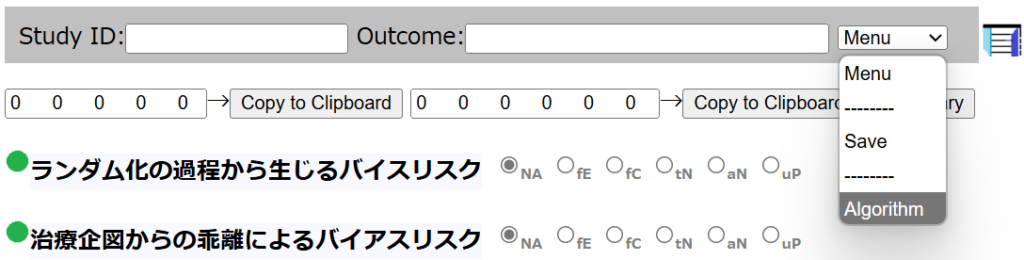
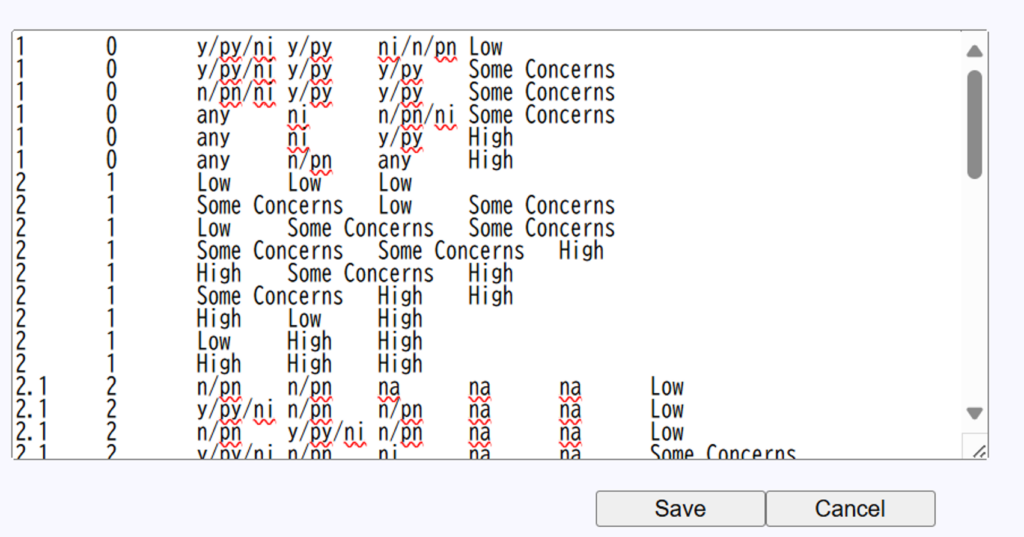
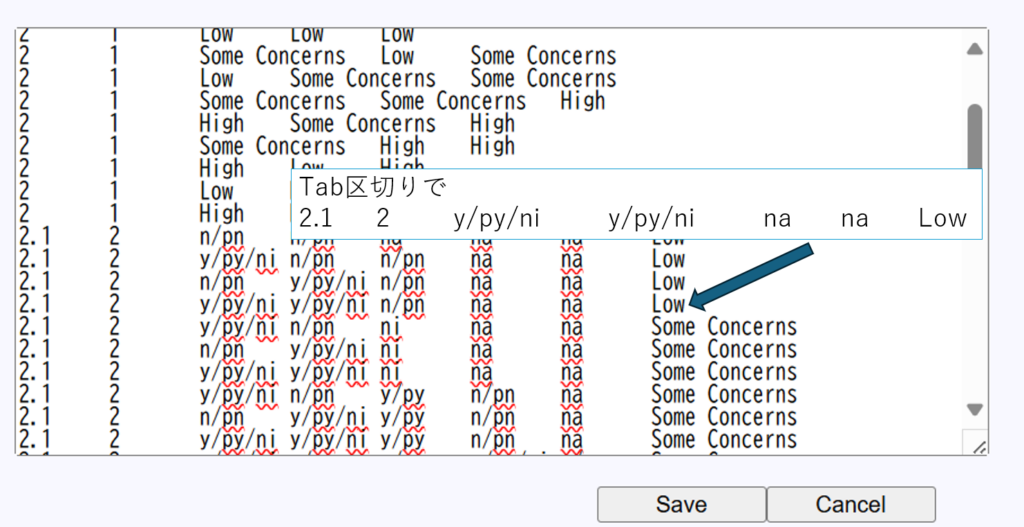
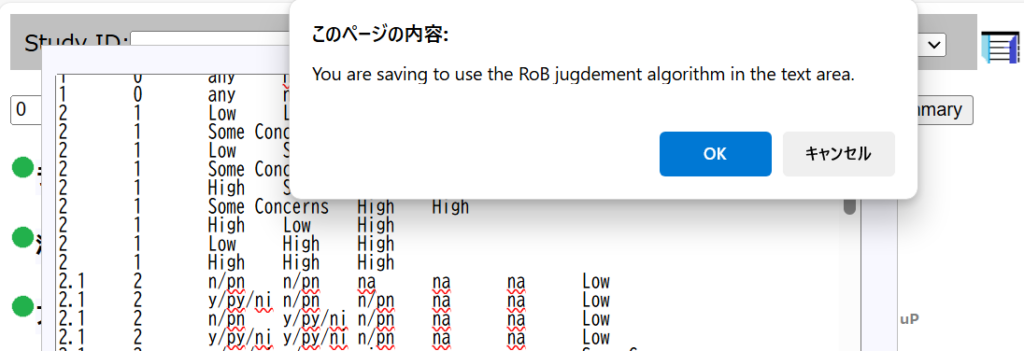
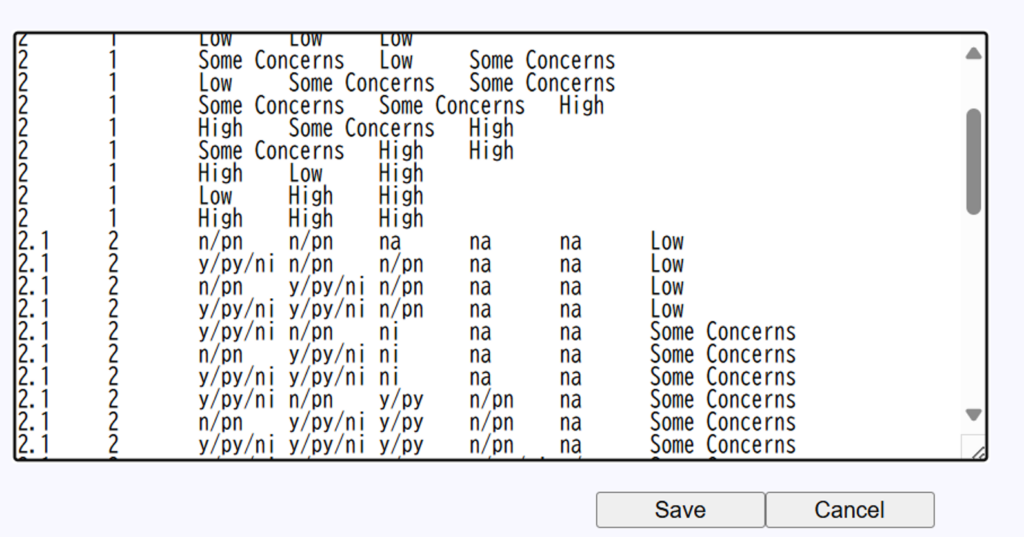
ランダム化比較試験のバイアスリスク評価ツールであるCochrane risk of bias toolが2019年からversion 2.0となり、シグナリングクエスチョンに答えることで、研究ごとのバイアスリスクをLow, Some concerns, Highの3段階で評価する方法に変わりました。Link Excelマクロを用いて、自動判定するファイルも用意されています。
Cochrane risk of bias tool version 2.0ではシグナリングクエスチョンの回答に基づく判定とレビュアの判定が異なる場合、後者を優先することになっています。このウェブツールではその変更はできないので、評価シートの方でレビュアの判定を設定してください。その旨をコメント欄に記入してSaveしておくといいと思います。
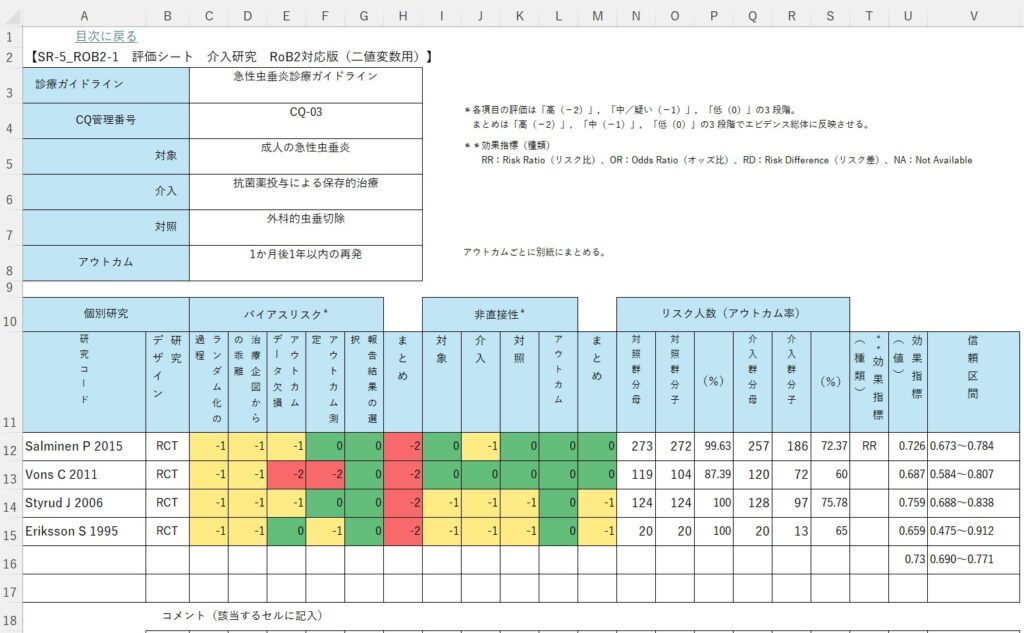
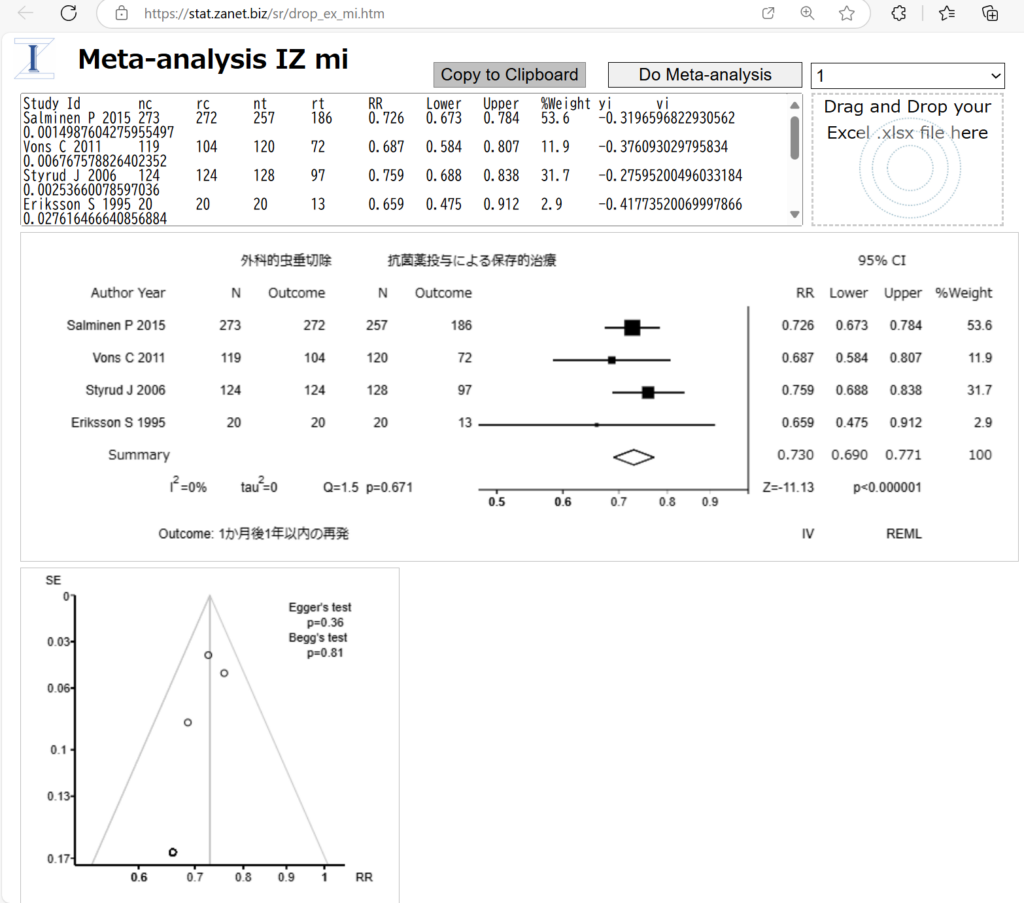
ここで紹介した、Mindsの評価シートに対応しているのが、Meta-analysis IZ miですが、メタアナリシスだけで十分な場合は、別のフォーマットでExcelファイルを用意してMeta-analysis IZ izを使うこともできます。こちらは、REML法とDerSimonian-Laird法の指定ができます。
サンプルデータを入力したMindsの評価シートのファイルとMeta-analysis IZ iz用のサンプルデータを入力したファイルはこちらでダウンロードできます。右クリックして保存してから使用してください。
メタアナリシスの際に用いている計算式について詳細を知りたい人は、Deeks J and Higgins JPT 2010を参照してください。この解説の時点では、研究間の分散の計算はDerSimonian-Laird法を用いていますが、最近RevManでもREML法も選択できるようになったようです。McKenzie J, Veroniki AAの解説を参照してください。
