Rはフリーの統計解析プラットフォームおよびプログラミング言語ですが、今は相当普及していて、アカデミアでも、使っている人が大勢いると思います。The Comprehensive R Archive NetworkではWindows版のみならずMac版、Linux版が提供されています。普段Windows10のノートPCを使うことが多いのですが、周りにはMacを使う人も多く、私自身も以前はMacを主に使っていました。今も時々iMacを使うことがあります。しばらくMacでRを使うことはなかったのですが、今日はMacでRの最新バージョンをインストールして、さらにXQuartzをインストールし、Bayesian推定に使われるJAGS (Just Another Gibbs Sampler)をインストールし、Rのパッケージであるrjagsとgemtcをインストールして、動かして見ました。
Network meta-analysisネットワークメタアナリシスにはすでに紹介したことのある、OpenBUGSが使われる事が多いのですが、ネットワークメタアナリシス用のRのパッケージであるgemtcとpcnetmetaはRからrjagsを介してJAGSを動かしてMarkov Chain Monte Carlo (MCMC) simulationを実行するようになっています。gemtcはコントラストベースcontrast-basedのネットワークメタアナリシス、pcnetmetaはアームベースarm-basedのネットワークメタアナリシスができるRのパッケージです。
Mac用のRはR-4.0.0.pkgでバージョンは4.0.0になっています(2020.5.22時点)。CRANのメインページから左サイドバーのMirrorsを開き、Japanのサイトのいずれかを選びます。Download R for (Mac) OS Xのページを開き、R-4.0.0.pkgをダウンドードして他のMac用ソフトと同じようにインストールします。続いて、同じページにあるXQuartzのリンクを開き、XQuartz-2.7.22.dmgをダウンロードしてインストールします。
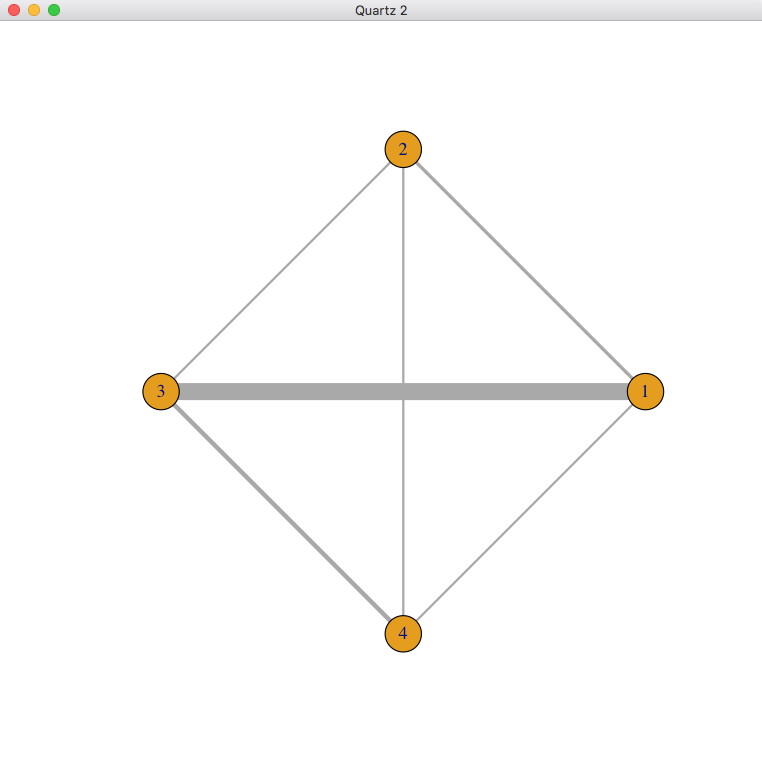
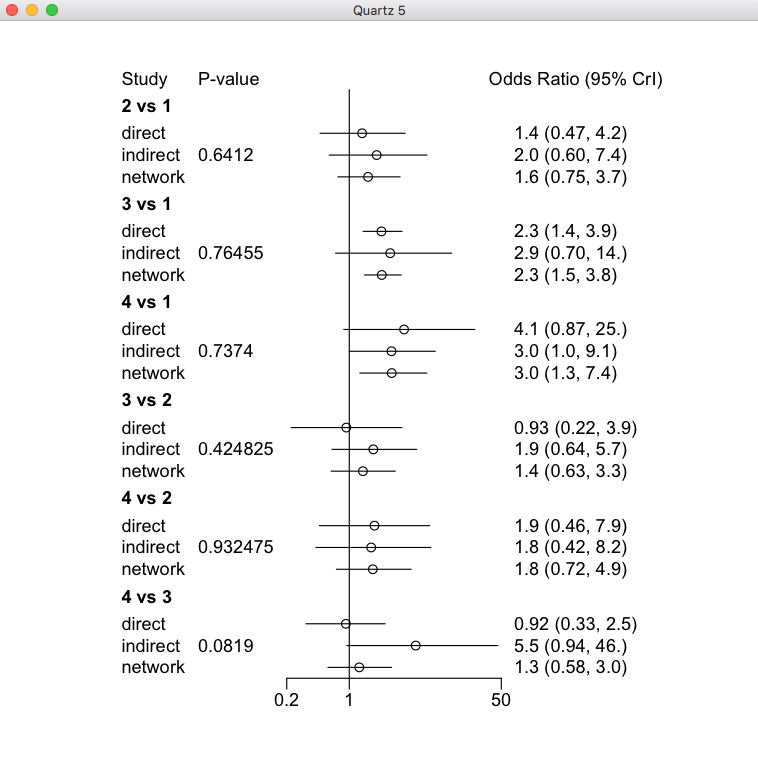
ネットワークグラフで閉じられたループがあると、直接比較の効果推定値だけでなく間接比較の効果推定値が得られる事がわかります。この例では、2と3を結ぶ線より、3と1を結ぶ線が太く、そこに多くの研究がある事が示されています。2と1を結ぶ線もあるので、2と3を比較する間接比較のデータが得られ、2と3を比較するネットワーク効果推定値には間接比較のデータがかなり影響するであろうと考えられます。実際、Node-splittingモデルのプロットを見ると、3 vs 2のnetwork estimateはindirectのestimateの影響で、オッズ比が0.93 (0.22-3.9)から1.4 (0.63-3.3)と大きな値になっています。
なお、この解析結果は#4-1のデータを#4-2のスクリプトで解析したものです。つまり、オッズ比の値が大きい方が望ましい結果です。Rankogramを見ると、治療4が最も治療効果が高い確率が最も高い事が言えます。しかし、上のNode-splittingモデルの4 vs 3の比較を見ると、間接比較の点推定値がかなり大きく、直接比較との間の検定ではP=0.0819ですが、バイアス、非直接性、非移行性intransitivityなどによって偏りが生じている可能性をチェックする必要があると言えます。
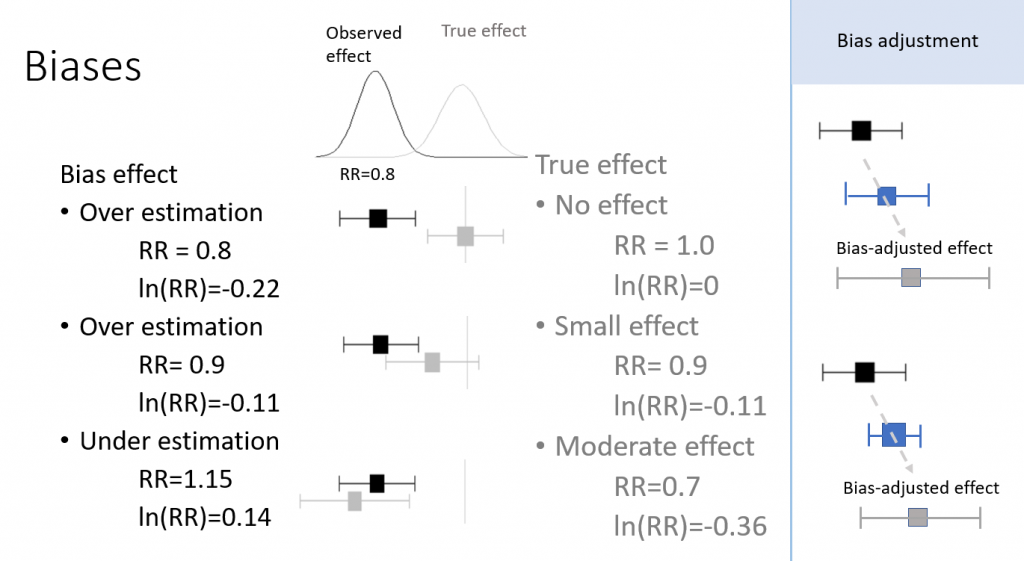
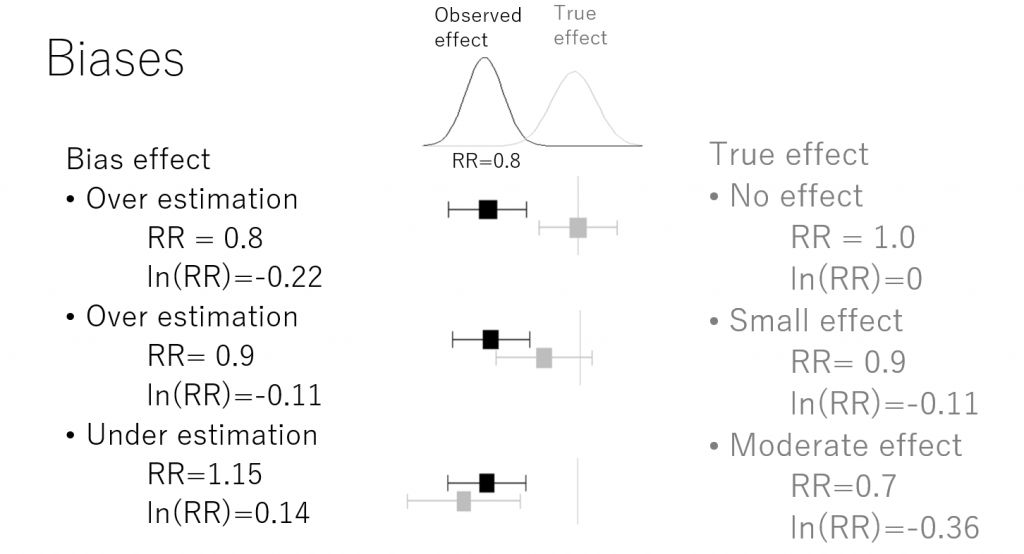
バイアスのモデル化についてはTurner RM 2009らのJournal of the Royal Statistical Society Series Aに発表された論文が精細な内容で参考になります。個別研究のバイアスドメイン・項目を評価しバイス調整をしたうえで、複数の研究のメタアナリシスの統合値を得る手法です。
