今日は、診断の統計学の基礎について解説したいと思います。
このウェブページのURL: https://info.zanet.biz/lec/stat/stat_diagnosis/one.htm スライドのQRコードからも開けます。
YouTubeチャンネル IZ Stat: https://www.youtube.com/channel/UCqzzJbfQwKDvValptCAM4gg
Microsoft Edgeの音声で読み上げる 解説動画
iPadのSafariでMind mapからスライドと解説を開き音声読み上げ 解説動画
Rのインストール、パッケージのインストール、スクリプト実行などの解説動画があります。
*iPadではEdgeを使うこともできます。Edgeでの音声読み上げには、右上の・・・をタップして、“音声で読み上げる“をタップします。読み上げ開始、一時停止、早送り、巻き戻しなどのボタンがあるツールバーが表示されます。途中で移動したいときは、移動先の文章部分を長押しします。音声オプションから音声を変更したり、スピードを変えることもできます。
このページの左上のパレットの左側のボタンは目次を表示し、スライドのタイトル部分をクリックすると、各スライドへ移動できます。右側のボタンをクリックすると関連したスライドへのリンクが表示されます。なお、関連スライドは一部のスライドにしかありません。
こちが学習目標です。
最初にAnalytic framework 分析的枠組みにおける診断の位置づけについて解説します。
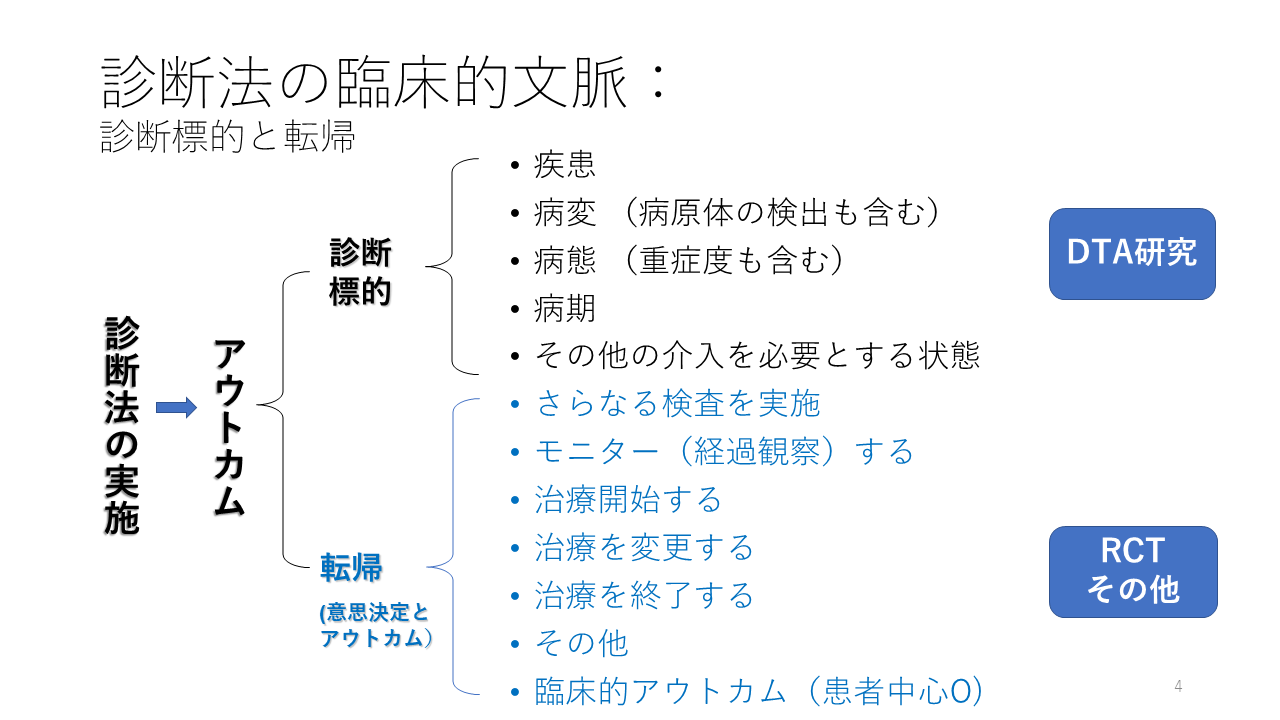
診断法の実施のアウトカムは何か考えてみましょう。診断標的と転帰とは何でしょうか?
