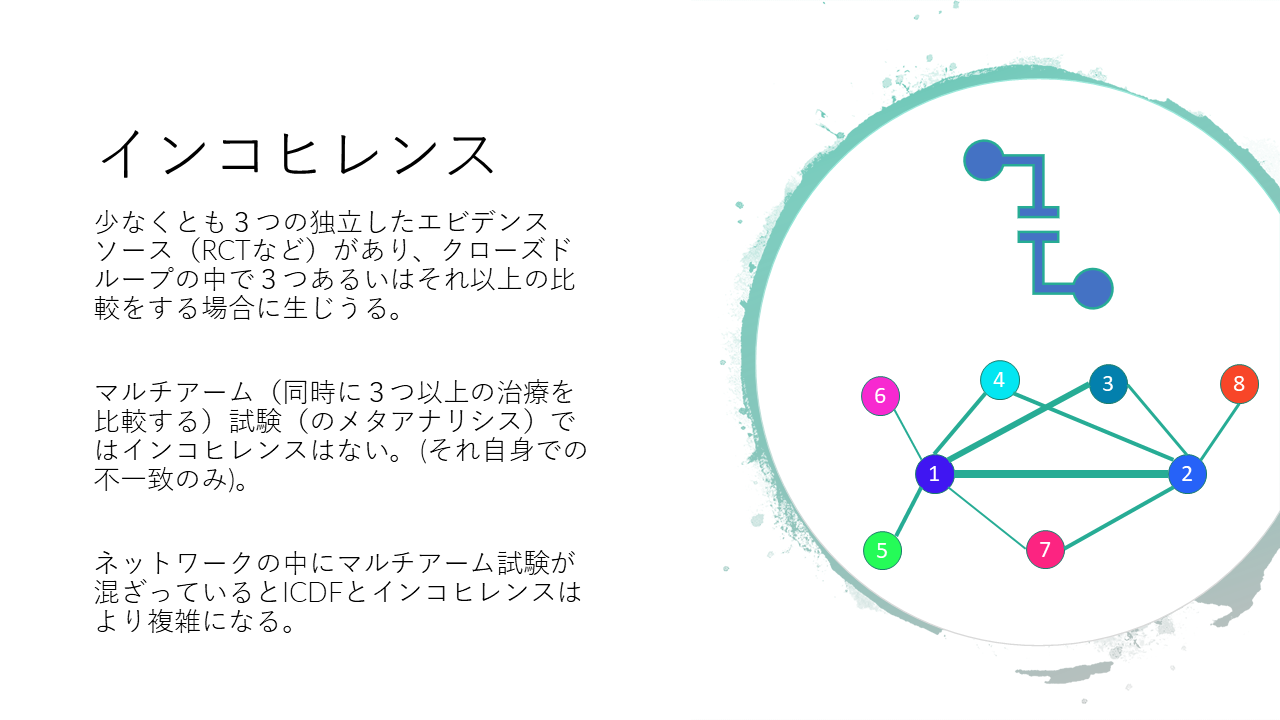
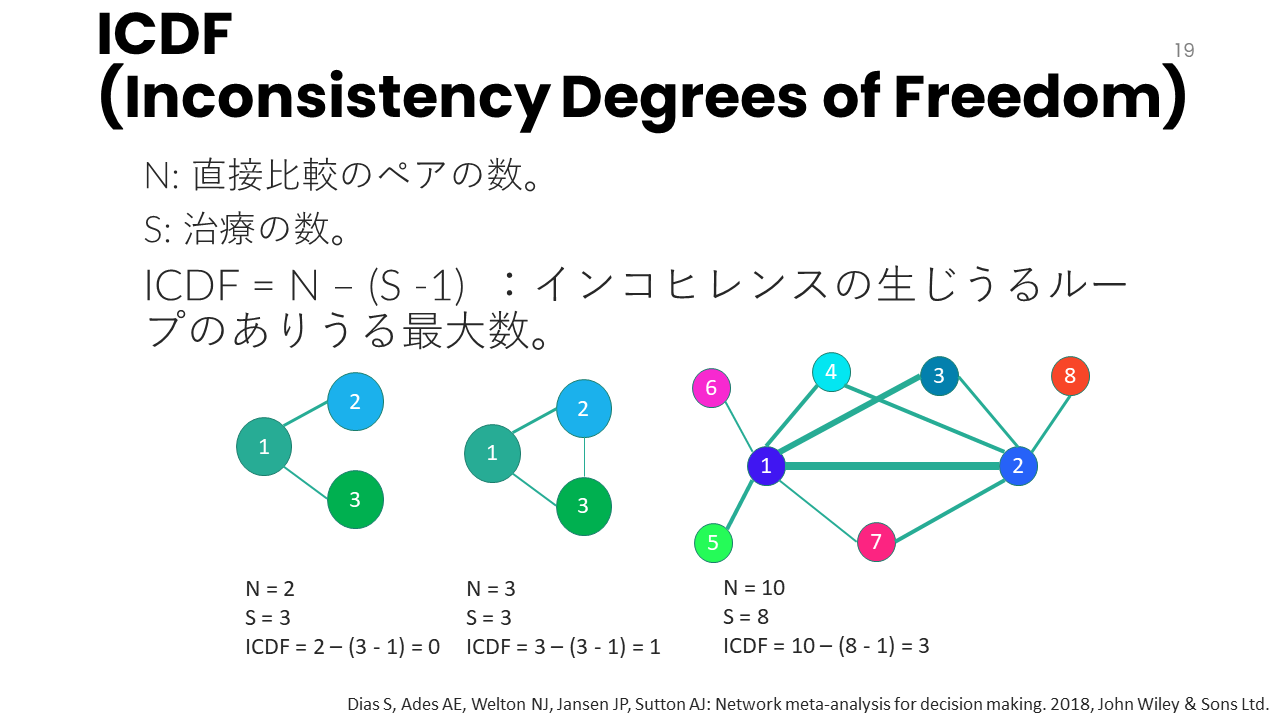
インコヒレンスはネットワークのクローズループ内で比較を構成する3つ以上の独立したエビデンスソースがないと評価できません。
インコヒレンスは、少なくとも3つの独立したエビデンスソース(RCTなど)があり、クローズドループの中で3つあるいはそれ以上の比較をする場合に生じる可能性があります。
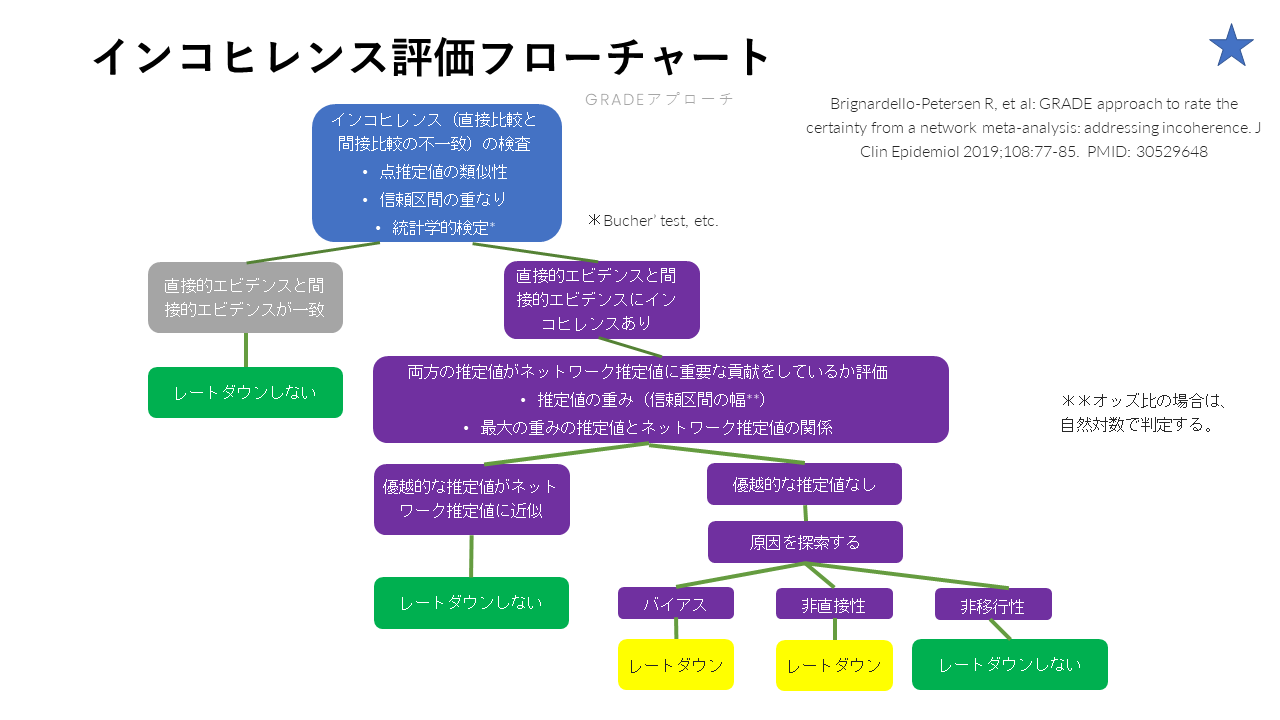
これは、GRADE working groupが提唱している、インコヒレンスの評価フローチャートです。
まず、直接比較と間接比較の効果推定値の点推定値が類似しているか、信頼区間が重なっているか、そしてブッチャーの検定などの 統計学的検定の結果から、インコヒレンスの有無を判定します。インコヒレンスがないと判断した場合には、レートダウンはしません。
もしインコヒレンスがあると判断した場合には、間接比較と直接比較の効果推定値のそれぞれの信頼区間の幅から、推定値の重みを 判断し、最大の重みの推定値とネットワーク推定値の関係をみます。重みの大きな推定値とネットワーク推定値が近似している場合にはレートダウンする必要はありません。ネットワーク推定値をほぼ決定付けているような 優越的な推定値がなかった場合には、そのインコヒレンスの原因を探索し、バイアスあるいは非直接性の影響と判断した場合には、レートダウンします。もし非移行性が原因と考えられた場合には、通常レートダウンをしません。
Brignardello-Petersen R, et al: GRADE approach to rate the certainty from a network meta-analysis: addressing incoherence. J Clin Epidemiol 2019;108:77-85. PMID: 30529648 https://pubmed.ncbi.nlm.nih.gov/30529648/
Quiz
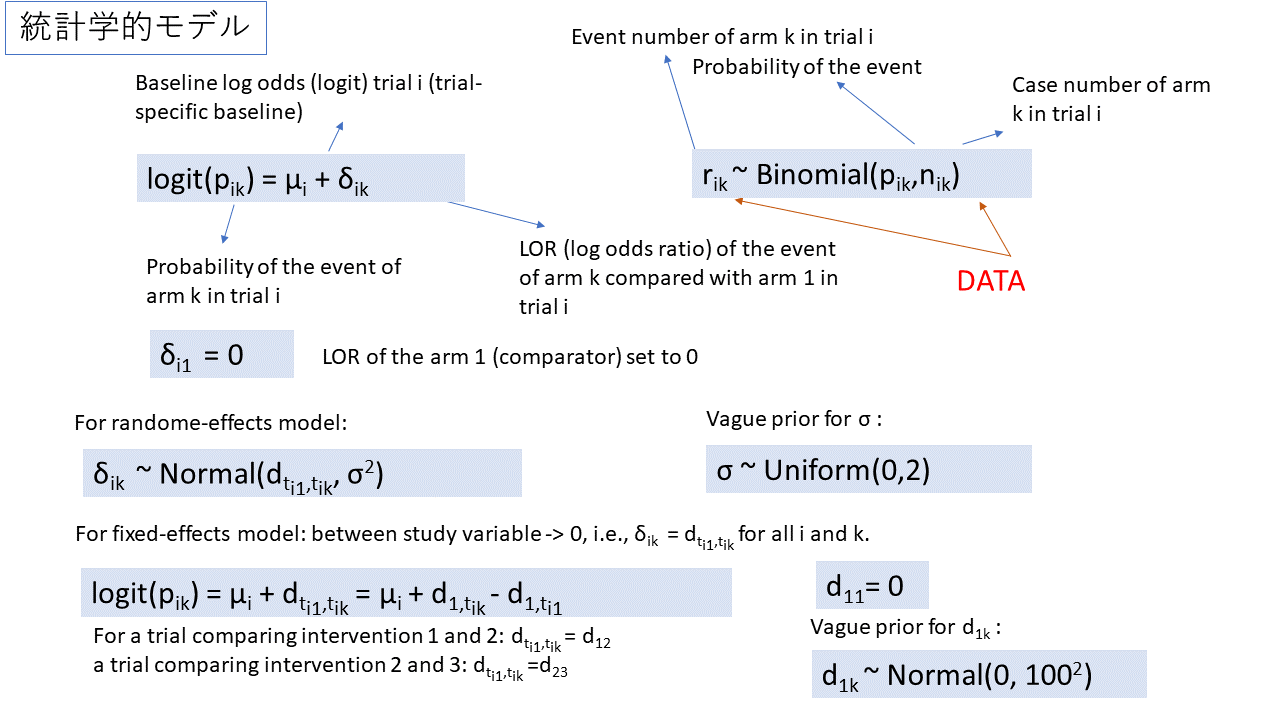