文献: Viechtbauer W: Bias and Efficiency of Meta-Analytic Variance Estimators in the Random-Effects Model. Journal of Educational and Behavioral Statistics Fall 2005, Vol. 30, No. 3, pp. 261–293. Link
Viechtbauer W氏のR package metafor Link The metafor Package: A Meta-Analysis Package for R. Link
Deeks J and Higgins JPT: Statistical algorithm in Reveiw Manager 5. 2010. Link
McKenzie J, Veroniki AA: Introduction to new random-effects methods in RevMan. Link 解説スライド
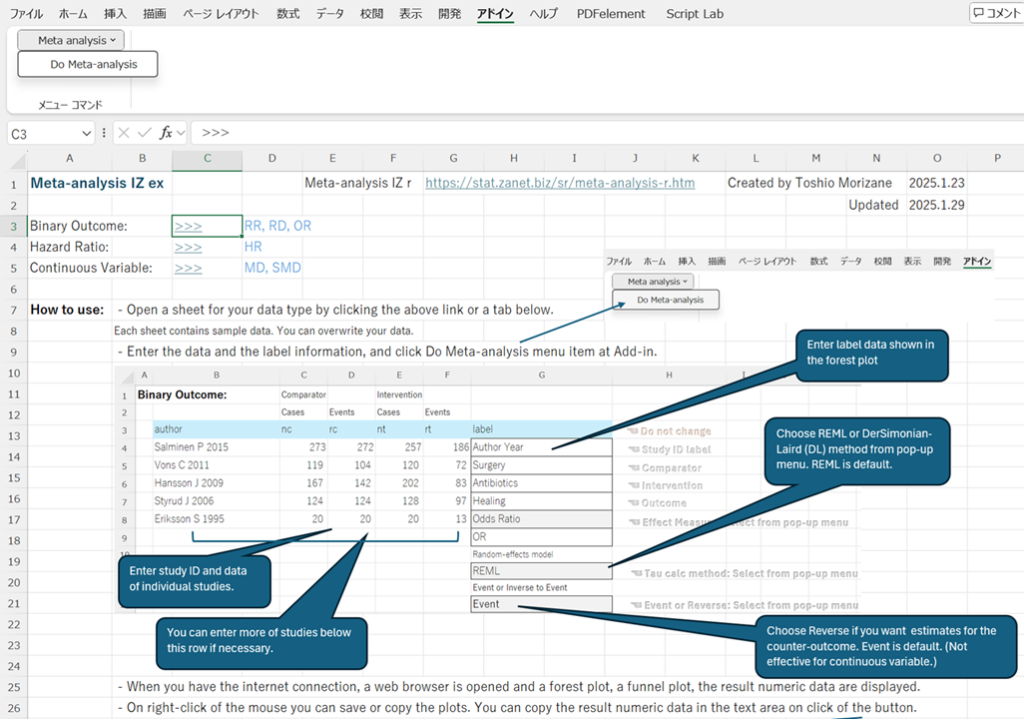
また、Mindsの評価シートをBookとしてまとめた、2025_excel_book_for_sr.xlsmというファイルと、そこから必要なシートをコピーして、システマティックレビューに使用するシートを集めたBookを各自作るための2025_My_SR Book.xlsmというファイルも入れてあります。システマティックレビュー用の評価シートに必要なデータを入力後、アドインメニューからMeta-analysis → Do Meta-analysisをクリックするとブラウザが開かれ、結果が表示されます。これらのBookの評価シートは、Rのパッケージmetafor, forestpolotを用いて、Rで動作するメタアナリシスを行うのスクリプトも含んでいるのでRを使ってメタアナリシスをすることもできますし、後述するMeta-analysis IZ rというウェブツールを使ってメタアナリシスをすることもできます。