診断標的とは診断法で検出する対象です。例えば、診断標的が疾患であれば、ある疾患に罹患していることが分かる。つまり、診断がつくことになります。
すでにどのような疾患に罹患しているかわかっている場合に、どのような病変が起きているのかを知ることが診断標的になる場合もあります。例えば、胸部CTスキャンで肺炎の診断がついて、PCRで病原体がSARS-COV-2であることが分かるというような場合です。
その他には、病態、重症度、病期、その他の介入を必要とする状態が診断標的になります。
診断標的をいかに正確に検出できるかを分析する研究は、Diagnostic Test Accuracy (DTA) studies、診断精度研究と呼ばれます。
ここでは、転帰と呼んでいますが、診断法の実施は意思決定とさらにその下流の臨床的アウトカムに影響を与えます。
ある診断法を実施した結果、診断が確定しないこともよくあることです。その場合、他の検査を実施したり、経過観察したりすることになります。
診断法の結果で、治療を開始する意思決定が行われたり、治療を変更することが行われたり、治療を終了する場合もあります。
臨床的アウトカム、あるいは患者中心アウトカムに対する影響を直接解析するランダム化比較試験が行われる場合もあります。たとえば、マンモグラフィーを2年おきに実施し、乳癌による死亡が抑制されるかどうかを分析するランダム化比較試験などがそれに該当します。
診断法の転帰への影響を分析する研究は実施が難しいことが多く、特にランダム化比較試験は限定的にしか行われていないのが実情です。
分析的枠組みは、「アウトカムと関連付けながら、臨床的概念、エビデンスおよび対象集団をリンクし、定義づけるエビデンスモデルのひとつ」とされています。
臨床的概念とは、疾患、病態、診断法の実施・治療などの介入、害、治療の効果、診断精度、予後予測などの事です。費用(医療費)や負担も分析的枠組みの要素に含めることができます。
また、因果経路と呼ばれることもあり、コンセプトの枠組み、理論的枠組みなどと関係があります。実線矢印は因果関係、点線矢印は関連があることを示します。
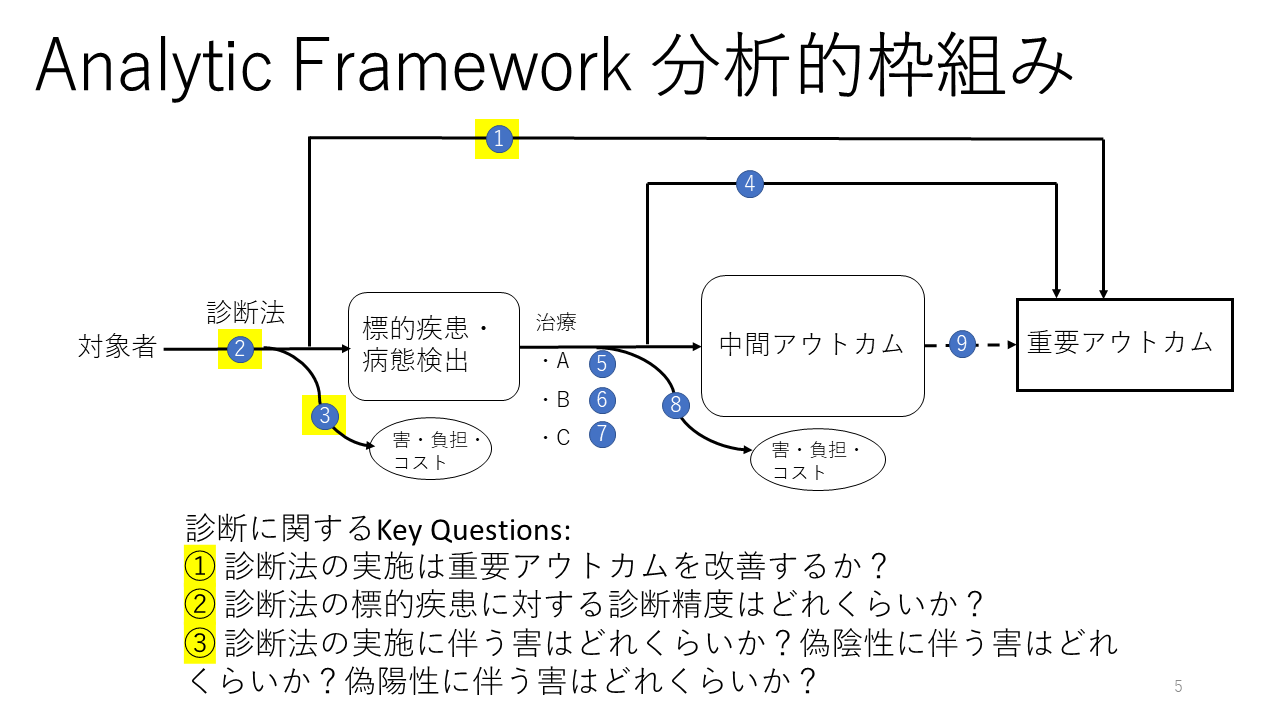
分析的枠組みを作成する際の参考になるよう、分析的枠組みのテンプレートを示します。
これは、一般化できるように図の部分を残したもので、中間アウトカムはひとつだけにしてありますが、必要に応じて追加します。
数字を設定してある、それぞれのポイントで以下の様なキークエスチョンが考えられます。これらのキークエスチョンからPICOの形式でクリニカルクエスチョンを作成します。中間アウトカムと重要アウトカムはひとつとは限りません。一方、害・負担・コストのアウトカムは別に設定されます。
① 診断法の実施は重要アウトカムを改善するか?
