CPG is a document with recommendations based on assessing evidence from clilnical studies, benefits and harms, patients’ values and preferences, resource use, and cost, incorporating uncertainties of effect estimates and other parameters. The aim of CPG is to aid health care providers and patients, care givers to make a best decision.
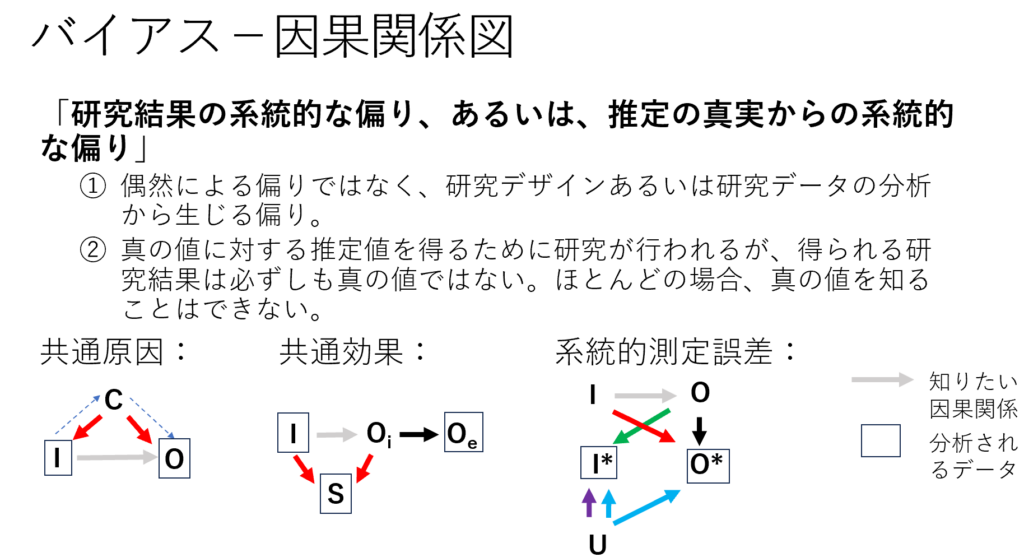
バイアスは「研究結果の系統的な偏り、あるいは、推定の真実からの系統的な偏り」と定義されています。系統的とは? 偶然による偏りに対して、偶然起きる偏りではないので、系統的な偏りと言います。系統的systematic vs 偶然random という考え方をしているということです。偶然による偏りは、統計学的に説明可能でサンプルサイズが小さいほど大きくなります。バイアスによる偏りは経験的empiricalなデータは限られており、バイアス効果の大きさと方向(過大評価か過小評価か)については評価者が推定せざるをえないことがほとんどです。
バイアスの議論の際に、よく引用されるBerkson’s biasは選択バイアスとして知られていますが、共通効果のDAGを使って説明されます(Westreich D 2012)。例えば、クリニック受診患者を対象として糖尿病と認知症の関係を分析した場合、受診の原因が糖尿病の場合もあり認知症の場合もあります。クリニック受診が共通効果になります。クリニックを受診しない患者は選択せず、クリニック受診患者だけを選択して糖尿病と認知症の関係を分析するとバイアスが生じます。このようなバイアスは、前向き研究でも後ろ向き研究でも、観察研究でもランダム化比較試験でも起きる可能性があります。
共通効果で条件付けされるすなわちconditioned on (分類される)ある層だけを対象として選択したり、共通効果で調整するとバイアスが生じます。すなわち、図に示す変数Sに基づく層のひとつを分析する、あるいは変数SでIとOeの関係を調整した分析を行うとバイアスが生じます。このようなバイアスの結果は過大評価になる場合も、過小評価になる場合もあり、例えば、上記の例だと糖尿病は認知症のリスクを高めることはないという結果が得られる可能性があります。
ランダム化比較試験のバイアス評価について、特にCochrane risk of bias tool ver. 2.0 RoB 2)を中心にスライドと解説の資料を作成しました。RoB 2を用いたランダム化比較試験のエビデンス評価の作業をする際に参考にしてください → Link
文献: Turner RM, Spiegelhalter DJ, Smith GC, Thompson SG: Bias modelling in evidence synthesis. J R Stat Soc Ser A Stat Soc 2009;172:21-47. PMID: 19381328 PubMed
Phillippo DM, Dias S, Ades AE, Didelez V, Welton NJ: Sensitivity of treatment recommendations to bias in network meta-analysis. J R Stat Soc Ser A Stat Soc 2018;181:843-867. PMID: 30449954 PubMed
Lash TL, VanderWeele TJ, Haneuse S, Rothman KJ: Modern Epidemiology (FORTH EDITION). 2021, Wolters Kluwer, PA, USA. Amazon
Luijendijk HJ, Page MJ, Burger H, Koolman X. Assessing risk of bias: a proposal for a unified framework for observational studies and randomized trials. BMC Med Res Methodol. 2020 Sep 23;20(1):237. doi: 10.1186/s12874-020-01115-7. PubMed
Hernán MA, Monge S: Selection bias due to conditioning on a collider. BMJ 2023;381:1135. doi: 10.1097/EDE.0000000000000031 PMID: 37286200 PubMed
バイアスに関する論文はたくさんありますが、役立ちそうな文献を少しあげておきます: Hernán MA, Monge S: Selection bias due to conditioning on a collider. BMJ 2023;381:1135. doi: 10.1136/bmj.p1135 PMID: 37286200 PubMed
Thorpe KE, et al: CMAJ 2009;180:E47-57. doi: 10.1503/cmaj.090523 PMID: 19372436
Tosh G, et al: Pragmatic vs explanatory trials: the pragmascope tool to help measure differences in protocols of mental health randomized controlled trials. Dialogues Clin Neurosci 2011;13:209-15. doi: 10.31887/DCNS.2011.13.2/gtosh PMID: 21842618