前の投稿で文献数が90件の場合、PubMedで検索結果をAbstract (text)形式でテキストファイルとしてダウンロードしたファイルをNotebookLMでソースとしてアップロードして、PICO要約表を作成できることを示しました。今回は、1894件の文献を含むテキストファイルで一つのファイルとしては、約5MB、約70万語の大きなファイルを分割したテキストファイルを作成し、それらをNotebookLMのソースにまとめてアップロードして、1つのファイルごとにプロンプトを実行してPICO要約表を作成して、漏れなく文献の一次選定ができるかを検討してみました。基準としては前回と同じくNaing C 2024のコクランシステマティックレビューで採用された9文献:Barbare JC 2005、Chow PK 2002、Liu CL 2000、CLIP Group 2000、Riestra S 1998、Castells A 1995、Martínez Cerezo FJ 1994、Elba S 1994、Farinati F 1990を標的文献としました。
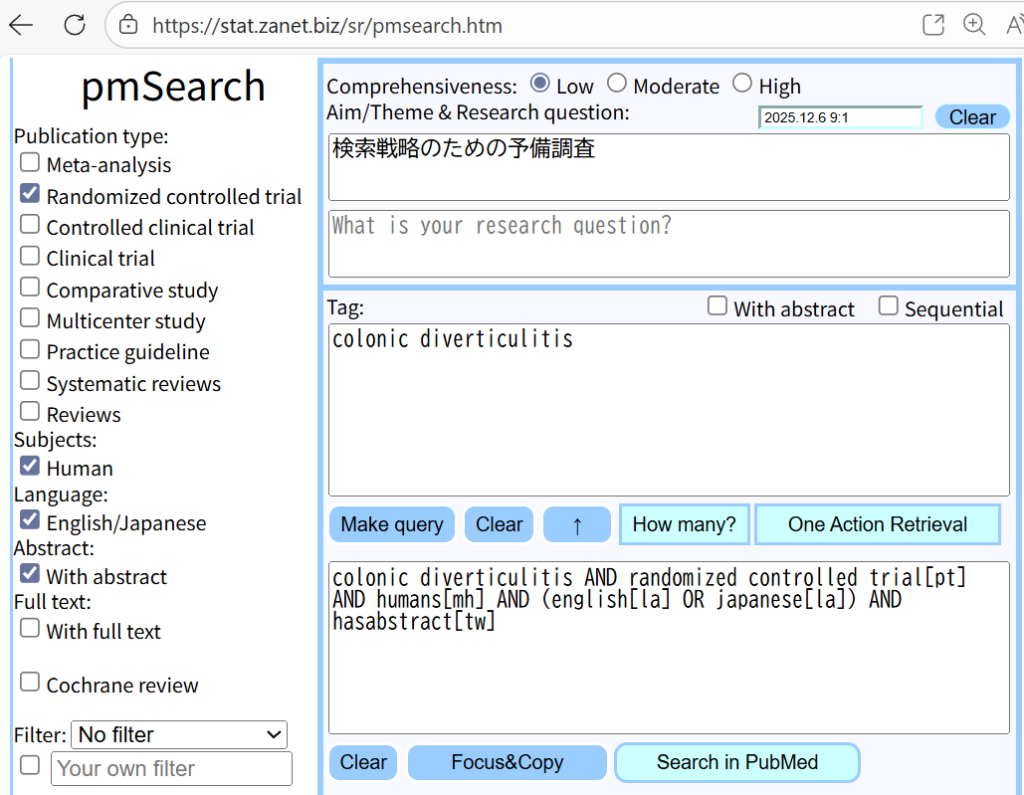
PubMedの検索式は以下の通りです。検索結果をAbstract (text)形式でテキストファイルとしてダウンロードしました。この中に9件の標的文献が含まれていることは確認してあります。
(hepatocellular carcinoma[tw] OR carcinoma,hepatocellular[mh]) AND (drug therapy[mh] OR "Antineoplastic Agents" [Pharmacological Action]) AND (english[la] OR japanese[la]) AND (randomized controlled trial [pt] OR controlled clinical trial [pt] OR randomized [tiab] OR placebo [tiab] OR clinical trials as topic [MeSH:noexp] OR randomly [tiab] OR trial [ti] NOT(animals [mh] NOT humans [mh]))1894件で70万語ではNotebookLMの1ファイルの容量制限を超えているので、文献数400件ずつに分割した5つのテキストファイルを用意しました。その作成方法については後述します。単語数が約7万から22万のファイルになりました。