② 診断法の標的疾患に対する診断精度はどれくらいか?
③ 診断法の実施に伴う害はどれくらいか?偽陰性に伴う害はどれくらいか?偽陽性に伴う害はどれくらいか?
④ 標的疾患の患者で治療A,B,Cの内、重要アウトカムに対する効果が最も高いのはどれか?/標的疾患の患者で正味の益が最大の治療はA,B,Cの内どれか?
⑤ 標的疾患の患者で治療Aは重要アウトカムをどれくらい改善するか?/標的疾患の患者で治療Aの益と害はどれくらいか?
⑥ 標的疾患の患者で治療Bは重要アウトカムをどれくらい改善するか?/標的疾患の患者で治療Bの益と害はどれくらいか?
⑦ 標的疾患の患者で治療Cは重要アウトカムをどれくらい改善するか?/標的疾患の患者で治療Cの益と害はどれくらいか?
⑧ 標的疾患の患者に対して治療A,B,Cの害はどれくらいか?
⑨ 標的疾患の患者で中間アウトカムの改善から重要アウトカムの改善をどれくらい予知できるか?
これらの内①、②、③が診断に関するキークエスチョンです。
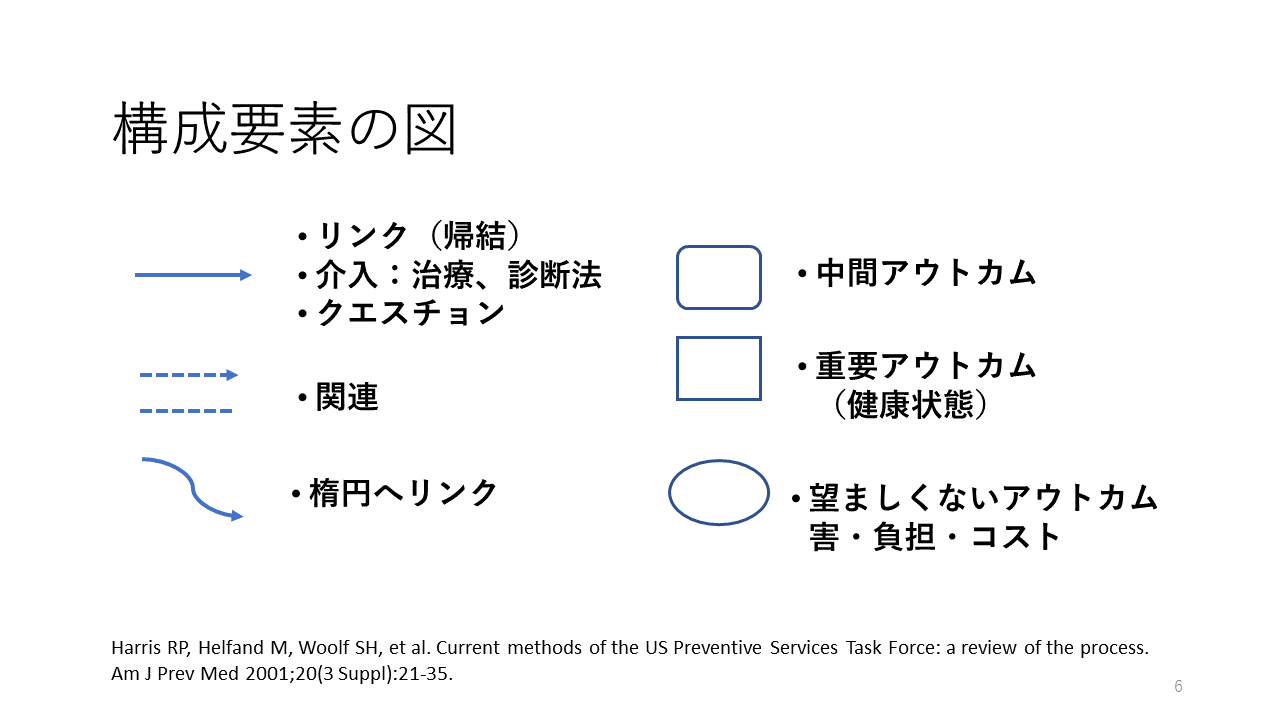
分析的枠組みで用いられる、図の要素を示します。
開始点は対象者を表す記述で、通常枠線で囲ったりせず、文字列だけを用います。最終点は重要アウトカムで、通常は患者中心のアウトカムを四角の中に記述します。
開始点と最終点の間に、中間アウトカムが配置され、角の丸い四角を用いて表現されます。
これらの要素が実線または点線の矢印でリンクされます。実線の矢印は、起点の側が先に起きる事象で矢じりの側がその帰結を示します。点線の矢印は起点の側と矢じりの側に関連があることを示します。たとえば、中間アウトカムと重要アウトカムは点線の矢印でリンクされます。単なる点線が関連を示すために用いられる場合もあります。
治療、診断法の実施などの介入(治療的介入/診断的介入)は実線の矢印の上に配置されます。複数の介入がある場合は、リスト形式で矢印の上下に配置されます。
診断法の実施の結果は中間アウトカムとして扱うことができます。
介入に伴う害・負担・コストは楕円形で表示されます。そして、それらへのリンクは実線の曲線を用いて表します。
そして、キークエスチョンはこれらのリンクを示す線の上に置かれることになります。
