“Evidence-Based Medicine: How to practice and teach EBM”という本はSackett DLが第一著者の初版が1997年に出版されました。その後、2000, 2005, 2011年と改訂版が出版され、 2019年に第5版が出版されました。もうSackett先生の名前は著者に入ってませんが、Dedication: This book is dedicated to Dr. David L. Sackett.と書かれています。Sackett先生は2015年に他界されました。
Straus SE, Glaszious P, Richardson WS, Haynes RB: Evidence-Based Medicine: How to practice and teach EBM. (5th edition) 2019, Elsevier Ltd., New York.です。
初版から22年経過し、その間には社会に、医療に、医学に大きな変化がありました。特にICT (Information and Communication Technology)の発展・普及、患者中心の医療、さまざまな疾患の病態の解明と新しい診断法・治療法の開発と実用化、介護・医療制度改革、医学研究や医療の情報量の増大、等々です。
EBMは医療者個人の医療の実践体系ととらえられ、個人でクリニカルクエスチョンに基づいて、文献検索を行い、関連のある研究論文を見つけ、批判的吟味をして、エビデンスを活用するというステップで考えられてきたと思います。しかし、医療情報が莫大になり、検索は簡単にできても、関連のある文献を選定する作業に時間がかかりすぎるようになってきました。さらに、それを読んでまとめるとなると非常に時間がかかり、ひとりでできる作業ではなくなってきています。医療でEBMを実践することが、個人ではできない時代になりつつあるのではないでしょうか?
下の図に示すP5のレベル3の診療ガイドライン、レベル4のレベル1~3をまとめたもの、などを情報源として用いれば十分やっていけるという考えもあるかもしれません。レベル4はUpToDate, DynaMed, Medscape Reference, Best Practice, Micromedexなどがリストアップされています。
”医療上の疑問が生じた際に、タイムリーに科学的に妥当な、最新の情報を、短時間で理解できる内容にまとめた形で、入手して、意思決定に適切に用いられるようにするにはどうすればいいのか?”それには、医師、看護師、薬剤師など医療提供者だけでは実現できません。医療提供者、医療利用者など当事者だけでなく、ICT技術者、ICT企業、出版社、クラウドサービス提供企業なども協働で参加しないとできないでしょう。
今後はレベル5のSystemsを追求すべきで、さらにエビデンス生成の分野も統合して、…こんな風に考えながら、このEBMの本のEBHC Pyramid 5を眺めているところです。
どんどん変わっていきますね。Take a “P5” approach to evidence-based information accessって書いてあるんですね。
P5というのが面白いでしょ。一番上の5.Systemsって最初何のことがわからなかったけど、これってGAFAが隆盛を誇っていることとも関係してるよね。そう思わない?P4 medicineというのもあるけど。 predictive, preventive, personalized, and participatoryって言うんだけれど。これは、Pyramid 5なんだ。
ハハハハ。面白い。Google, Apple, Facebook, Amazon!医療情報の検索はiPhoneからGoogleで、論文の内容はAIがまとめます、ドクター探しは、Facebookで、医療費の支払いもリブラで、お薬はAmazonで、ですか?それはどうかな?
でも彼らが本気で取り組めばできるんじゃないかな?資金も技術力もあるし、タレントを世界中から集められるし。

第4版では、Take a “6S” approach to evidence-based information accessになってますね。わかりやすくするために番号を付けると、一番上が(6) Systems: Computerized decision supportになってますよ。
次が、(5) Summaries: Evidence-based textbooks, (4) Synopses of syntheses: Evidence-based journal abstracts, (3) Syntheses: Systematic reviews, (2) Synopses of studies: Evidence-based journal abstracts, (1) Studies: Original journal articlesの順ですね。
こういうのは第1版、第2版には少なくともなかったね。
Synopsis、summary, abstract概要、抄録などを見ればいいのではないかと思えてしまうよね。他の人たちが批判的吟味を行ったその結果のまとめという意味だね。結論に至った過程を信用して。。自分の頭では考えないで。。
EBM実践のステップについても、Step 3にエビデンスの妥当性とインパクト(:効果の大きさ)の批判的吟味を行うことが述べられています。この”効果の大きさ”は意思決定には非常に重要な項目です。しかし、”患者の価値観に基づいてBenefit and harmあるいはBenefit and riskを明らかにして”というような表現はStep 4にはまだ取り上げられていません。