用いたプロンプトは以下のものです。除外基準の記述の部分をGeminiに用いたものと少し変更しています。こちらの方がより論理的な記述だと思います。
ソースのテキストファイルから、以下の採用基準と除外基準に合致する文献を抽出して、Study ID、P、I、C、O、コメント、PMIDの7列からなるテーブルを作成してください。P,I,C,O,コメントは原則日本語で記述してください。研究は年度の新しい順に並べ、Googleスプレッドシートへエクスポートできるテーブルとして提示してください。
Study IDは第一著者の姓のフルスペル+半角スペース+イニシャル+半角スペース+年度を記述してください。著者名が複数の場合et al.を付ける必要はありません。
Pの欄は対象者に関する記述(症例数)、Iの欄は介入に関する記述(症例数)、Cの欄は対照の治療に関する記述(症例数)、Oの欄は測定されたアウトカムの内容を記述してください。
コメント蘭は介入の効果の概略を記述してください。
PMIDの欄はhttps://pubmed.ncbi.nlm.nih.gov/PMID/のように、クリックしたらPubMedの該当する文献を開けるようなリンクのURLを記述してください。URLの最後は/で閉じてください。"PMID"は不要で、URLだけを記述してください。
P, I, C, Oの欄は他の研究との違いが分かる程度の詳細な情報を含めてください。
単位の表記はLaTex記法を使わないでテキストで表示してください。
採用基準:
研究デザインはランダム化比較試験。
対象は肝細胞癌患者。
介入がタモキシフェン単独投与。
対照がプラセボあるいは無治療あるいは保存的治療。
生存をアウトカムとして分析。
除外基準:
システマティックレビュー/メタアナリシスの論文。
対照が肝動脈塞栓療法や化学塞栓療法の研究。
対照でタモキシフェンが投与されている研究。
アウトカムとして生存が分析されていない研究。5つのテキストファイルをアップロードした状態では、全体の概略が中央に提示されています。通常すべてのソースが選択された状態になっていますが、ここで、分析対象のファイルのひとつだけにチェックを入れて、チャットエリアに上記プロンプトをコピー・貼り付けし、エンターキーを押すか>ボタンをクリックします。