システマティックレビューのためのAnalytic framework(解説動画 YouTube)がIZ Statにあります:https://www.youtube.com/channel/UCqzzJbfQwKDvValptCAM4gg
診断法に関するクリニカルクエスチョンはいくつかの類型に分類できます。クリニカルクエスチョンはリサーチクエスチョンとしてとらえても構いません。
ここに5つの類型を上げていますが、多くのクリニカルクエスチョンは①または④になります。すなわち、診断精度研究、ランダム化比較試験で回答が得られるであろうクリニカルクエスチョンが、診断法に関するクリニカルクエスチョンの大部分を占めています。
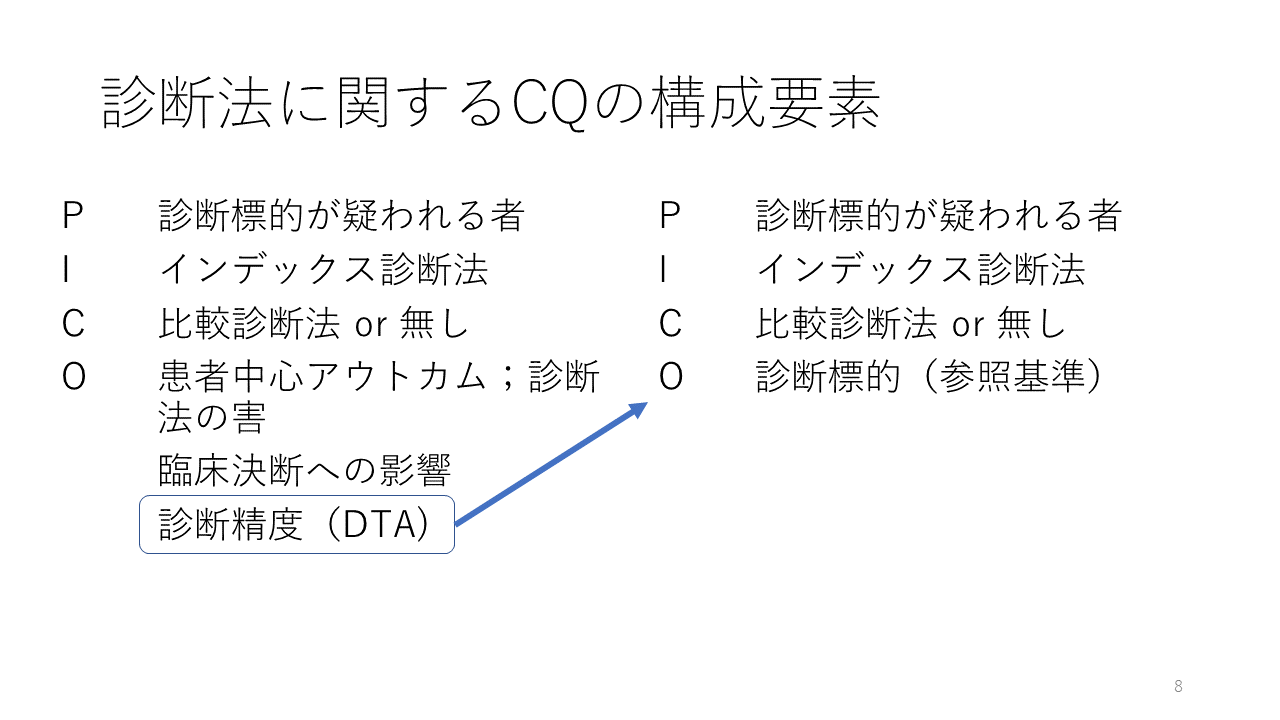
クリニカルクエスチョン CQはPICOの要素から構成されます。
Population, Intervention, Comparator, Outcomeの4つの要素です。
Pは診断標的が疑われる者になります。Iはインデックス診断法になります。インデックス診断法とは、その臨床的効果や診断精度を知りたい研究対象の診断法の事です。
Cはインデックス診断法と比較される診断法が設定される場合は、その優劣を知りたい場合です。比較診断法が設定されず、インデックス診断法の診断精度が分析される場合もあります。
Oはランダム化比較試験のような場合であれば、患者中心アウトカムや診断法の害が設定されます。臨床決断/意思決定への影響がアウトカムとして設定される場合もあります。そして、診断精度研究の場合は、診断精度(Diagnostic Test Accuracy, DTA)がアウトカムに設定されます。
診断精度研究の場合であれば、右側に示すように、Oに参照基準で検出される診断標的を設定し、インデックス診断法の診断精度を明らかにしたり、比較診断法と診断精度を比較することが行われます。
なお、診断能Diagnostic performanceという言葉が診断精度と同じ意味で用いられることもあります。
診断法に関する研究、特に診断精度研究について解説します。
先ほど診断法の臨床的文脈の説明の中で、診断法実施のアウトカムについて、主に診断標的と転帰に分けられるという説明をしましたが、臨床的文脈の外側にも診断法実施のアウトカムは存在します。
このスライドではそれらをリストアップしています。
