学習目標を設定する際に、単純な知識やスキルからより複雑なものへと分類することができます。その分類を表すのにタキソノミーTaxonomy(分類学)という用語が使われています。Bloom’s TaxonomyとSOLO Taxonomyが広く使われていると思います。SOLO Taxonomyについては、以前このブログでも紹介しました。(SOLOはStructure of Observed Learning Outcomesです。)
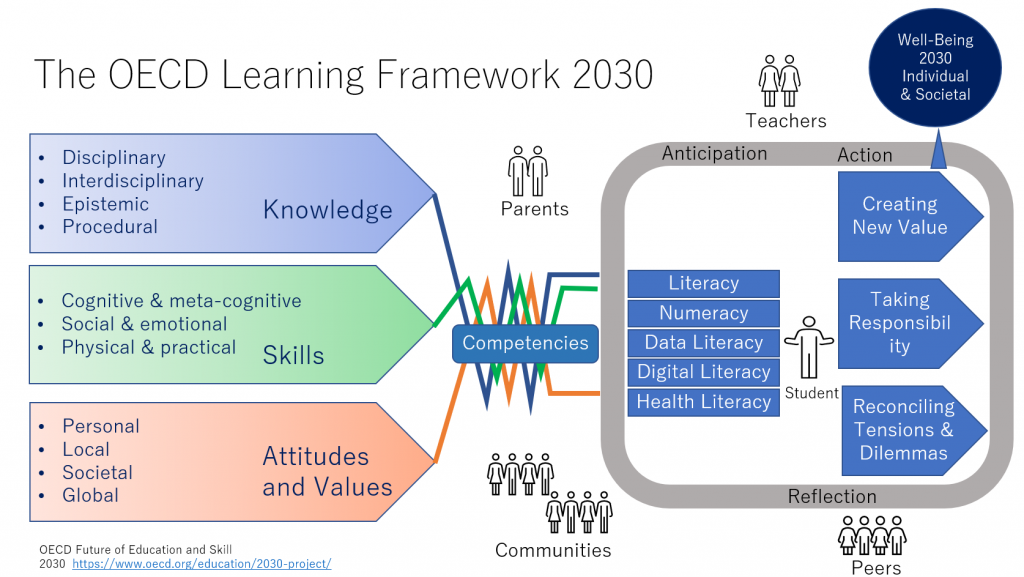
Bloom’s Taxonomyの現在のバージョンでは、remember – understand – apply – analyze – evaluate – create 記憶する – 理解する – 応用する(適用する) – 分析する – 評価する – 創造すると6段階に分類されています。(Vanderbilt UniversityのCenter for TeachingのBloom’s Taxonomyのページを参照)。
Understand理解するは下から二番目のレベルですが、Explain ideas or concepts: Classify, describe, discuss, explain, identify, locate, recognize, report, select, translateとなっています。つまり、考えや概念を説明する:分類する、記述する、議論する、説明する、同定する、探し出す、認識する、報告する、選択する、翻訳する、です。
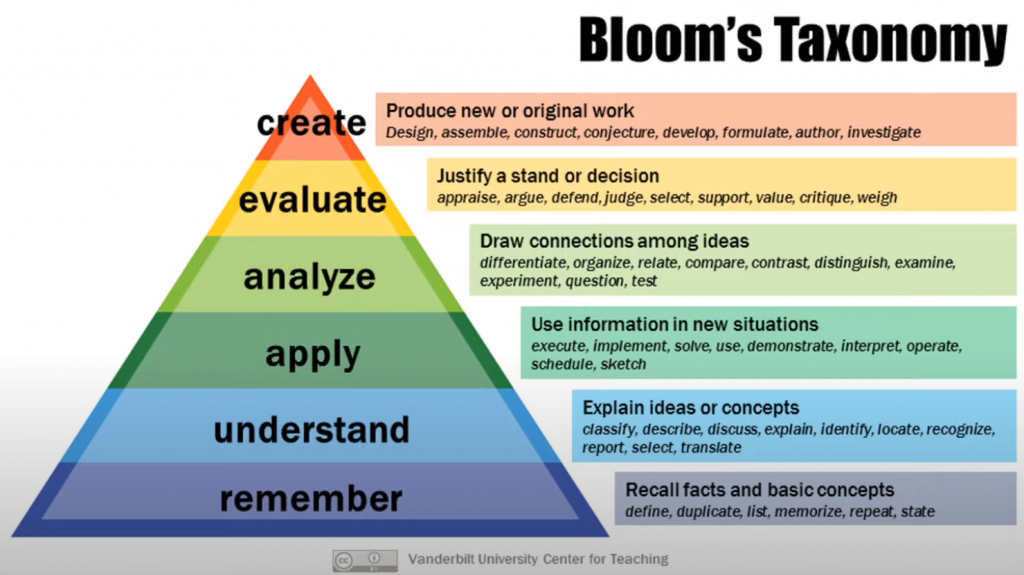
- Create 創造する – 新しいあるいはオリジナルの作品を作る:デザインする、組み立てる、構築する、推測する、開発する、策定する、著作する、調査・研究する
- Evaluate評価する – 立場あるいは決定を正当化する:吟味する、主張する、防御する、判断する、選択する、サポートする、価値を図る、批判する、重さをはかる
- Analyze 分析する – さまざまな考え(アイディア)をつなげる:鑑別する、整理する、関連付ける、比較する、区別する、検査する、実験する、質問する、テスト(試験)する
- Apply応用する – 新しい状況で情報を用いる:実行する、実装する、解決する、用いる、デモンストレーションする、解釈する、操作する、スケジュールを管理する、スケッチする
- Understand理解する – 考え、概念を説明する:分類する、記述する、議論する、説明する、同定する、見つけ出す、認識する、報告する、選択する、翻訳する
- Remember記憶する – 事実と基本的概念を思い出す:定義する、複製する、列挙する(リストアップ)、記憶する、繰り返す、述べる
カリキュラムあるいは学習プログラムを開発する際には、Taxonomyの理解が必要です。