ここで、History and Search Detailsの下にある、Details下の>をクリックするとSearch Detailsが表示されます。
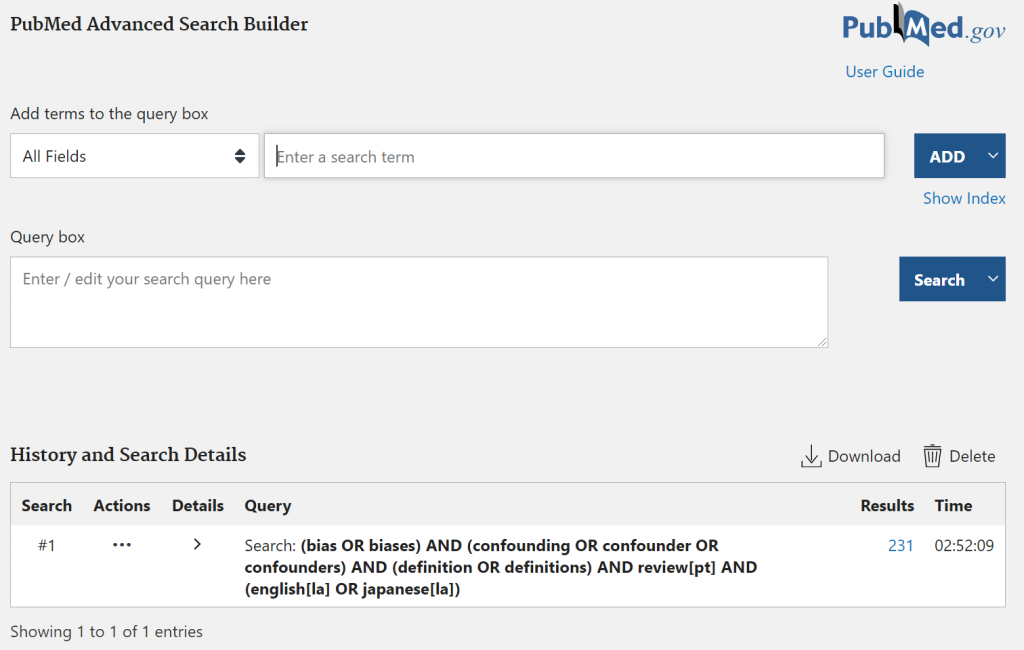
図2.PubMedで検索後Advancedのリンクをクリックすると、Advanced Searchのページが開かれHisory and Search Detailsに検索式が表示されている。
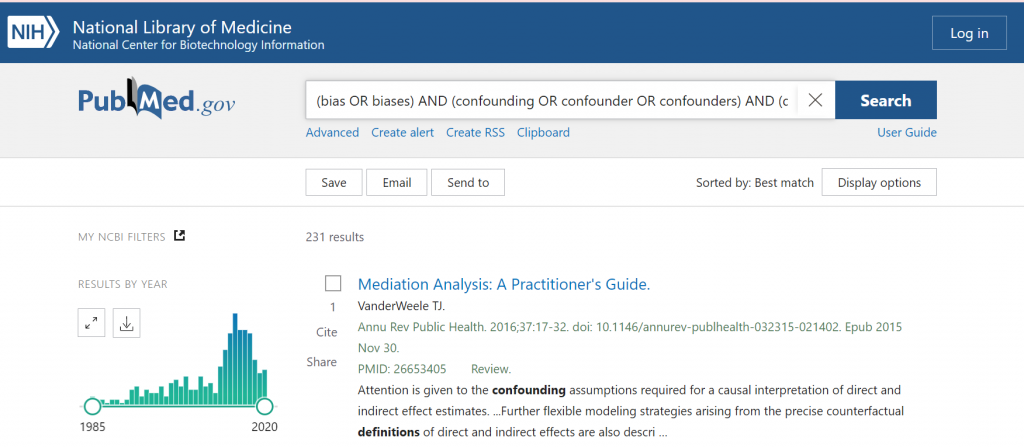
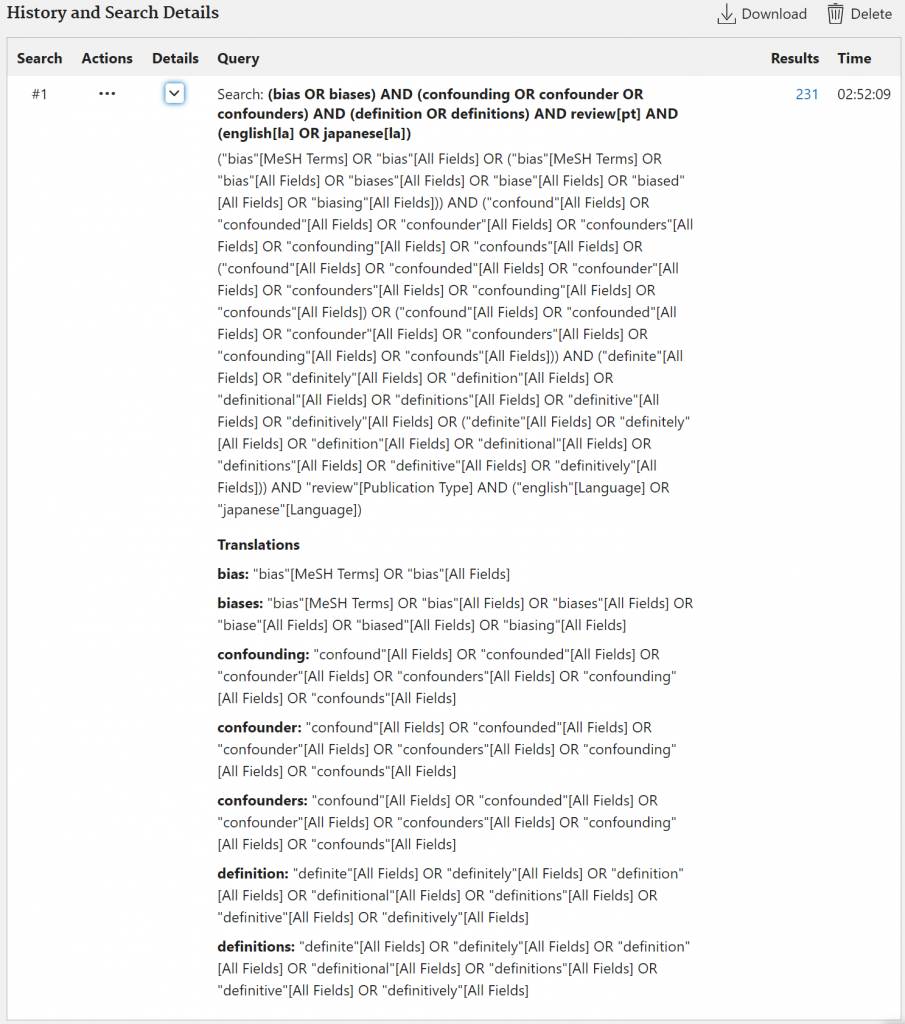
例えば、(bias OR biases) AND (confounding OR confounder OR confounders) AND (definition OR definitions) AND review[pt] AND (english[la] OR japanese[la])という検索式で検索をすると、今日の時点では、231件が引き出されます。この検索式のSearch Detailsは図3のとおりです。元の検索式とはかなり異なっていることがわかります。すなわち、通常のPubMed検索では、Automatic Term Mapping (ATM)が作動して、入力した検索式そのままではなく、シソーラスからMeSH語句の参照も行われ、漏れが少ないより広範な検索が行われるようになっています。この点では、Legacy PubMedと同じです