でもこれよくできてますね。しかも、これはずっと変わっていないですね。
わかる?Impact (size of the effect)って書いてあって、エビデンスの確実性、ここでは妥当性validity (closeness to the truth)って書いてあるんだけど、それの批判的吟味を重要と考え効果の大きさのことはあまり考えない人が多いので、ここのところはいいなって思ってるんだ。
そうですよね
個人レベルでのBenefit and harm益と害の大きさを判断するには概要や抄録の結論だけでは無理ですよ。health literacyヘルスリテラシーとnumeracyニューメラシーの理解の深さがどこまで求められるかよく考えないと。
今後は、SynopsisやSummaryが個人個人の意思決定に必要な数値データを提示する必要があるんじゃないかな?
EBMの定義については、以下の様になっています。(下の方の3つの項目は自分の解釈です。)
これは巻末の用語解説に書いてあるもので、最初のIntroductionの冒頭にも”What is evidence-based medicine?”と書いてあって、”Evidence-based medicine (EBM) requires integration of the best research evidence with our clinical expertise and our patient’s unique values and circumstances.”なんて書いてあるんですよ。これは”EBMは最善の研究エビデンスと我々の臨床的専門的技能・知識と患者さん固有の価値と状況と統合することを必要とする”ということだけを述べています。
ふーん、なるほど。最初の部分がないんですね。最初の部分も重要だと思うんですけどね。状況というのはその患者さんの置かれた状況のことらしいですね。
このあたりの記述もずっと変わっていないですね。

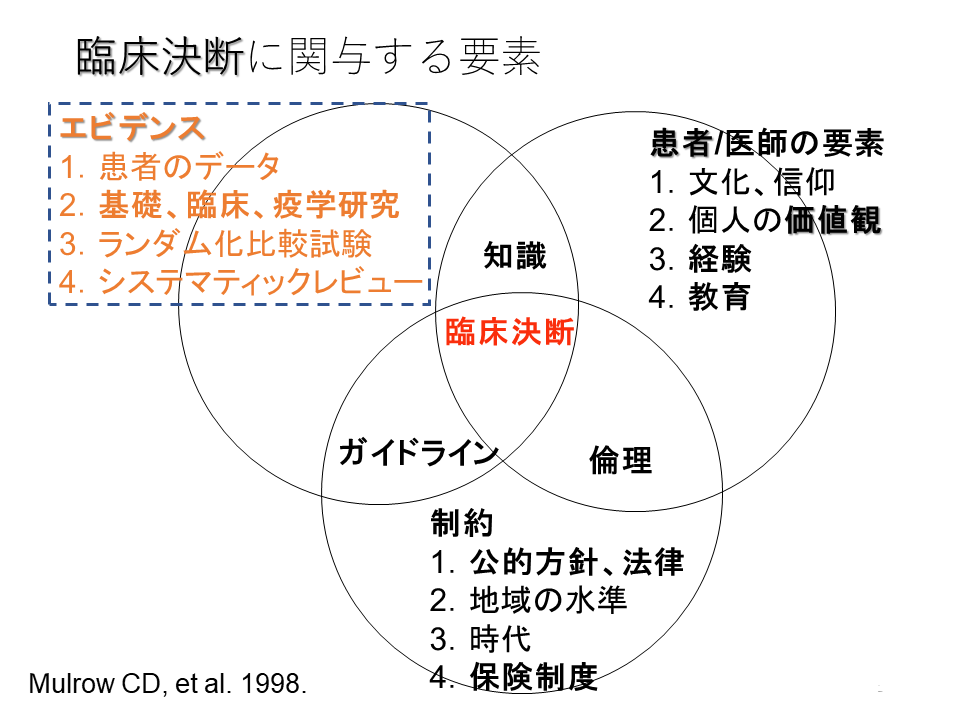
1998年のMulrow CEの臨床決断に関与する要素にはほぼ同じような内容が示されていました。
さて、最後にForeground questionsとBackground questionsについてわかりやすい説明があります。今回はこれで最後です。