Gail MH, Costantino JP, Bryant J, Croyle R, Freedman L, Helzlsouer K, Vogel V: Weighing the risks and benefits of tamoxifen treatment for preventing breast cancer. J Natl Cancer Inst 1999;91:1829-46. doi: 10.1093/jnci/91.21.1829 PMID: 10547390 URL: https://pubmed.ncbi.nlm.nih.gov/10547390/
MCDAについて広く解説されている。Keeney & Raiffaの方法の実例の解説がある。
Thokala P, Devlin N, Marsh K, Baltussen R, Boysen M, Kalo Z, Longrenn T, Mussen F, Peacock S, Watkins J, Ijzerman M: Multiple Criteria Decision Analysis for Health Care Decision Making-An Introduction: Report 1 of the ISPOR MCDA Emerging Good Practices Task Force. Value Health 2016;19:1-13. PMID: 26797229 URL: https://pubmed.ncbi.nlm.nih.gov/26797229/
上記のThokala Pの報告の後半に相当し、ISPORの公式の報告として出版されている。
Marsh K, IJzerman M, Thokala P, Baltussen R, Boysen M, Kalo Z, Lonngren T, Mussen F, Peacock S, Watkins J, Devlin N, ISPOR Task Force: Multiple Criteria Decision Analysis for Health Care Decision Making-Emerging Good Practices: Report 2 of the ISPOR MCDA Emerging Good Practices Task Force. Value Health 2016;19:125-37. PMID: 27021745 URL: https://pubmed.ncbi.nlm.nih.gov/27021745/
