A systematic review is a scientific investigation that focuses on a specific question and uses explicit, preplanned scientific methods to identify, select, assess, and summarize the findings of individual, relevant studies. It may or may not include a quantitative synthesis of the results from separate studies (meta-analysis).
得られた標準化平均値差Standardized Mean Difference (SMD)と95%信頼区間の値を、分かりやすい元のスケールに戻して、効果の大きさを評価することが行われます。元のスケールに戻すには、標準偏差の値が必要です。また、SMDが0.2は小さな効果、0.5は中等度の効果、0.8は大きな効果という考え方を用いることも提案されています。
SMDを用いるメタアナリシスの演算は、Keeds JJ, Higgins JPT:Statistical algorithms in Review Manager 5. 2010. Link に記載されている方法に従って行われることが一般的です。計算に用いられる式を図1と図2に示します。
図1. Standardized Mean Differenceとその分散の計算式。図2.DerSimonian-Laird法によるランダム効果モデルを用いる分散逆数法によるメタアナリシスの計算式。
これらの計算はExcelでもできますし、Rのパッケージmetaforでもできます。また、著者が作成したMeta-analysis IZ Linkあるいは Meta-analysis IZ r Linkでもできます。Meta-analysis IZ rではMindsの評価シートのデータをReformatして、メタアナリシスを実行できます。
エビデンスの確実性とは:GRADEはエビデンスの確実性を、真の効果が特定の閾値の片側あるいは効果量の選択された範囲にある確実性と定義した」(Schünemann HJ 2022)、あるいは、「GRADEワーキンググループは、個々のアウトカムに対するエビデンスの確実性をレーティングするとき、真の効果が特定の範囲にある、または、ある閾値の片側にあることに、我々がどれくらい確かだと思うかを我々はレーティングしているということを明確にしている」(Hultcrantz M 2017)とされています。
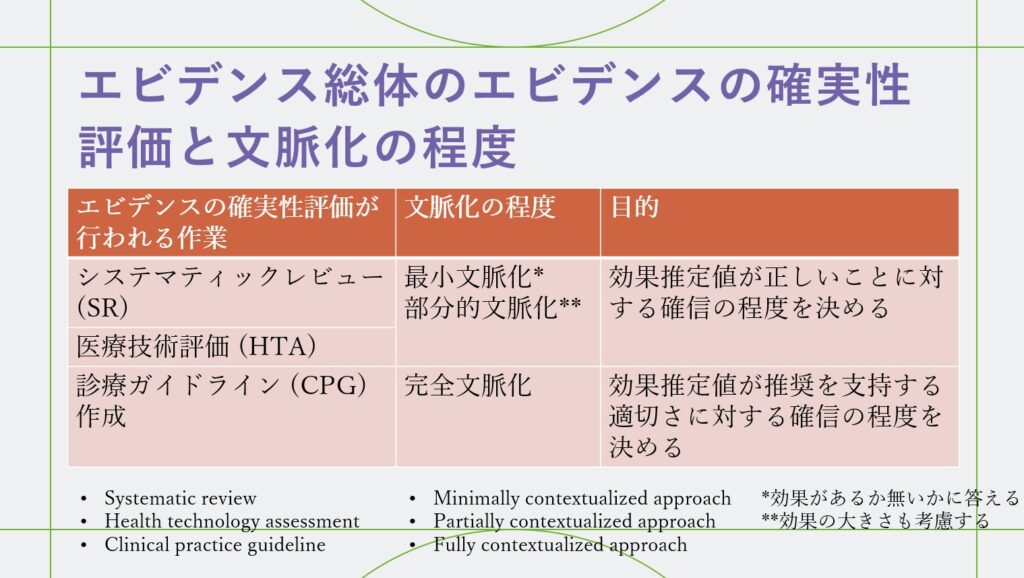
GRADEワーキンググループ(WG)は2017年にエビデンスの確実性の概念(costruct)について論文(Hultcrantz M 2017)を発表しました。その後のWGの議論を踏まえて、2021年の論文(Zeng L 2021)では、エビデンスの確実性評価の実際的なガイダンスについて述べています。そのガイダンスでは、エビデンスの確実性の評価者は、エビデンスの確実性の概念の何を評価するのかを明確にする必要があると述べており、それを確実性のレーティングの標的(the target of their certainty rating)と呼んでいます。
そして、確実性のレーティングの標的は、エビデンスの確実性評価の文脈化の程度によって異なり、最小文脈化のアプローチでは無効果あるいは効果ありの確実性、または、効果推定値が無効果を含むある範囲にある確実性が標的になります。部分的文脈化のアプローチでは閾値の片側にある確実性あるいは信頼区間が大・中・小の臨床的意味のある閾値と交差する数が標的になります。完全文脈化ではさらに、正味の益を明確にしたうえで、信頼区間の上限値、下限値でそれが反転するかどうかを見る(Hultcrantz M 2017)、あるいは、望ましくない効果の上限値の総和への影響を見る(Schünemann HJ 2022)ことになります。
効果推定値が大の閾値を超えるようなありそうもない大きな効果を示している場合、あるいは、わずかまたは小さな効果の場合に、Review Information Size(RIS)レビュー情報量を計算する必要があります。大・中・小の閾値に対する必要なRIS、すなわちその大きさの効果を証明に必要なサンプルサイズを計算し、その結果で、実際のサンプルサイズが•大きな効果の閾値より少ない ⇒ 3レベルレートダウン;•中等度の効果の閾値より少ない ⇒ 2レベルレートダウン;•小さな効果の閾値より少ない ⇒ 1レベルレートダウンすることが提案されています。ただし、効果推定値の95%信頼区間の大・中・小の閾値との交差と合わせて慎重に判断する必要があります。
OISは臨床的に意味のある効果推定値を証明するのに必要なサンプルサイズ。エビデンスの確実性の評価で、部分的文脈化あるいは完全文脈化アプローチを用いる場合は、大・中・小の閾値を設定する必要があり、それぞれに対する必要なサンプルサイズを計算するので、RISという用語を用いる。OIS: Optimal Information Size最適情報量; RIS: Review Information Sizeレビュー情報量
文献: Hultcrantz M, et al: The GRADE Working Group clarifies the construct of certainty of evidence. J Clin Epidemiol 2017;87:4-13. doi: 10.1016/j.jclinepi.2017.05.006 PMID: 28529184
Alper BS, et al: Defining certainty of net benefit: a GRADE concept paper. BMJ Open 2019;9:e027445. doi: 10.1007/s11882-011-0185-8 PMID: 31167868
Zeng L, et al: GRADE guidelines 32: GRADE offers guidance on choosing targets of GRADE certainty of evidence ratings. J Clin Epidemiol 2021;137:163-175. doi: 10.1016/j.jclinepi.2021.03.026 PMID: 33857619
Schünemann HJ, et al: GRADE guidance 35: update on rating imprecision for assessing contextualized certainty of evidence and making decisions. J Clin Epidemiol 2022;150:225-242. doi: 10.1016/j.jclinepi.2022.07.015 PMID: 35934266