最初はファイル1を選択しています。1分もかからないで、回答が提示され、該当する文献はないという回答でした。この時点では、上の中央右のあたりに、チャットのパネルに更新ボタンが出ているので、それをクリックして、更新し、ファイル1のチェックをはずし、ファイル2を選択して、クリップボードに残っている、プロンプトをチャットエリアに貼り付け、新たにまたプロンプトを実行します。
2025.12.19更新ボタンが無くなり、プルダウンメニューからチャットの履歴を削除を用いるようになっています。
更新→次のファイルの選択→同じプロンプトを実行を繰り返していきます。PICO要約表が提示されたら、Googleスプレッドシートで空白のスプレッドシートを開き、表の内容をドラグして選択し、貼り付けます。また、チャットエリアのすぐ上にメモに保存のボタンが出るので、右のStudioの方に回答を保存しておけば、後で、表データを利用することもできます。
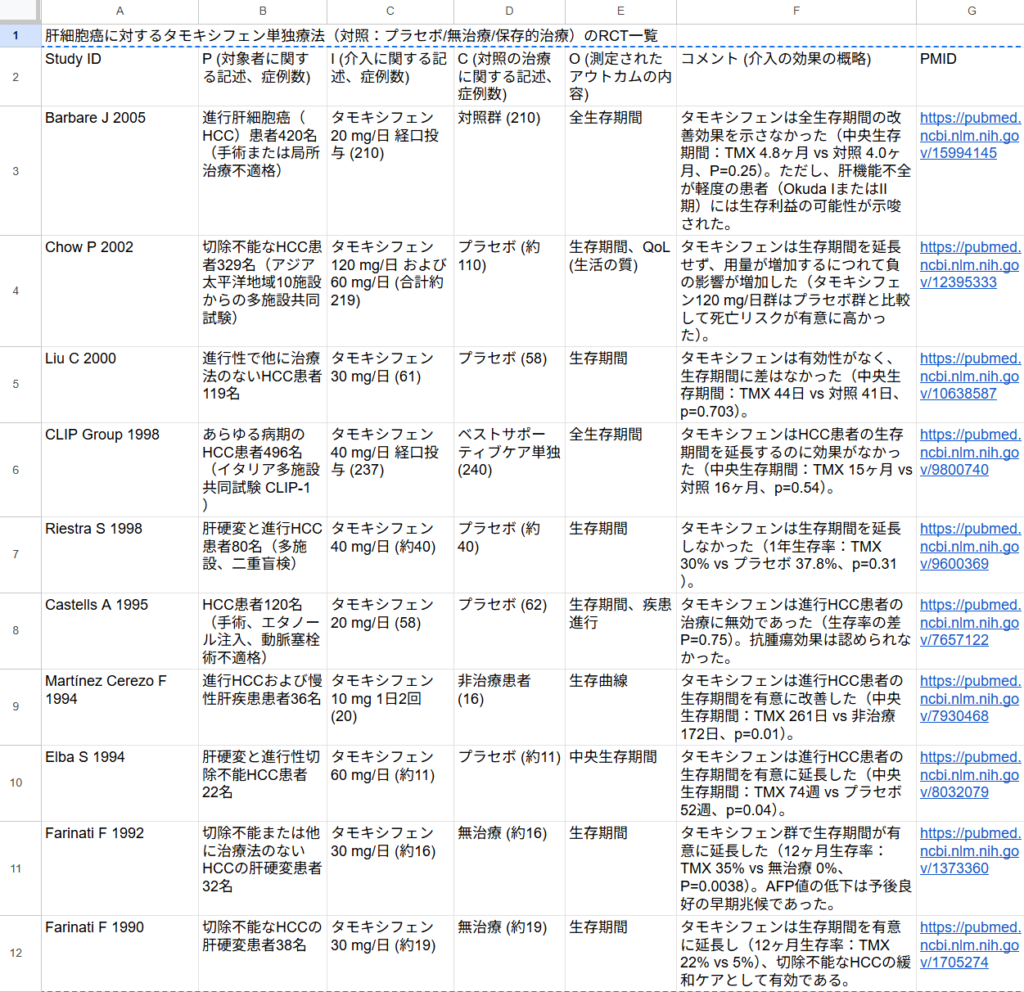
これで計10件の文献が選定されました。基準の文献リストのCLIP Group 2000が含まれていないのですが、実はこの論文と同じ内容の時間的に後で発表された論文がPerrone F 2002の論文でしたのでAIはこちらを選定したようです。
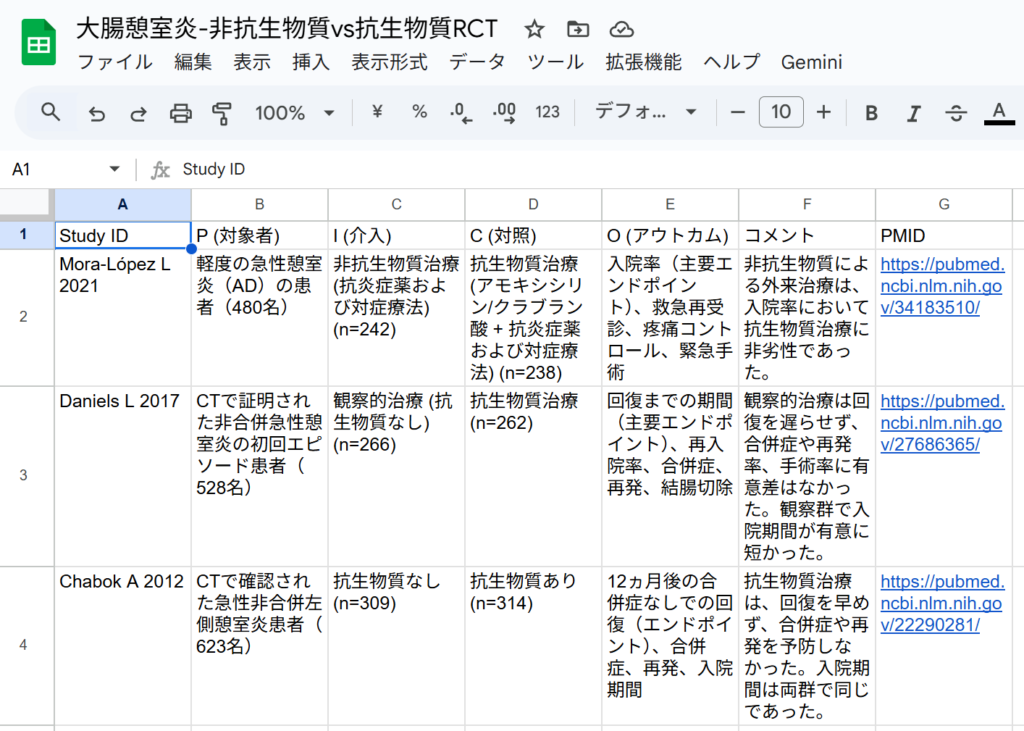
Farinati F 1992は基準の文献リストには含まれていなかったので、 Farinati F 1990と2つの異動は別にして、1件プラスされていたことになります。PICO要約表を以下に図として示します。

今回の検討から、NotebookLMの場合、文献数400程度のテキストファイルに分割して、1つずつ更新しながらプロンプトを実行すると、漏れなく、正確度も高く、文献選定ができそうなことが分かりました。なお、すべてのファイルを選択して、あるいは例えばファイル4,5の2つを選択してプロンプトを実行すると漏れが生じ、同じ結果は得られませんでした。
さて、Abstract (text)形式のテキストファイルの分割方法ですが、Divide PubMed Abstract (text) Fileというウェブツールを作成しました。URL: https://stat.zanet.biz/sr/div-pubmed-abstract.htm を開いて、元のテキストファイルをドラグアンドドロップすると、400件ずつのファイルに分割し、ファイル名をクリックするとファイルをダウロードできます。ファイル名には文献数を含めてありますが、当然のことながら最後のファイルは400より少ない文献数になります。