ネットワークメタアナリシスを実行するためのソフトウェアには、ベイジアンアプローチを用いるもの、頻度論派のアプローチを用いるものとがあります。ベイジアンアプローチの場合には、OpenBUGS、あるいは、RからBRugsなどを介してOpenBUGS動かす方法を用いることが一般的です。特に gemtcは、Rでrjagsを介してJAGSを動かして、ベイジアンアプローチによるContrast-based modelによるネットワークメタアナリシス解析を行う ソフトウェアです。また、pcnetmetaはベイジアンアプローチによるArm-based modelによるネットワークメタアナリシスを、Rからrjagsを介してJAGSを動かして、実行します。
頻度論派のアプローチを用いるソフトウェアとしてnetmetaが広く用いられています。
ここでは、gemtcで禁煙治療のサンプルデータを用いて、ベイジアンアプローチによるContrast-based modelによるネットワークメタアナリシス解析を実際にデモでお見せします。
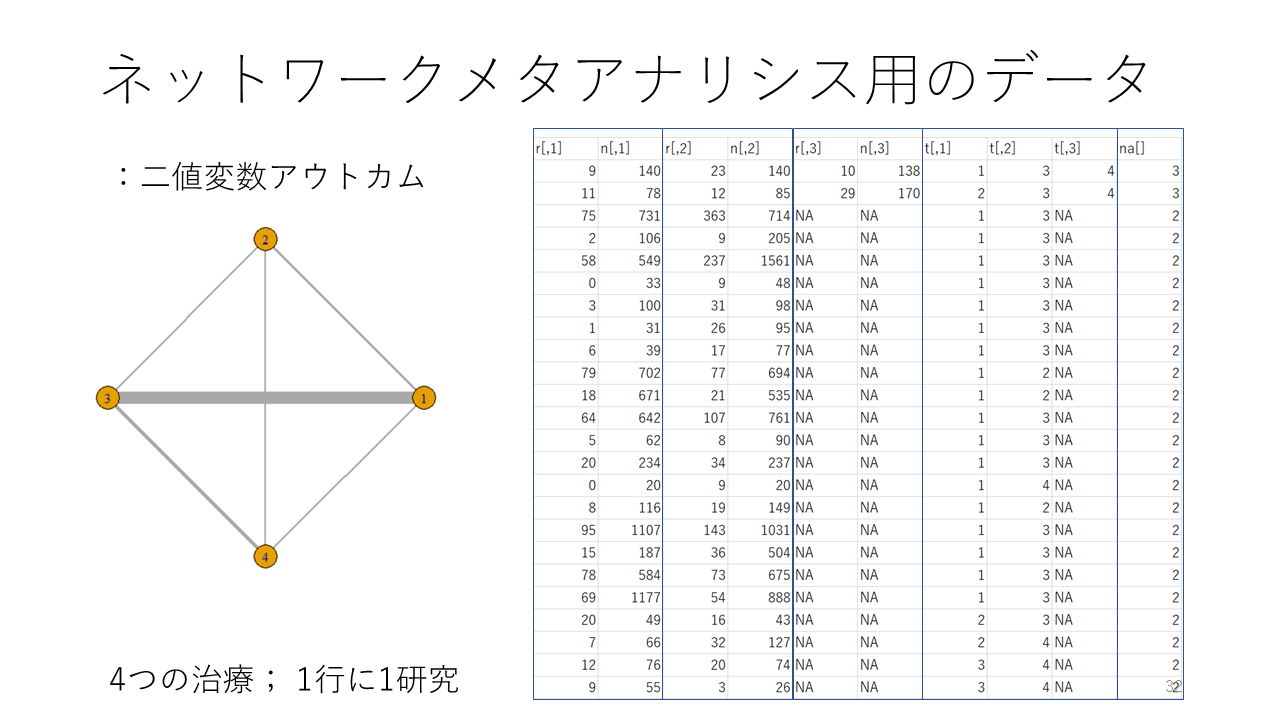
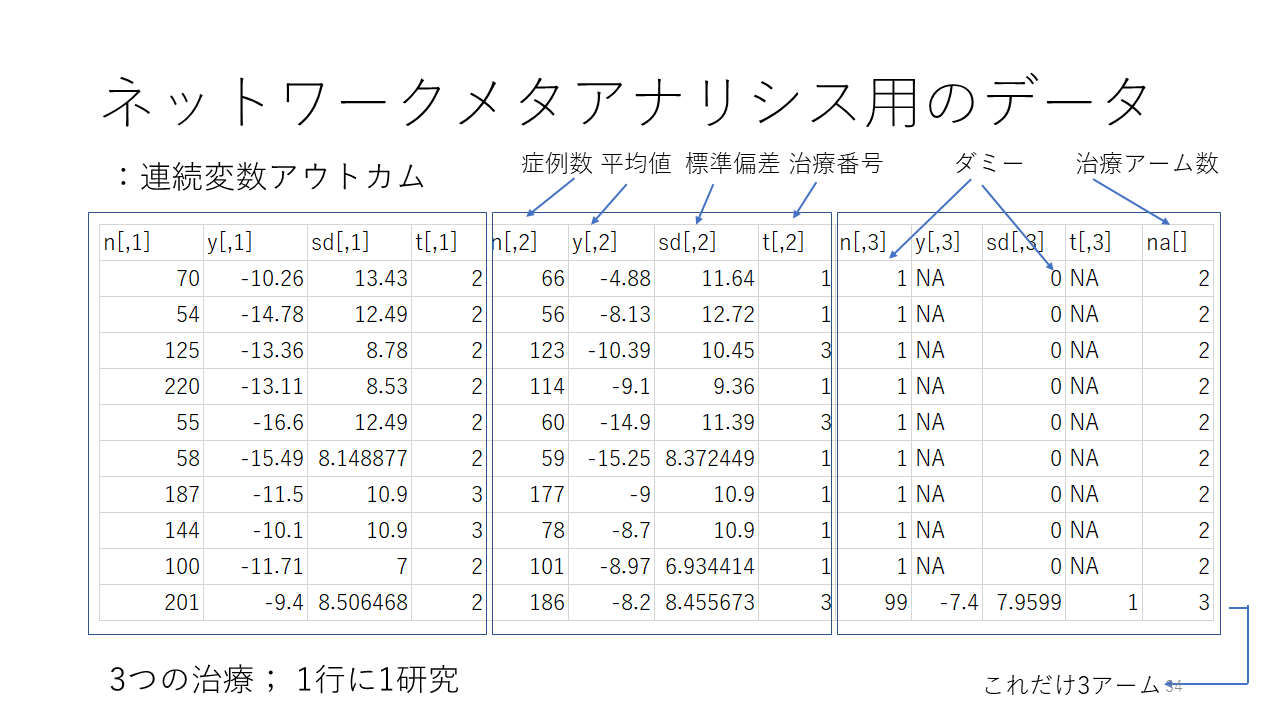
これは4つの治療を比較し、アウトカムが二値変数で測定されているデータの例です。このようなデータをExcelで用意します。
24件の研究で、1つの研究のデータが1行に入力されています。治療は1,2,3、4の整数で表し、1がレファレンスの治療として用いられています。
例えば、2行目のデータを見ると、r[,1]のカラムの2行目の9は、群1でアウトカムが9人に起きたことを意味します。n[,1]は群1の症例数で140人だったことを意味します。群1の受けた治療は、t[,1]で示されており、治療1であることを示しています。つまり、群1は治療1を140人が受け、その内9人でアウトカムが起きたことを示しています。アウトカムは治療開始後1年時点での禁煙です。
同じく2行目のr[,2]は23ですが、群2で23人にアウトカムが起きたことを示しており、n[,2]は140ですが、群2の症例数が140人であったことを示します。群2の治療はt[,2]が3なので、治療3を受けたことを示します。