さて、pmSearchではHow many?でE-utilitiesを使った場合に引き出される文献数をあらかじめ確認できます。また、Search in PubMedでPubMedが開かれ、PubMedの通常の検索が行われます。この2つの文献数が異なる場合、普通は前者の方が少なくなりますが、ATMの作動した結果と同じ結果が欲しい時は、次のような方法で対処できます。Search in PubMedで検索して、Advancedをクリックして、Advanced Searchのページを開き、Detailsの検索式をコピーして、Search queryのフィールド(下から2番目のフィールド)に貼り付けて、One Action Retrievalをクリックして検索結果を得るという方法を使うことができます。こうすることで、ほぼ同じ検索結果が得られます。そして、Recordをクリックして、文献リストの表を表示して、以後の作業を進めることができます。ほぼというのは、まったく同じ結果が得られない場合もありうるという意味です。
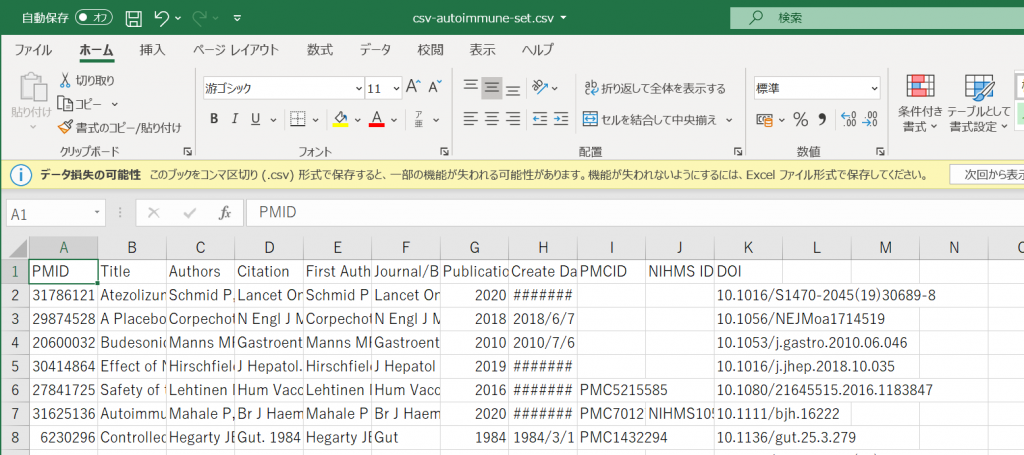
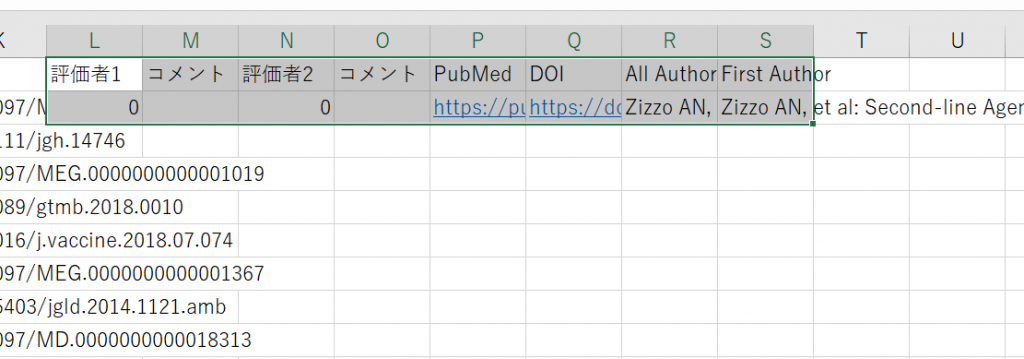
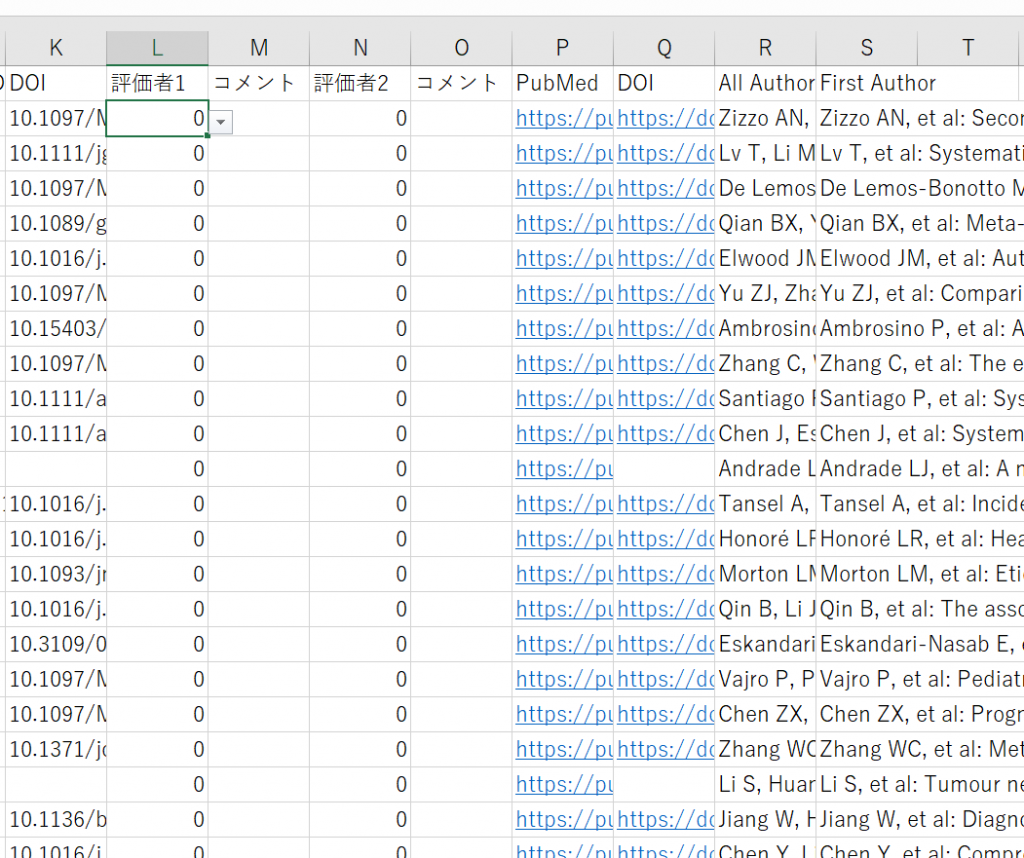
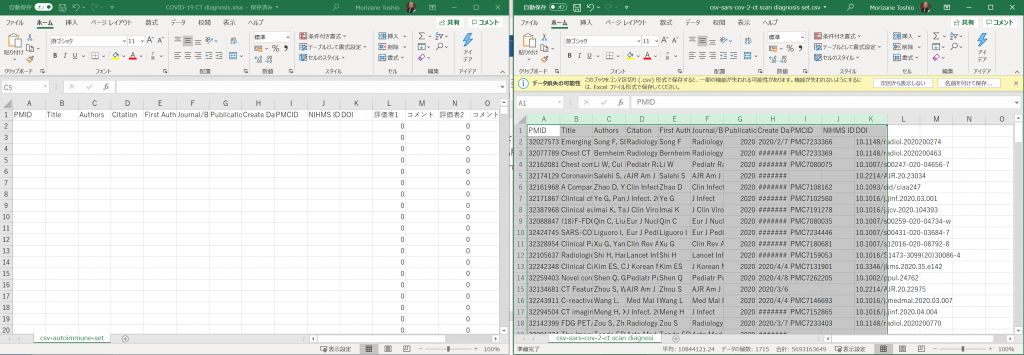
In my previous post, “Using Excel for literature management and selection tasks”, I mainly discussed using Microsoft Excel, but you can also do the same thing with Google Spreadsheets. You can open files created in Excel right into a Google Spreadsheet, and it may also work on a Chrome Book, iPad or Android OS tablet.