メタアナリシスで得られた統合値の95%信頼区間の上限値(あるいは下限値)がNull effectあるいは臨床的閾値を超えるほどの大きさのバイアスの効果は簡単に計算できます。一般的に行われているバイアスリスクRisk of biasの評価結果でバイアスリスクが高く、バイアスの大きさがこの値よりも大きな効果を持っていると判断できる場合は、エビデンスの確実性が低くなると考えることができます。もし、そのようなバイアス効果の大きさがあり得ないほど大きいのであれば、ある程度のバイアスリスクがあっても、エビデンスの確実性は高いと考えることができるでしょう。
文献: Turner RM, Spiegelhalter DJ, Smith GC, Thompson SG: Bias modelling in evidence synthesis. J R Stat Soc Ser A Stat Soc 2009;172:21-47. PMID: 19381328
Turner RM, Lloyd-Jones M, Anumba DO, Smith GC, Spiegelhalter DJ, Squires H, Stevens JW, Sweeting MJ, Urbaniak SJ, Webster R, Thompson SG: Routine antenatal anti-D prophylaxis in women who are Rh(D) negative: meta-analyses adjusted for differences in study design and quality. PLoS One 2012;7:e30711. PMID: 22319580
Darvishian M, Gefenaite G, Turner RM, Pechlivanoglou P, Van der Hoek W, Van den Heuvel ER, Hak E: After adjusting for bias in meta-analysis seasonal influenza vaccine remains effective in community-dwelling elderly. J Clin Epidemiol 2014;67:734-44. PMID: 24768004
Dias S, Sutton AJ, Welton NJ, Ades AE: Evidence synthesis for decision making 3: heterogeneity–subgroups, meta-regression, bias, and bias-adjustment. Med Decis Making 2013;33:618-40. PMID: 23804507
Thompson S, Ekelund U, Jebb S, Lindroos AK, Mander A, Sharp S, Turner R, Wilks D: A proposed method of bias adjustment for meta-analyses of published observational studies. Int J Epidemiol 2011;40:765-77. PMID: 21186183
Wilks DC, Mander AP, Jebb SA, Thompson SG, Sharp SJ, Turner RM, Lindroos AK: Dietary energy density and adiposity: employing bias adjustments in a meta-analysis of prospective studies. BMC Public Health 2011;11:48. PMID: 21255448
Wilks DC, Sharp SJ, Ekelund U, Thompson SG, Mander AP, Turner RM, Jebb SA, Lindroos AK: Objectively measured physical activity and fat mass in children: a bias-adjusted meta-analysis of prospective studies. PLoS One 2011;6:e17205. PMID: 21383837
