Obeso V, Brown D, Aiyer M, Barron B, Bull J, Carter T, Emery M, Gillespie C, Hormann M, Hyderi A, Lupi C, Schwartz M, Uthman M, Vasilevskis EE, Yingling S, Phillipi C, eds.; for Core EPAs for Entering Residency Pilot Program. Toolkits for the 13 Core Entrustable Professional Activities for Entering Residency. Washington, DC: Association of American Medical Colleges; 2017. aamc.org/initiatives/coreepas/publicationsandpresentations
Physician Competencies Reference Set (PCRS) – FINAL, July 2013には医師に必要なコンピテンシーのドメインとして以下の8つの項目を上げています。これらについては、上記のリンク中のCore Entrustable Professional Activities for Entering Residency: Curriculum Developers’ GuideのAppendix Cに記述されています。
1. 患者のケア(PC Patient Care): 健康問題の治療と健康増進のために、思いやりのある適切かつ効果的な、患者中心のケアを提供する。 2. 実践のための知識(KP Knowledge for Practice): 確立された生物医学、臨床医学、疫学、社会行動学に関する知識と、これらの知識を患者ケアに応用できることを示す。 3. 実践に基づく学習と改善(PBLI Practice-Based Learning and Improvement): 自己の患者ケアについて調査・評価し、科学的根拠を評価・吸収し、常に自己評価と生涯学習に基づき患者ケアを継続的に改善する能力を示す。 4. 対人関係およびコミュニケーション能力(ICS Interpersonal and Communication Skills): 患者、家族、医療従事者との効果的な情報交換や協力関係を築くための対人関係やコミュニケーション能力を発揮することができる。 5. プロフェッショナリズム(P Professionalism): 専門家としての責任を果たし、倫理的原則を遵守することを実証する。 6. システムに基づいた実践(SBP Systems-Based Practice):最適なヘルスケアを提供するために、ヘルスケアの大きな文脈とシステムに対する認識と対応、およびシステム内の他のリソースを効果的に活用する能力を実証する。
7. 専門家間のコラボレーション(IPC Interprofessional Collaboration):安全で効果的な患者・住民中心のケアを最適化するために、専門職間チーム に参加する能力を証明する。 8. 個人的および専門的な開発(PPD Personal and Professional Development:): 生涯にわたって自己および専門的な成長を維持するために必要な資質を示す。
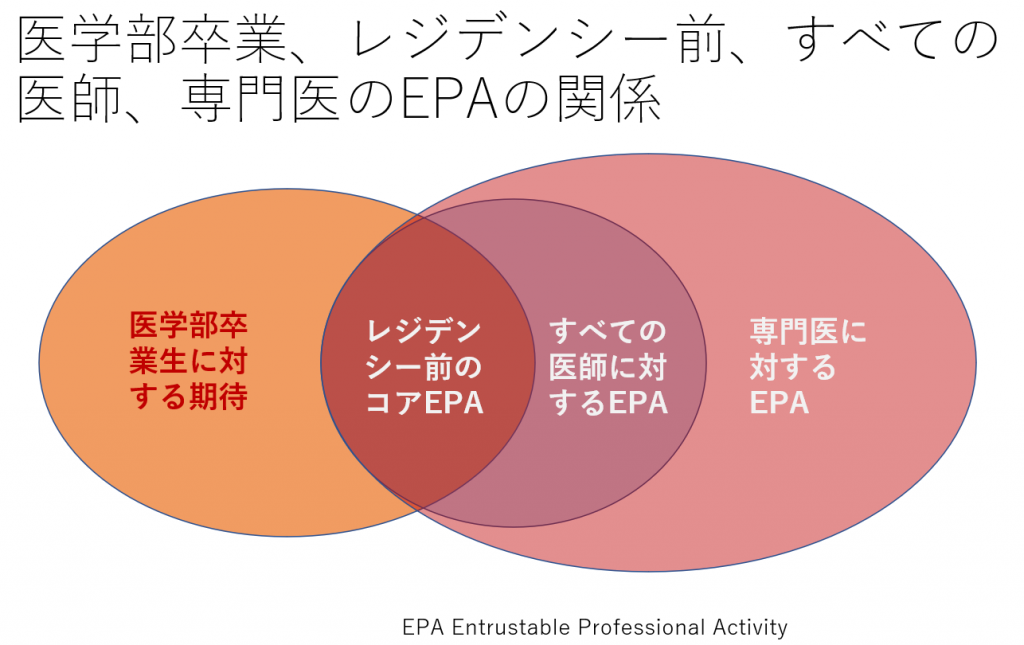
コンピテンシーとEPA(Entrustable Professional Activities)という、文献上有力な2つの概念的枠組みの利点と欠点を検討した後、起草委員会はEPAを採用することにした。なお、EPAとコンピテンシーは相互に排他的なものではないことに留意されたい。それどころか、EPA は定義上コンピテンシーの統合を必要とし、コンピテンシーは(EPA の枠組で提供できるように)パフォーマンスという文脈で評価されるのが最良である。
EPAは仕事の単位であり、コンピテンシーは個人の能力である。EPA の特徴の 1 つは、通常、領域横断的にコンピテンシーの統合を必要とすることである。この概念を本業務に適用するため、起草委員会は、13 の EPA のそれぞれについて、委託を決定するために最も重要な 5~8 のコンピテンシーを決定するためのマッピング作業を実施した。コンピテンシーは、”Reference List for General Physician Competencies “(上記の8つ)から選択した。
Core Entrustable Professional Activities for Entering Residency: Toolkits for the 13 Core EPAs.