効果推定値の不確実性から正味の益の不確実性を推定する方法。
Wen S, Zhang L, Yang B: Two approaches to incorporate clinical data uncertainty into multiple criteria decision analysis for benefit-risk assessment of medicinal products. Value Health 2014;17:619-28. PMID: 25128056 URL: https://pubmed.ncbi.nlm.nih.gov/25128056
GRADEワーキンググループの益と害のバランス=正味の益に関するコンセプトペーパー。Certainty of net benefitという考えは、USPSTFと同じで、推奨の強さを決める主要要素。Appendixに具体的な計算法が記載されている。
Alper BS, Oettgen P, Kunnamo I, Iorio A, Ansari MT, Murad MH, Meerpohl JJ, Qaseem A, Hultcrantz M, Schunemann HJ, Guyatt G, GRADE Working Group: Defining certainty of net benefit: a GRADE concept paper. BMJ Open 2019;9:e027445. PMID: 31167868 URL: https://pubmed.ncbi.nlm.nih.gov/31167868/
定量的ベネフィット・リスク分析に関するISPORの公式の報告。実際的な手順を解説。
Tervonen T, Veldwijk J, Payne K, Ng X, Levitan B, Lackey LG, Marsh K, Thokala P, Pignatti F, Donnelly A, Ho M: Quantitative Benefit-Risk Assessment in Medical Product Decision Making: A Good Practices Report of an ISPOR Task Force. Value Health 2023;26:449-460. doi: 10.1016/j.jval.2022.12.006 PMID: 37005055 URL: https://pubmed.ncbi.nlm.nih.gov/37005055/
Ho M, Saha A, McCleary KK, Levitan B, Christopher S, Zandlo K, Braithwaite RS, Hauber AB, Medical Device Innovation Consortium’s Patient Centered Benefit-Risk Steering Committee: A Framework for Incorporating Patient Preferences Regarding Benefits and Risks into Regulatory Assessment of Medical Technologies. Value Health 2016;19:746-750. PMID: 27712701 URL: https://pubmed.ncbi.nlm.nih.gov/27712701/
Phillippo DM, Dias S, Welton NJ, Caldwell DM, Taske N, Ades AE: Threshold Analysis as an Alternative to GRADE for Assessing Confidence in Guideline Recommendations Based on Network Meta-analyses. Ann Intern Med 2019;170:538-546. doi: 10.7326/M18-3542 PMID: 30909295 URL: https://pubmed.ncbi.nlm.nih.gov/30909295/
Eiring Ø, Brurberg KG, Nytrøen K, Nylenna M: Rapid methods including network meta-analysis to produce evidence in clinical decision support: a decision analysis. Syst Rev 2018;7:168. doi: 10.1186/s13643-018-0829-z PMID: 30342549 URL: https://pubmed.ncbi.nlm.nih.gov/30342549/