Popay, J.,et al. : Guidance on the conduct of narrative synthesis in systematic reviews. A product from the ESRC (Economic and Social Research Council) methods programme Version, 2006.ではこのように述べられています。Link
レビューをめぐる用語はたくさんあります。以前SWiM (Synthesis without meta-analysis)について紹介したことがありますが、それ以外にも以下のような用語があります。
Systematic reviewはInstitute of Medicine (IOM)(現National Academy of Medicine, NAM)の定義では、「特定の問題に絞って、類似したしかし別々の研究の知見を見つけ出し、選択し、評価し、まとめるために、明確で計画された科学的方法を用いる科学的研究。別々の研究からの結果の定量的統合(メタアナリシス)を含むことも含まないこともある」とされています。”明確で計画された科学的方法を用いる”という点から、一定の枠組みで一定の手順で複数の研究をまとめるということが重視され、それに合わせるのが難しい課題はSystematic reviewの対象から外される傾向が生まれてしまいます。その結果、医療における意思決定に、確実性の低いエビデンスは活用されないことになってしまいます。
Systematic reviewの本質は何か?よく考えることが必要だと思います。Cochrane RoB 2を用いたからSystematic review、GRADEアプローチを用いたからSystematic review、IOMのFinding What Works in Healthcare: Standards for Systematic Reviewsに従ったからSystematic reviewだというわけでないでしょう。いずれの場合も、主観的な判断が必要な部分がありますし、再現性が保証されるわけではありません。
続けて2行目を実行すると、感度、特異度の統合値と95%信頼区間、統合値のDiagnostic Odds Ratio (DOR)、陽性尤度比、陰性尤度比とこれらの95%信頼区間およびI二乗値と、RevManへ渡すことによって、SORC曲線を描くパラメータを出力します。それとともにクリップボードにもこれらの値を格納するので、Excelなどに貼り付けることができます。
メタアナリシスの部分のスクリプトは以下の通りです。
ma_res = glmer(formula=cbind(true, n – true ) ~ 0 + sens + spec + (0+sens + spec|Study_ID), data=Y, family=binomial)
文献: Whiting PF, Rutjes AW, Westwood ME, Mallett S, Deeks JJ, Reitsma JB, Leeflang MM, Sterne JA, Bossuyt PM; QUADAS-2 Group. QUADAS-2: a revised tool for the quality assessment of diagnostic accuracy studies. Ann Intern Med. 2011 Oct 18;155(8):529-36. doi: 10.7326/0003-4819-155-8-201110180-00009. PMID: 22007046.
Cochrane Handbook for Systematic Reviews of Diagnostic Test Accuracy version 2.0, 2022. Link
DTA MAに関する書籍としては、Biondi-Zoccai G ed. Diagnostic Meta-Analysis: A Useful Tool for Clinical Decision-Making. Springer, Cham, Switzerlandが包括的な内容で、有用と思います。また、Cochrane Handbook for Systematic Reviews of Diagnostic Test Accuracyは2022年度Version 2が発表されており、包括的な内容で、SAS、R用のスクリプトが具体的に解説されており、有用だと思います。
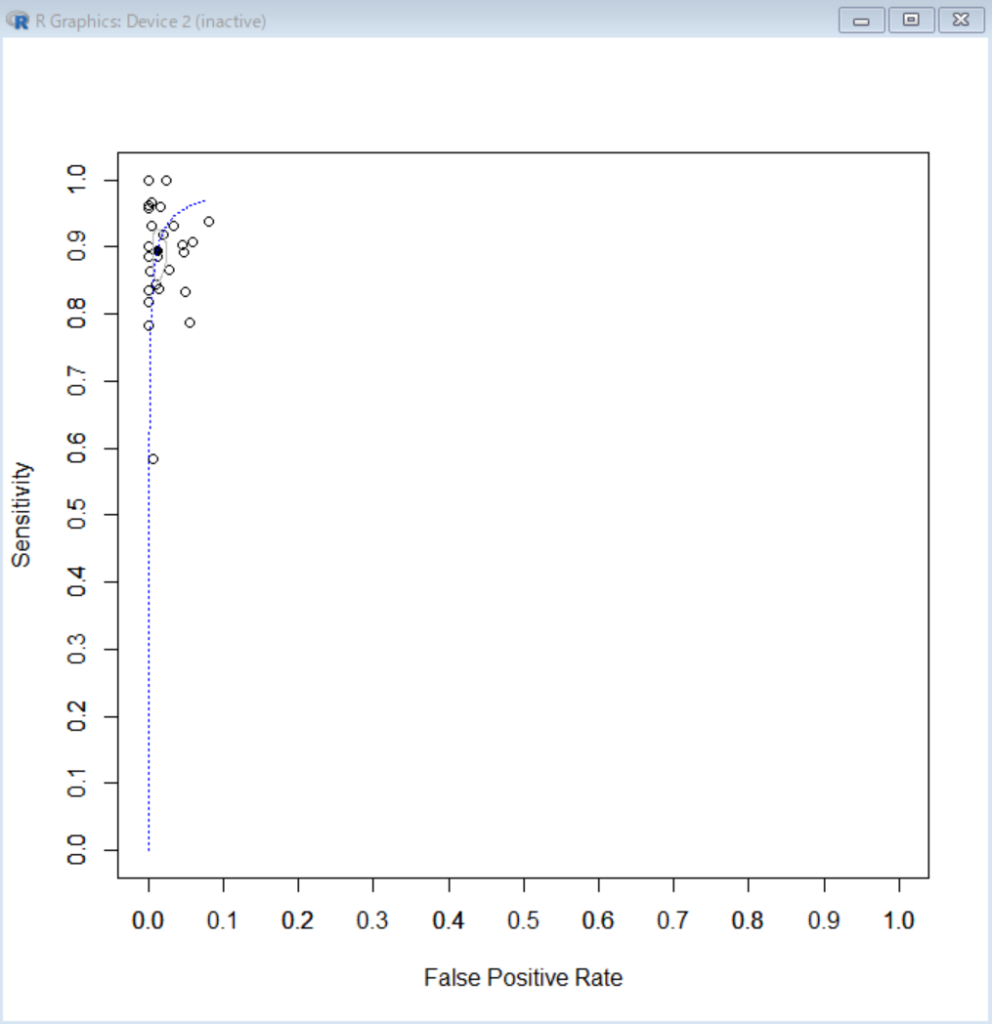
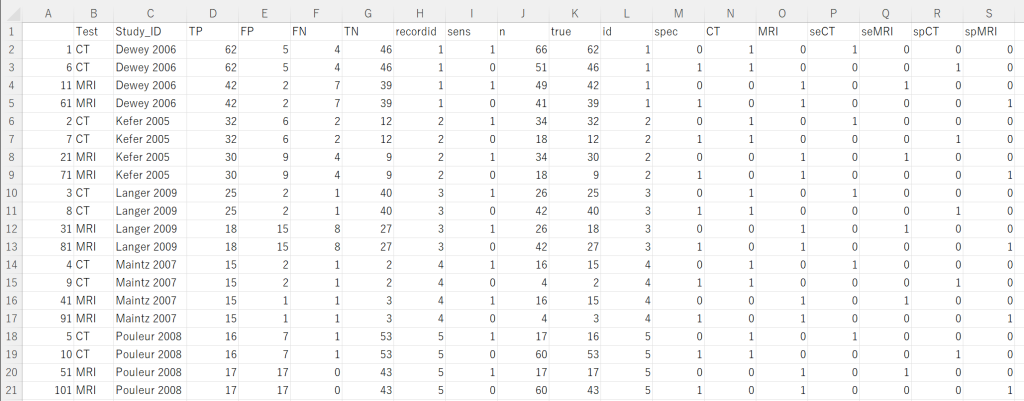