心理的反応というのは、診断法の結果を知ることで、安心したり、逆に不安になったり、というようなことが例として挙げられます。
法的、倫理的アウトカムというのは、感染症に罹患していることを知りながら、リスクある行動をとり、感染を拡大させるようなことが起きた場合に、問題になってきます。
さて、診断法研究のレベルは6つに分けられています。
新しい診断法が開発された場合のことを想像していただければ、理解できることではないかと思います。
今回の例では、②の段階まで進んだと言えるのではないかと思います。
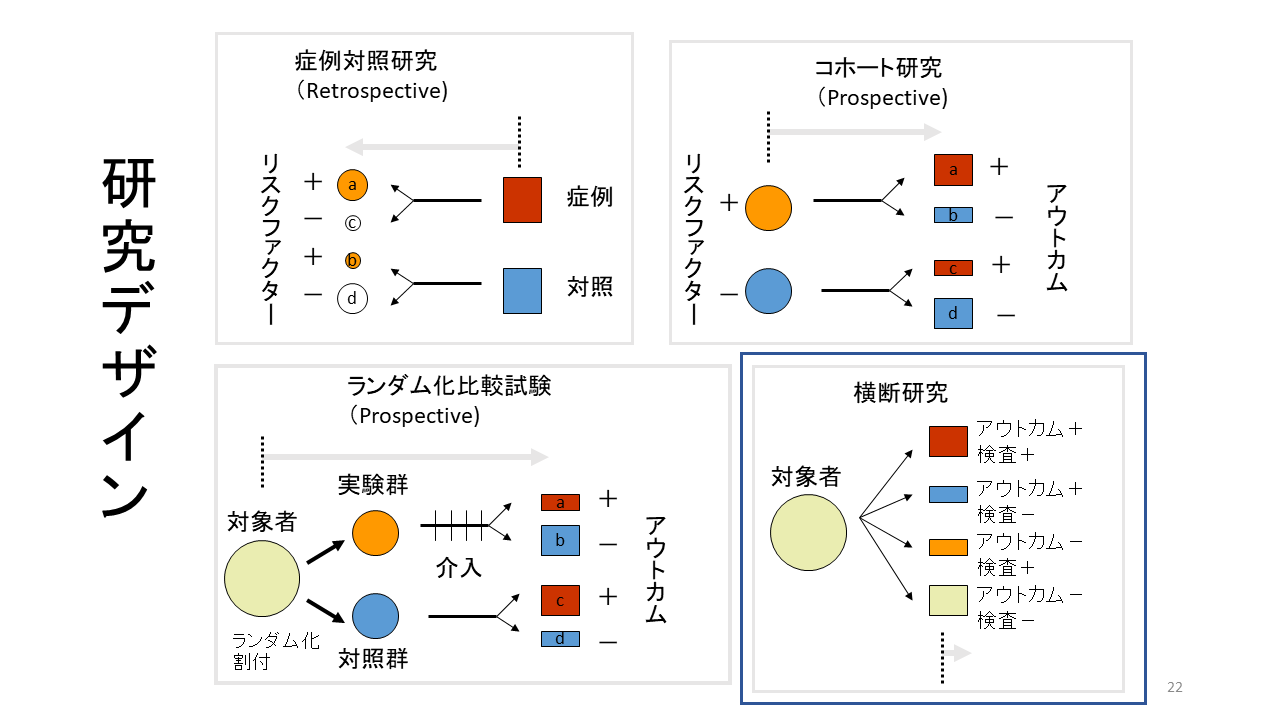
診断に関する研究は診断標的を持っているかどうかと、診断法の結果の関係を分析しますが、診断法実施の時点で診断標的はすでに起きているので、横断研究というデザインが適用されます。
一方、予後予測の研究は診断法実施の時点では、まだイベントが起きていません。時間経過の中で、遅れてイベントが発生します。したがって、横断研究ではなく、コホート研究、あるいは症例対照研究のデザイン、あるいはランダム化比較試験のデザインが適用されます。
予後予測は治療ベネフィットがある患者を同定することに使えます。例えば、LDLコレステロールを測定し、心血管系疾患のリスクが高いと予測できた場合、投薬によって、心血管系疾患の発症を予防するというような場合です。この場合、心血管系疾患はまだ発症していない時点で、診断法を実施することになります。
診断精度研究はコホート型研究と症例対照型研究に分けられます。前者はSingle-gate study、後者はTwo-gate studyとも呼ばれます。
その結果を実際の臨床に適用できるのは、前者のSingle-gate studyです。Single-gate studyでは、何らかの共通の症状を有した対象者でインデックス診断法を実施し、その後、同じ参照基準で診断標的を有する者とそうでない者に分類されます。そして、インデックス診断法の結果と参照基準の結果の関係を分析します。
もし、診断標的を有しない者を共通の症状とは関係なく、場合によっては健常者を含め、インデックス検査を実施し、その結果から偽陽性率あるいは特異度を計算すると、実際の臨床での対象者の特異度とは乖離してきます。