Schnell-Inderst P, Iglesias CP, Arvandi M, Ciani O, Matteucci Gothe R, Peters J, Blom AW, Taylor RS, Siebert U: A bias-adjusted evidence synthesis of RCT and observational data: the case of total hip replacement. Health Econ 2017;26 Suppl 1:46-69. PMID: 28139089
Doi SA, Barendregt JJ, Onitilo AA: Methods for the bias adjustment of meta-analyses of published observational studies. J Eval Clin Pract 2013;19:653-7. PMID: 22845171
McCarron CE, Pullenayegum EM, Thabane L, Goeree R, Tarride JE: Bayesian hierarchical models combining different study types and adjusting for covariate imbalances: a simulation study to assess model performance. PLoS One 2011;6:e25635. PMID: 22016772
McCarron CE, Pullenayegum EM, Thabane L, Goeree R, Tarride JE: The importance of adjusting for potential confounders in Bayesian hierarchical models synthesising evidence from randomised and non-randomised studies: an application comparing treatments for abdominal aortic aneurysms. BMC Med Res Methodol 2010;10:64. PMID: 20618973
Phillippo DM, Dias S, Welton NJ, Caldwell DM, Taske N, Ades AE: Threshold Analysis as an Alternative to GRADE for Assessing Confidence in Guideline Recommendations Based on Network Meta-analyses. Ann Intern Med 2019;170:538-546. PMID: 30909295
Caldwell DM, Ades AE, Dias S, Watkins S, Li T, Taske N, Naidoo B, Welton NJ: A threshold analysis assessed the credibility of conclusions from network meta-analysis. J Clin Epidemiol 2016;80:68-76. PMID: 27430731
Phillippo DM, Dias S, Ades AE, Didelez V, Welton NJ: Sensitivity of treatment recommendations to bias in network meta-analysis. J R Stat Soc Ser A Stat Soc 2018;181:843-867. PMID: 30449954
2019年にAnnals of Internal MedicineにPhillippo DMらからネットワークメタアナリシスによるエビデンスの確実性からさらに臨床決断へのバイアスの影響を評価する方法について新しい手法が報告されました(1)。GRADE (Grading of Recommendations Assessment, Development and Evaluation)のエビデンス総体の確実性の評価方法(2, 3)と比較した結果が述べられています。