r[,3]、n[,3]、t[,3]も同様です。2行目の研究は、3つのアームがあり、治療1,3,4を比較するランダム化比較試験です。
4行目の研究は、r[,3]、n[,3]はNA、t[,3]もNAなので、群1が治療2、群2が治療3を受け、これら2群を比較したランダム化比較試験であることが分かります。
最後の列はラベルがna[]となっていますが、the number of armsすなわち、各研究で直接比較された治療の数を示しています。
これらのデータを各研究から抽出しExcelで準備します。準備ができたら、RとJAGSをインストールし、Rでrjagsとgemtcパッケージをインストールして、Excelでデータ範囲をコピーし、インターネット接続の状態で、Rで以下のスクリプトを実行すると結果が得られます。
exdat=read.delim("clipboard",sep="\t",header=TRUE);source("http://zanet.biz/med/stat/ma/nma_gemtc_simpleH.R")
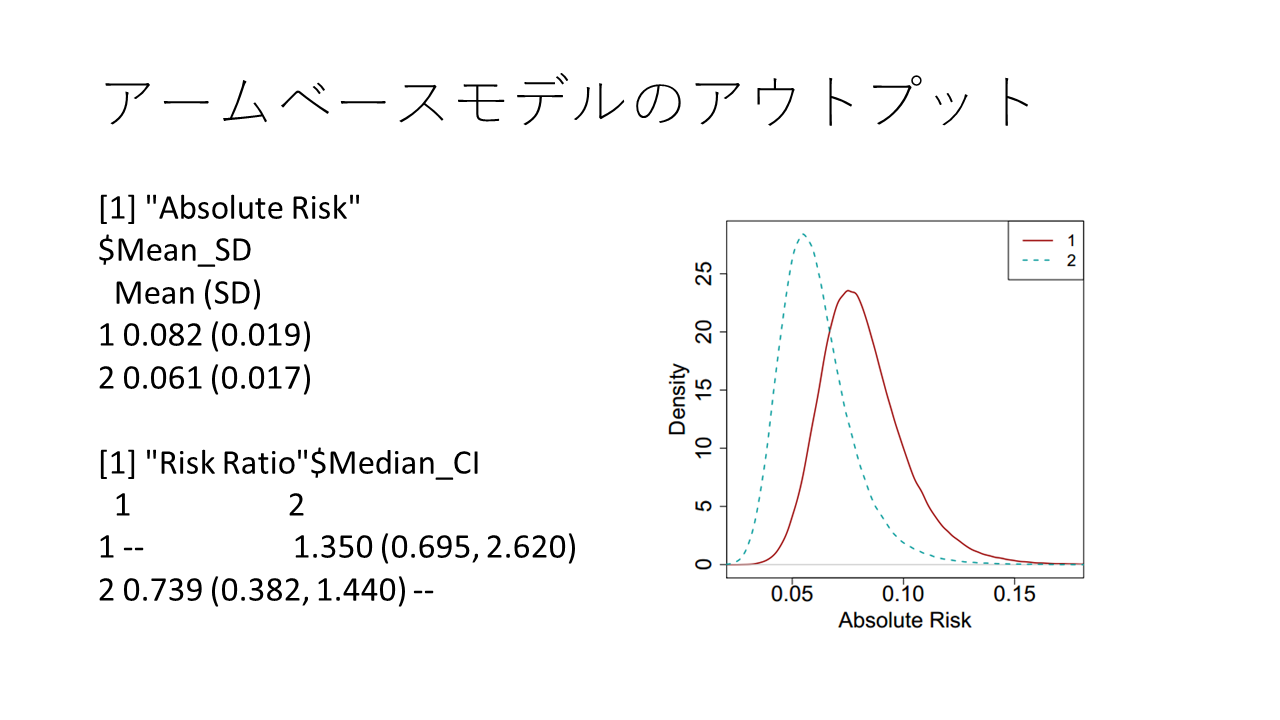
ネットワークグラフ、フォレストプロット、Rankogram、Node-splitting plot、SUCRA plot、SUCRA値、順位と95%確信区間の値が得られます。
これは3つの治療を比較し、アウトカムが連続変数で測定されているデータの例です。
一つの研究のデータが1行に入力されています。
↑ ↓ close
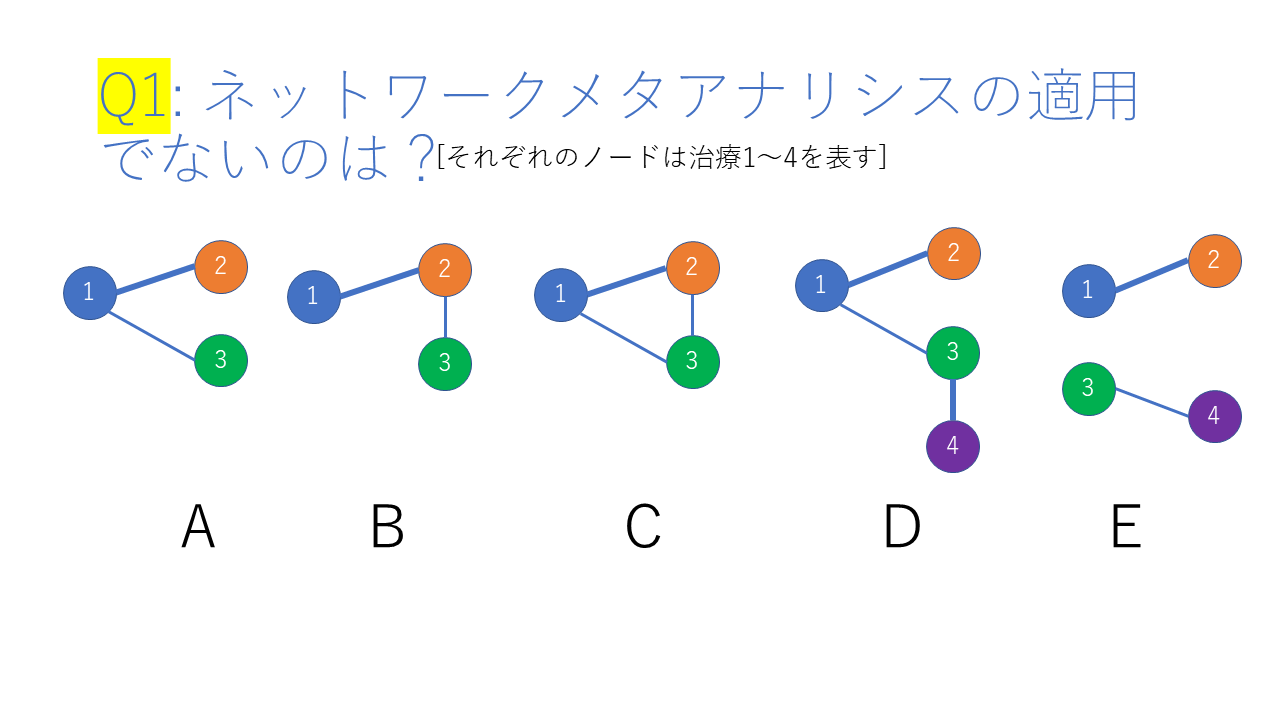
3種類または4種類の治療があり、同じ対象者で同じアウトカムに対する効果を解析したランダム化比較試験が少なくとも2つあるいは3つ以上あった場合。
結合線は直接比較のランダム化比較試験があることを示し、線の太さは研究数を表すとする。
回答はこちら
close
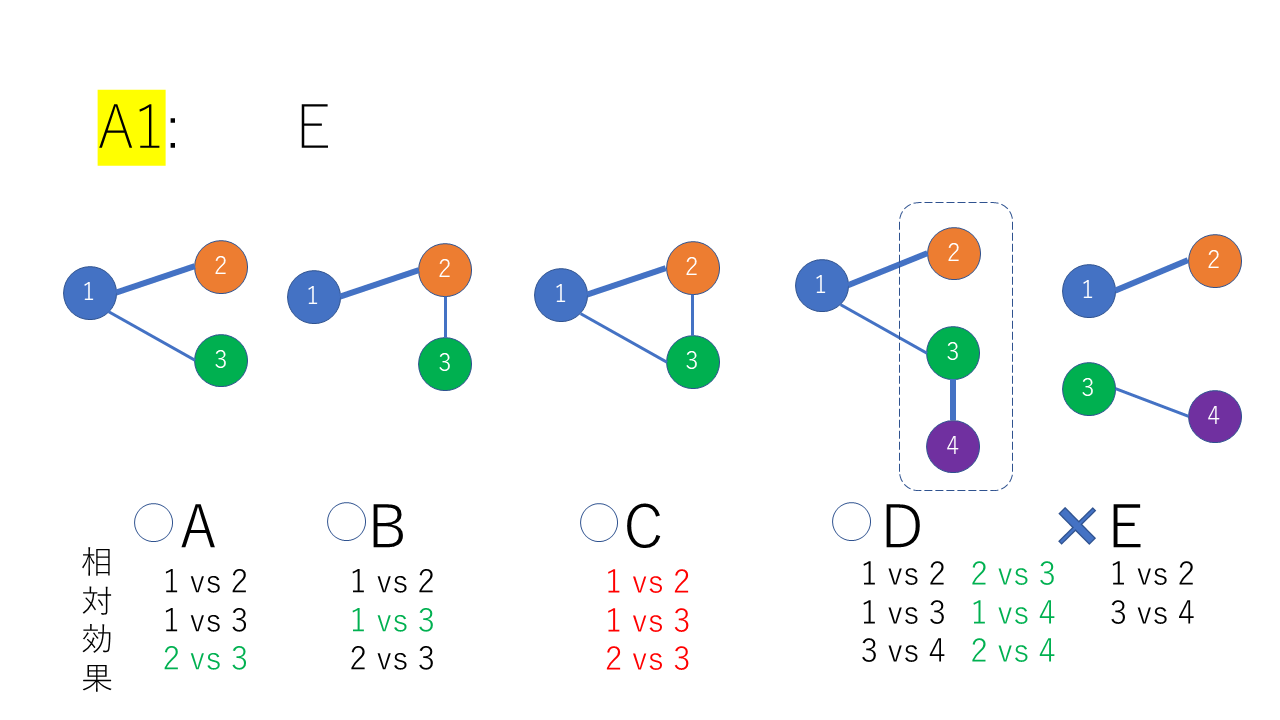