You can use OneDrive, Google Drive, DropBox, and other cloud services to share files and allow multiple people to work together, but the method I’m going to show you might be better suited for collaborative work.
I’ve made a video explaining it. There’s no audio, and the instructions come in tickers
医学論文のデータベースとしてPubMed(Medline)、Embase、医学中央雑誌などがあり、文献検索はこれらのウェブサイトに接続し、検索式を送信することで、結果を手元に得られる。また、Google、Google ScholarあるいはBingのようなインターネット検索サービスも科学論文を対象にしており、上記の医学文献データベースを介さず検索することも可能である。また、Cochrane Central Register of Controlled Trials (CENTRAL)はランダム化比較試験の研究論文を検索する際には必要となる。
Schmid P, Rugo HS, Adams S, Schneeweiss A, Barrios CH, Iwata H, Diéras V, Henschel V, Molinero L, Chui SY, Maiya V, Husain A, Winer EP, Loi S, Emens LA; IMpassion130 Investigators. Atezolizumab plus nab-paclitaxel as first-line treatment for unresectable, locally advanced or metastatic triple-negative breast cancer (IMpassion130): updated efficacy results from a randomised, double-blind, placebo-controlled, phase 3 trial. Lancet Oncol. 2020 Jan;21(1):44-59. doi: 10.1016/S1470-2045(19)30689-8. Epub 2019 Nov 27.
Schmid P, et al: Atezolizumab plus nab-paclitaxel as first-line treatment for unresectable, locally advanced or metastatic triple-negative breast cancer (IMpassion130): updated efficacy results from a randomised, double-blind, placebo-controlled, phase 3 trial. Lancet Oncol. 2020 Jan;21(1):44-59. doi: 10.1016/S1470-2045(19)30689-8. Epub 2019 Nov 27.