分割したファイルをZIPファイルにまとめたファイルもダウンロードできるので、こちらであれば1回のダウンロードで済むので通常はこちらを使い、ダウンロードしたZIPファイルの中身のすべてのファイルを外に出して使えばいいと思います。NotebookLMのソースにアップロードする際は、すべてのファイルを選択していっぺんにアップロードすればいいです。そして、上記のプロンプトを使って1ファイルずつ処理してみて下さい。
このウェブツールでは分割の単位を任意に設定出来ます。500件、300件、200件、100件ずつに分割することも試してみましたが、400件で十分なようです。

今後、様々な例で性能を試す必要があるでしょう。今後Gemini 3を試してみる必要もあるかもしれません。少し試した感じでは、あまり結果には差がありませんでした。また、コンテンツを知らなくても、機械的な操作だけで選定が可能なので、PubMedからダウンロードしたAbstract (text)形式テキストファイルを渡して、誰かに選定作業をしてもらい、マニュアルでの選定結果と比較することも考えられます。また、AIの機能には揺れがあるようで、タイミングによって、結果が変動する可能性があり、プロンプトの指示通りにならないこともあり、同じ対象ファイルで数人が同じプロンプトを実行して、まとめるというやり方も考えられます。プロンプトの書き方と対象ファイルの大きさの影響が大きいと感じました。プロンプトの指示通りにならなかった時、続けて修正の指示をプロンプトで書いて実行するとうまくいく場合もありますがそうならない時もありました。
NotebookLMやGeminiでの選定作業とスプレッドシートに結果を移す作業は非常に短時間で気楽にでき、極めて短時間で済みます。
文献:
Naing C, Ni H, Aung HH: Tamoxifen for adults with hepatocellular carcinoma. Cochrane Database Syst Rev 2024;8:CD014869. doi: 10.1002/14651858.CD014869.pub2 PMID: 39132750