Phillippo DMらの論文は、もともと2016年に発表された同じグループのCaldwell DMらの論文(4)がもとになっています。さらに、2018年にはJournal of Royal Statistical SocietyのSeries AにPhillippo DM, Dias S, Ades AEらの論文(5)として発表されています。Journal of Royal Statistical Societyには2009年にTurner RMらのバイアスの定量的モデル化の論文(6)が発表されており、当然のことながら引用されています。
文献: (1) Phillippo DM, Dias S, Welton NJ, Caldwell DM, Taske N, Ades AE: Threshold Analysis as an Alternative to GRADE for Assessing Confidence in Guideline Recommendations Based on Network Meta-analyses. Ann Intern Med 2019;170:538-546. PMID: 30909295 (2) Guyatt G, Oxman AD, Sultan S, Brozek J, Glasziou P, Alonso-Coello P, Atkins D, Kunz R, Montori V, Jaeschke R, Rind D, Dahm P, Akl EA, Meerpohl J, Vist G, Berliner E, Norris S, Falck-Ytter Y, Schünemann HJ: GRADE guidelines: 11. Making an overall rating of confidence in effect estimates for a single outcome and for all outcomes. J Clin Epidemiol 2013;66:151-7. PMID: 22542023 (3) Balshem H, Helfand M, Schünemann HJ, Oxman AD, Kunz R, Brozek J, Vist GE, Falck-Ytter Y, Meerpohl J, Norris S, Guyatt GH: GRADE guidelines: 3. Rating the quality of evidence. J Clin Epidemiol 2011;64:401-6. PMID: 21208779 (4) Caldwell DM, Ades AE, Dias S, Watkins S, Li T, Taske N, Naidoo B, Welton NJ: A threshold analysis assessed the credibility of conclusions from network meta-analysis. J Clin Epidemiol 2016;80:68-76. PMID: 27430731 (5) Phillippo DM, Dias S, Ades AE, Didelez V, Welton NJ: Sensitivity of treatment recommendations to bias in network meta-analysis. J R Stat Soc Ser A Stat Soc 2018;181:843-867. PMID: 30449954 (6) Turner RM, Spiegelhalter DJ, Smith GC, Thompson SG: Bias modelling in evidence synthesis. J R Stat Soc Ser A Stat Soc 2009;172:21-47. PMID: 19381328
下の図を見て、バイアスの効果についてちょっと考えてみてください。
Bias effects. RR: Risk Ratio; Log (Natural logarithm) of RR normally distribute and are additive, while on ratio scale RR is multiplicative.