下段に示すペア比較の組み合わせで、黒字は直接比較の場合を表す。緑色の字は間接比較の場合を表す。赤字は直接比較と間接比較の両方可能でネットワークメタアナリシス効果推定値が得られる場合を示す。したがって、赤字はインコヒレンスが生じる可能性がある。
Eの場合は、2つのペア比較は可能であるが、①②と③④は結合線でつながっていないので、ネットワークメタアナリシスはできない。
最初に治療②③④で最善の治療を明らかにしたいと考えて文献調査をしたところ、Dの破線で囲んだ部分の様に②③を比較した研究が見つからなかったとする。しかし、②に関連して①②を比較した研究と③に関連して①③を比較した研究が見つかった場合、①を介して①②③④の繋がったネットワークが形成されることが分かる。そこで、比較治療のセットを②③④から拡大して、①②③④の4種類の治療について2つまたは3つ以上を比較した研究をさらに探し、拡大したセットでネットワークメタアナリシスを行うことができる。
close
回答はこちら
close
ネットワークグラフあるいはネットワークジオメトリは介入比較の構造を示す図で、ネットワークメタアナリシスのための解析プログラムで出力される。ノードはそれぞれの治療、結合線は直接比較のペアを示す。
それぞれの治療について、効果の大きの順位の確率が算出される。その順位確率に基づいて、Rankogram(積み重ね棒グラフあるいは折れ線グラフ)、SUCRA (Surface under the cumulative ranking) curveなどが作成される。
直接比較と間接比較の両方のデータが得られる比較については、両方を統合したネットワーク推定値、直接比較の推定値、間接比較の推定値の3種類の推定値が得られる。これら3種類の点推定値と95%信頼区間をグラフ表示し、さらに直接比較と間接比較の有意差検定のP値を表示するのがNode-splitting plotである。これは、直接比較と間接比較の不一致、すなわちインコヒレンスの評価に用いられる。
SUCRAは曲線下の面積を数値で表示することができ、その値=SURCA値が最大の治療が最も効果の大きい治療と言える。