感度・特異度については、後程解説します。
コクランの診断精度研究のシステマティックレビュー/メタアナリシスでは、Single-gate studyのみを対象にすることになっています。
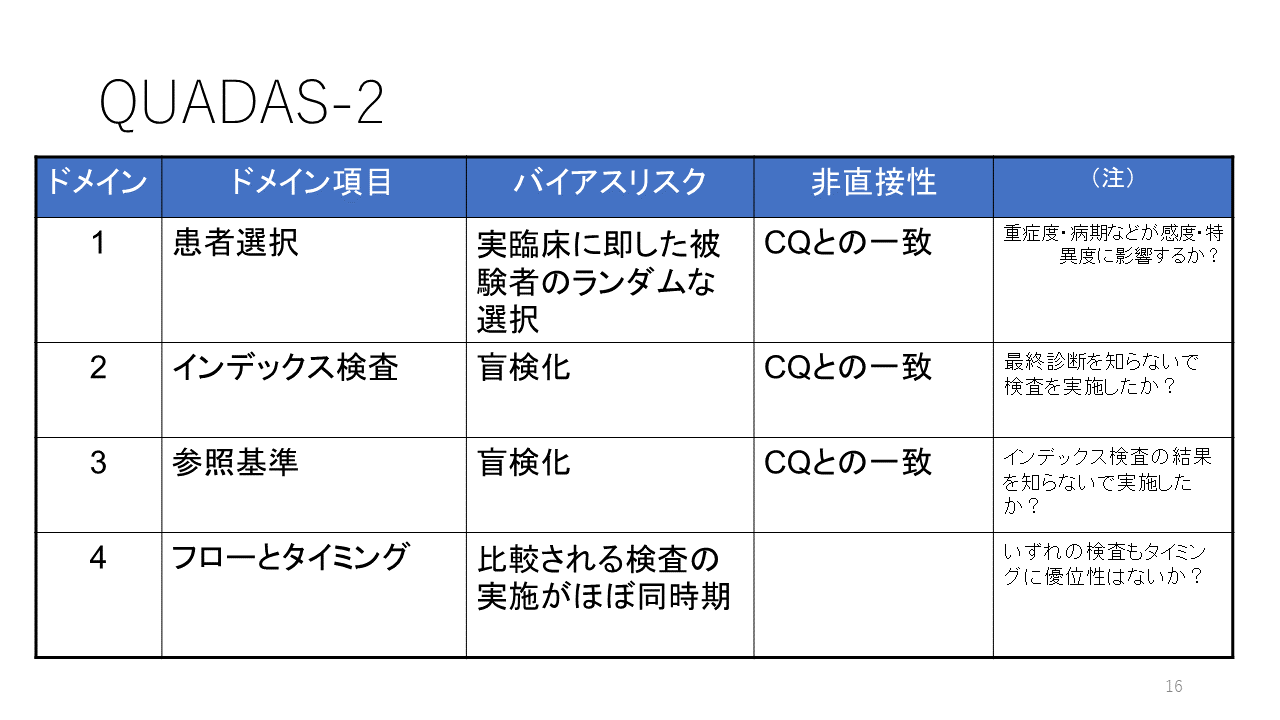
診断に関する研究の論文を書くときには、執筆ガイダンスSTARDを参照したほうがいいでしょう。また、診断精度研究の質の評価のためのツールQUADAS-2があるので、論文を本格的に読み込んだり、診断精度研究のシステマティックレビュー/メタアナリシスをする場合には、参照する必要があります。
STARD
Bossuyt PM, Reitsma JB, Bruns DE, Gatsonis CA, Glasziou PP, Irwig LM, Moher D, Rennie D, de Vet HC, Lijmer JG; Standards for Reporting of Diagnostic Accuracy. The STARD statement for reporting studies of diagnostic accuracy: explanation and elaboration. Ann Intern Med. 2003 Jan 7;138(1):W1-12. doi: 10.7326/0003-4819-138-1-200301070-00012-w1. PMID: 12513067. (https://pubmed.ncbi.nlm.nih.gov/12513067/ )
Cohen JF, Korevaar DA, Altman DG, Bruns DE, Gatsonis CA, Hooft L, Irwig L, Levine D, Reitsma JB, de Vet HC, Bossuyt PM. STARD 2015 guidelines for reporting diagnostic accuracy studies: explanation and elaboration. BMJ Open. 2016 Nov 14;6(11):e012799. doi: 10.1136/bmjopen-2016-012799. PMID: 28137831; PMCID: PMC5128957.