Cochrane Handbook for Systematic Reviews of Diagnostic Test AccuracyのAppendix 14では同じ対象者でCTとMRIを施行し、診断能を比較した5つの研究のDTA MAの例が記載されており、Rのlme4パッケージのglmer()関数を用いて、GLMM (Generalized Linear Mixed Effects Model)で二項分布による回帰モデルを用いています。Appendix 12では同じ対象者で二つの診断法を実施したのではなく、別の対象者でそれぞれの診断法の感度・特異度を測定した研究をもとに、二つの診断法の診断能を比較するための解析法が記載されています。こちらは、間接的な比較という表現が使われており、同じ対象者で直接比較した研究も含めて解析できる方法が示されています。
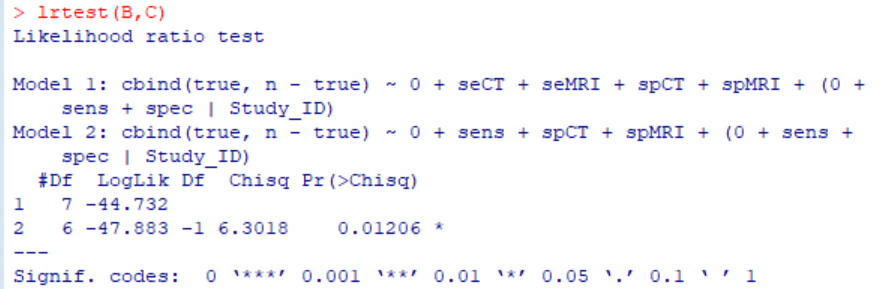
###Comparison of sensitivity and specificity between two tests done in the same subjects### ###Random-effects meta-analysis with bivariate model using binomial distribution### library(lme4) library(lmtest) ###Y is a data frame as shown in Fig. 1### (B = glmer(formula=cbind(true, n – true) ~ 0 + seCT + seMRI + spCT + spMRI + (0+sens + spec|Study_ID), data=Y, family=binomial)) (C = glmer(formula=cbind(true, n – true) ~ 0 + sens + spCT + spMRI + (0+sens + spec|Study_ID), data=Y, family=binomial)) ###Is there a statistically significant difference in sensitivity between CT and MRI? lrtest(B,C)
###Is there a statistically significant difference in specificity between CT and MRI? lrtest(B,D)
文献: Chu H, Cole SR: Bivariate meta-analysis of sensitivity and specificity with sparse data: a generalized linear mixed model approach. J Clin Epidemiol 2006;59:1331-2 author reply 1332-3. doi: 10.1016/j.jclinepi.2006.06.011 PMID: 17098577
Reitsma JB, Glas AS, Rutjes AW, Scholten RJ, Bossuyt PM, Zwinderman AH: Bivariate analysis of sensitivity and specificity produces informative summary measures in diagnostic reviews. J Clin Epidemiol 2005;58:982-90. doi: 10.1016/j.jclinepi.2005.02.022 PMID: 16168343
Rutter CM, Gatsonis CA: A hierarchical regression approach to meta-analysis of diagnostic test accuracy evaluations. Stat Med 2001;20:2865-84. PMID: 11568945
Harbord RM, Deeks JJ, Egger M, Whiting P, Sterne JA: A unification of models for meta-analysis of diagnostic accuracy studies. Biostatistics 2007;8:239-51. doi: 10.1093/biostatistics/kxl004 PMID: 16698768
Arends LR, Hamza TH, van Houwelingen JC, Heijenbrok-Kal MH, Hunink MG, Stijnen T: Bivariate random effects meta-analysis of ROC curves. Med Decis Making 2008;28:621-38. doi: 10.1177/0272989X08319957 PMID: 18591542