“閾値分析”はCaldwell DMらが2016年に発表しており、ベースケースの推奨を変更するにはどの程度の大きさのバイアス調整が必要かを示すもので、決断を変更しないで済むバイアス効果(invariant bias adjustment)の大きさの最大値はどれくらいかを数理統計学的に明らかにする方法である。バイアス調整閾値分析はネットワークメタアナリシスの結果に対して、適用することができ、Rのnmathreshパッケージが利用できるが、ネットワークメタアナリシスの結果で得られるものではない。
文献:
Phillippo DM, Dias S, Welton NJ, Caldwell DM, Taske N, Ades AE: Threshold Analysis as an Alternative to GRADE for Assessing Confidence in Guideline Recommendations Based on Network Meta-analyses. Ann Intern Med 2019;170:538-546. PMID: 30909295 URL: https://pubmed.ncbi.nlm.nih.gov/30909295/
Phillippo DM, Dias S, Ades AE, Didelez V, Welton NJ: Sensitivity of treatment recommendations to bias in network meta-analysis. J R Stat Soc Ser A Stat Soc 2018;181:843-867. PMID: 30449954 URL: https://rss.onlinelibrary.wiley.com/doi/10.1111/rssa.12341
nmathreshパッケージ。URL: https://cran.r-project.org/web/packages/nmathresh/
森實 敏夫: 医学統計学シリーズ 第53回 ネットワークメタアナリシスに対するバイアス調整閾値分析 あいみっく 2020:43 (13):43-54. URL: https://www.imic.or.jp/member/files/2020/07/7a3dd76298917488690515f49e9b2c8e-1.pdf