Contents EPA 1 Toolkit: Gather a History and Perform a Physical Examination EPA 2 Toolkit: Prioritize a Differential Diagnosis Following a Clinical Encounter EPA 3 Toolkit: Recommend and Interpret Common Diagnostic and Screening Tests EPA 4 Toolkit: Enter and Discuss Orders and Prescriptions EPA 5 Toolkit: Document a Clinical Encounter in the Patient Record EPA 6 Toolkit: Provide an Oral Presentation of a Clinical Encounter EPA 7 Toolkit: Form Clinical Questions and Retrieve Evidence to Advance Patient Care EPA 8 Toolkit: Give or Receive a Patient Handover to Transition Care Responsibility EPA 9 Toolkit: Collaborate as a Member of an Interprofessional Team EPA 10 Toolkit: Recognize a Patient Requiring Urgent or Emergent Care and Initiate Evaluation and Management EPA 11 Toolkit: Obtain Informed Consent for Tests and/or Procedures EPA 12 Toolkit: Perform General Procedures of a Physician EPA 13 Toolkit: Identify System Failures and Contribute to a Culture of Safety and Improvement
利用ガイドとして次の様に述べられています。このツールキットは、「レジデント開始時の中核的な委託可能な専門的活動(EPA)」の実施に関心のある医学部向けのものです。AAMC Core EPA Pilot Groupによって書かれたこのツールキットは、EPA Developer’s Guide(AAMC 2014)に概説されているEPAのフレームワークを拡張したものです。パイロットグループは、学生が医学部のカリキュラムに参加し、臨床技能を統合することに熟達するにつれて、医学教育者が遭遇する可能性のある学生の行動の段階的なシーケンスを特定しました。これらの一連の行動は、EPAを理解するための枠組みを提供するために、13のEPAそれぞれについて1ページの図式で明確にされています。
EPAがどのようなものかは、Toolkits for the 13 Core Entrustable Professional Activities for Entering Residency. Washington, DC: Association of American Medical Colleges; 2017を読まないとなかなか理解できないかもしれません。上記のリンクからFull Toolkit (PDF)を開いてみてください。13のツールキットに関してひとつのファイルとしまとめられています。
Englander R, Cameron T, Ballard AJ, Dodge J, Bull J, Aschenbrener CA: Toward a common taxonomy of competency domains for the health professions and competencies for physicians. Acad Med 2013;88:1088-94. doi: 10.1097/ACM.0b013e31829a3b2b PMID: 23807109
Core Entrustable Professional Activities for Entering Residency: Curriculum Developers’ Guideには、13のEPAについて、それぞれ、活動の記述、最も関連のあるコンピテンシーのドメイン、それぞれのドメイン内で委託可能な決断にとって重大な(Critical)コンピテンシー、およびそれぞれの重大なコンピテンシーについて、委託可能前の行動(Behaviors)、委託可能な行動について記述が表にまとめられています。表に続いて、委託可能前の学習者の場合の期待される行動と例、委託可能な学習者の期待される行動と例に対する記述があります。
Appendix CがReference List of General Physician Competencies by Domainで最初に紹介した、PC, KP, PBLI, ICS, P, SBP, and IPC, PPDのコンピテンシーがリストアップされていますので、その他のコンピテンシーについても確認することができます。
日本の場合は、平成28年度改訂版 医学教育モデル・コア・カリキュラム 133ページに 医師として求められる基本的な資質・能力の項に、9つの項目が挙げられており、134ページからは、臨床実習の到達目標として9つの項目が挙げられています。さらに、141ページ 臨床実習で学生を信頼し任せられる役割(EPA: Entrustable Professional Activities)として、13項目について5段階評価のための表が掲載されています。アメリカの場合と比べると、ほぼ同じ項目が含まれていますが、相違もあります。
ACGME (Accreditation Council for Graduate Medical Education) 米国卒後医学教育認定評議会は卒後教育におけるマイルストーンMilestonesを設定しています。Milestone Resourcesでさまざまな資料が公開されています。
CBMEとは? CBMEは、コアコンピテンシーやマイルストーンの実施を含め、研修医やフェローの教育に利用されてきました。文献によると、CBMEは「コンピテンシーという組織的枠組みを用いて、医学教育プログラムの設計、実施、評価を行うアウトカムベースのアプローチ」と定義されています(Frank et al.2010)。コンピテンシーとは、誰かが仕事をするために必要な主要な能力の集合を表すものである。例えば、将来医師となる人は皆、患者ケアを行うための基本的な知識と能力を備えていなければなりません。これらの重要な能力がなければ、仕事を遂行することはできません。