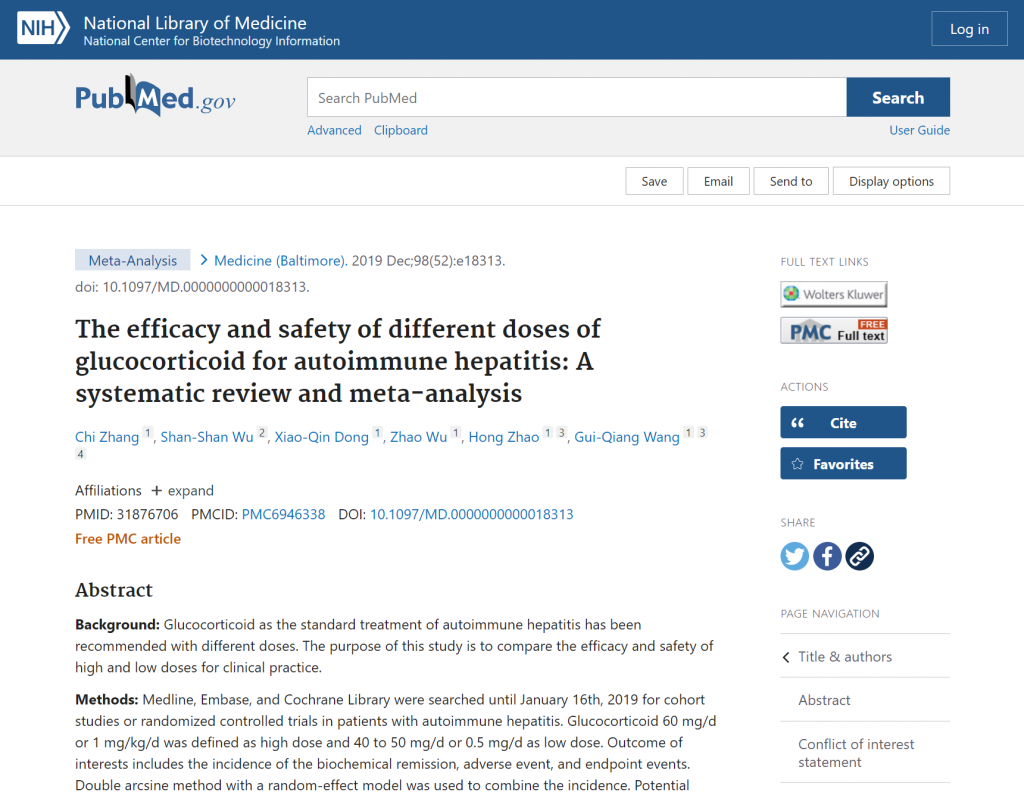
Stellon AJ, Hegarty JE, Portmann B, Williams R. Randomised controlled trial of azathioprine withdrawal in autoimmune chronic active hepatitis. Lancet. 1985 Mar 23;1(8430):668-70. doi: 10.1016/s0140-6736(85)91329-7. PMID: 2858619.
AMA
Stellon AJ, Hegarty JE, Portmann B, Williams R. Randomised controlled trial of azathioprine withdrawal in autoimmune chronic active hepatitis. Lancet. 1985 Mar 23;1(8430):668-70. doi: 10.1016/s0140-6736(85)91329-7. PMID: 2858619.
APA
Stellon, A. J., Hegarty, J. E., Portmann, B., & Williams, R. (1985). Randomised controlled trial of azathioprine withdrawal in autoimmune chronic active hepatitis. Lancet (London, England), 1(8430), 668–670. https://doi.org/10.1016/s0140-6736(85)91329-7
MLA
Stellon, A J et al. “Randomised controlled trial of azathioprine withdrawal in autoimmune chronic active hepatitis.” Lancet (London, England) vol. 1,8430 (1985): 668-70. doi:10.1016/s0140-6736(85)91329-7
NLM
Stellon AJ, Hegarty JE, Portmann B, Williams R. Randomised controlled trial of azathioprine withdrawal in autoimmune chronic active hepatitis. Lancet. 1985 Mar 23;1(8430):668-70. doi: 10.1016/s0140-6736(85)91329-7. PMID: 2858619.