close
回答はこちら
close
優越的な推定値がネットワーク推定値に近似している場合は、インコヒレンスがあってもレートダウンしない。
インコヒレンスがあって、優越的な推定値が無く、非移行性が認められる場合は通常はレートダウンしない方針である。
間接比較の効果推定値は直接比較の効果推定値の差として求められ、その分散は元の比較の分散の合計になるため、不精確性が高まることを理解しておく。
close
比較①は、直接比較のエビデンスの確実性が低、ABCDのCの評価です。コメントdの意味は、“深刻な不精確性”となっています。すなわち、オッズ比の95%確信区間が1をはさんで、しかも0.04から5.45と幅広くなっているため“深刻”と判定したと考えられます。この低の評価は、エビデンス総体の評価なので、おそらく、“深刻な不精確性”とそれ以外のドメイン、例えば、バイアスリスクが“深刻”と判断があって、Aから2段階ダウングレードして、低(C)になったのだろうと考えられます。
比較①の間接比較のエビデンスの確実性は中(B)となっており、コメントeは、“その直接比較のエビデンスが中の質”となっています。ここでいう、その直接比較というのは、上述した直接比較のエビデンスのことではなく、この間接比較の元になった直接比較の意味です。それが、バイアスリスク、非直接性、非一貫性、出版バイアスのいずれか、あるいは、非行性に深刻な問題があると判定したため、AからBへダウングレードしたと考えられます。不精確性は“深刻でない“と判定したと感がられます。
比較①のネットワークメタアナリシスのエビデンスの確実性は、中(B)となっています。コメントは特に付けられていません。ここでは、直接比較と間接比較の効果推定値の点推定値、すなわちオッズ比は0.49と0.53で、ほぼ同じであり、95%確信区間も重なっているので、インコヒレンスは“深刻でない“と判定され、ネットワーク推定値の95%信頼区間が0.29~0.87で1を十分下回っているため、不精確性も深刻でないと判定され、間接比較の貢献度が直接比較の貢献度より大きい(信頼区間の幅から間接比較の重みが大きいと考えられ)ので、間接比較のエビデンスの確実性をネットワーク推定値のエビデンスの確実性に設定したと考えられます。