(https://pubmed.ncbi.nlm.nih.gov/28137831/ )
equator network: Enhancing the QUAlity and Transparency Of health ResearchのウェブサイトのSTARDに関するページ:
https://www.equator-network.org/reporting-guidelines/stard/
ここには、TRIPOD、CONSORT、PRISMA、その他の情報もあり。
QUADAS-2
Whiting PF, Rutjes AW, Westwood ME, Mallett S, Deeks JJ, Reitsma JB, Leeflang MM, Sterne JA, Bossuyt PM; QUADAS-2 Group. QUADAS-2: a revised tool for the quality assessment of diagnostic accuracy studies. Ann Intern Med. 2011 Oct 18;155(8):529-36. doi: 10.7326/0003-4819-155-8-201110180-00009. PMID: 22007046.
(https://pubmed.ncbi.nlm.nih.gov/22007046/ )
日本語訳:
Mindsサイト
(https://minds.jcqhc.or.jp/docs/minds/guideline/pdf/Utilization_QUADAS-2.pdf )
シグナリングクエスチョンが用意されています。
QUADAS-2は評価ドメインが4つあります。ここでは詳細は省略します。
小島原典子、森實敏夫、中山健夫、他:診断精度研究のバイアスリスク評価ツールQUADAS-2: a Revised Tool for the Quality Assessment of Diagnostic Accuracy Studies 2 の活用。Jpn Pharmacol Ther (薬理と治療)2014; 42(suppl. 2):s127-s134.
ここから診断能Diagnostic performanceの指標について、解説します。
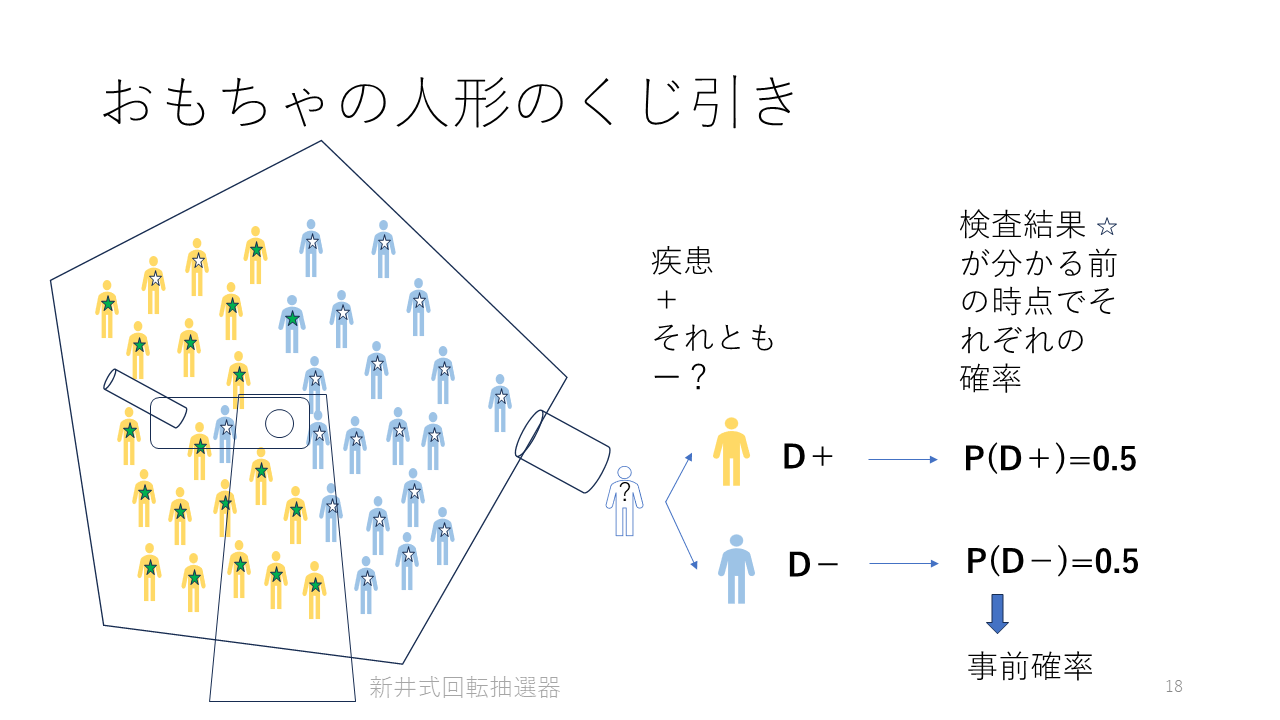
回転抽選器の中に、40個の人形が入っています。その50%は疾患がある色が付いていて、残り50%はそれがありません。この色は、外からは見えないようになっています。
回転させて、人形が1個出てきます。出てきた時点では、色が見えない場合、その人形が疾患がある確率、すなわち疾患確率は0.5、つまり、P(D+) = 0.5ですということはできますが、それ以上は分かりません。
その疾患を診断するための検査がある場合、この検査結果を知る前の時点では、その人形が疾患があるのかないのかそれ以上は知ることができません。
検査前の疾患確率を事前確率あるいは検査前確率と言います。
さて、この検査の結果が得られたら、疾患確率はどう変化するでしょうか?