比較②は直接比較のエビデンスがない場合です。
Puhan MA, et al: A GRADE Working Group approach for rating the quality of treatment effect estimates from network meta-analysis. BMJ 2014;349:g5630. PMID: 25252733 URL: https://www.bmj.com/content/349/bmj.g5630 より一部抜粋翻訳(Table 1)。
close
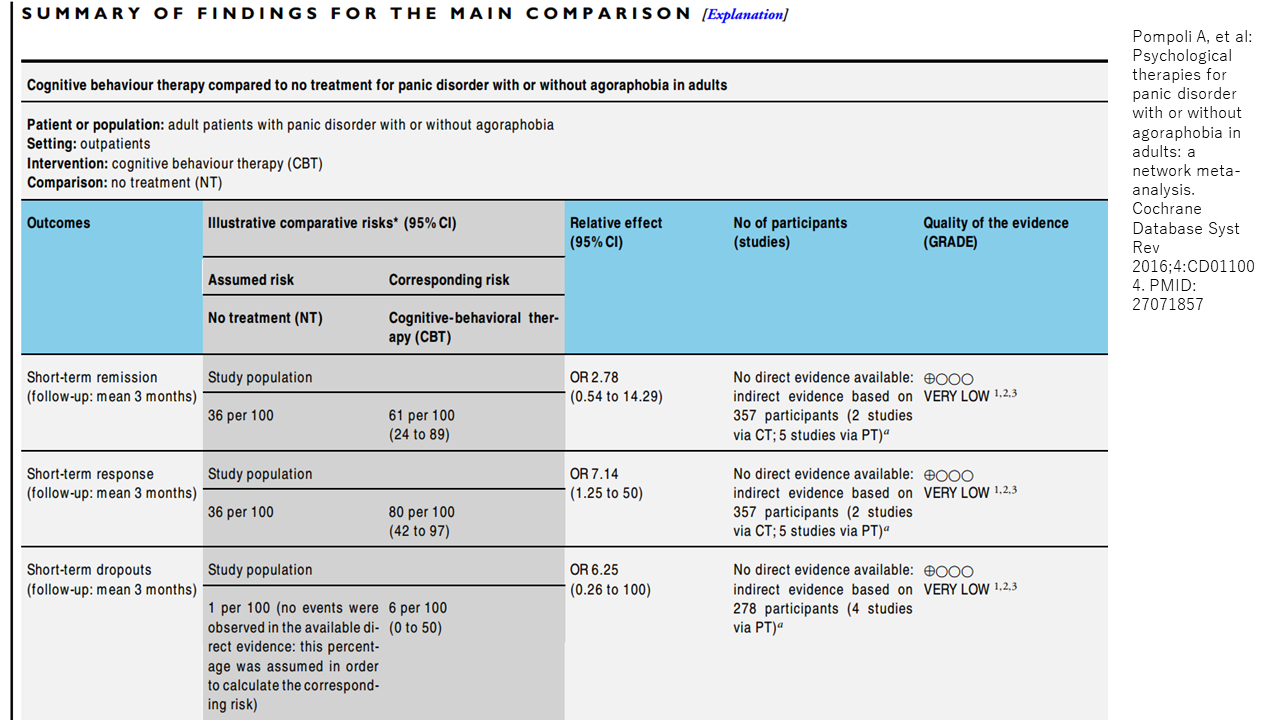
これは、Pompoli AらのシステマティックレビューのSoFテーブルです。
close
Brignardello-Petersen R, et al: GRADE approach to rate the certainty from a network meta-analysis: addressing incoherence. J Clin Epidemiol 2019;108:77-85. PMID: 30529648 URL: https://pubmed.ncbi.nlm.nih.gov/30529648/
close
Brignardello-Petersen R, et al: Corrigendum to “Advances in the GRADE approach to rate the certainty in estimates from a network meta-analysis” [J Clin Epidemiol 2018;93:36-44]. J Clin Epidemiol 2018;98:162. PMID: 29784130 URL: https://pubmed.ncbi.nlm.nih.gov/29784130/





 用語解説1
用語解説1
 用語解説2
用語解説2
 用語解説3
用語解説3
 用語解説4
用語解説4

 統計学的モデル
統計学的モデル
 NMAの二つの統計学的モデル
NMAの二つの統計学的モデル
 Contrast-based model
Contrast-based model
 Arm-based model
Arm-based model
 Arm-based modelのアウトプット
Arm-based modelのアウトプット

 Quiz 1
Quiz 1

 ネットワーク構造の表による提示
ネットワーク構造の表による提示



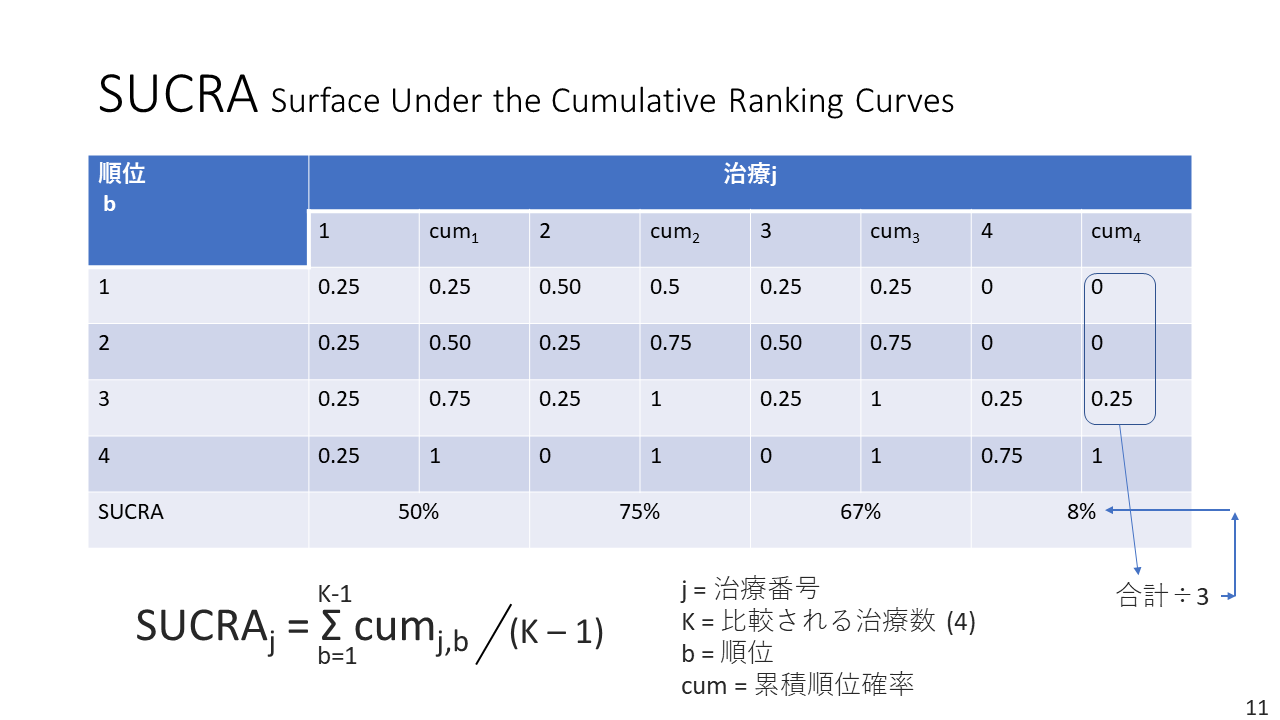 SURCA計算法
SURCA計算法
 OR, RR, HRから絶対効果(RD)
OR, RR, HRから絶対効果(RD)
 SoF例-1
SoF例-1
 SoF例-2
SoF例-2
 Quiz 2
Quiz 2


 Cochrane risk of bias tool ver2.0
Cochrane risk of bias tool ver2.0
 NMA既存論文の例:非直接性
NMA既存論文の例:非直接性
 エビデンス総体RCT5ドメイン
エビデンス総体RCT5ドメイン
 観察研究3ドメイン
観察研究3ドメイン


 Inconsistency Degrees of Freedom (ICDF)
Inconsistency Degrees of Freedom (ICDF)
 ネットワークグラフとループ
ネットワークグラフとループ
 インコヒレンスIncoherence
インコヒレンスIncoherence
 インコヒレンスの評価なし
インコヒレンスの評価なし
 Quiz 3
Quiz 3
 エビデンスの確実性の評価
エビデンスの確実性の評価
 間接比較の効果推定値の逆計算
間接比較の効果推定値の逆計算
 シングルループに対するBucherの計算法
シングルループに対するBucherの計算法
 インコヒレンスへの対応:GRADEアプローチ
インコヒレンスへの対応:GRADEアプローチ
 省略できる作業とインコヒレンスへの対応
省略できる作業とインコヒレンスへの対応






 NMA中のペア比較のエビデンスの確実性評価の一覧表 例
NMA中のペア比較のエビデンスの確実性評価の一覧表 例