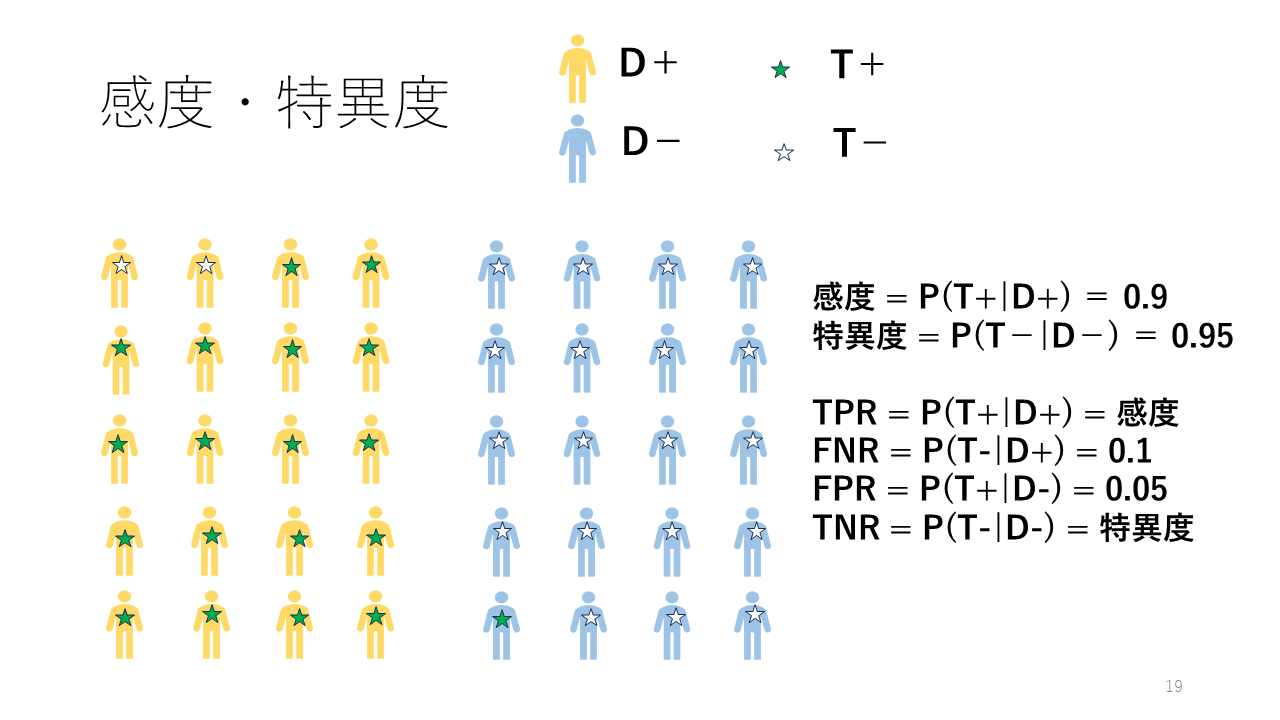
その検査を疾患のある人と無い人で調べて、疾患がある場合は90%の人で陽性の結果が得られることが分かったとします。それを条件付き確率の書き方で表すと、P(T+|D+) = 0.9となります。つまり、縦棒(パイプ)の右側の条件が満たされる場合に、左側の事象が起きる確率ですが、疾患がある場合に検査が陽性になる確率です。これを感度Sensitivityと呼びます。1 - 感度は偽陰性率になります。
疾患の無い場合は0.05%の人で陽性の結果が得られることが分かったとします。これは偽陽性率に相当しますが、条件付き確率の書き方で表すと、P(T+|D-) = 0.05となります。診断法に関する議論では、1 - 偽陽性率のことを特異度と呼びます。偽陽性率と特異度を合計すると1.0になります。
感度・特異度はデータが得られた対象者の疾患スペクトルによって変動しますが、その診断法の固有の属性で、診断法の診断能Diagnostic performaneはこれら感度・特異度から知ることができます。感度・特異度が100%の診断法があれば、その結果で100%の精度Accuracyで診断が付けられますが、そのような理想的な診断検査法は存在しません。
略語の説明をします:TPR True Positive Rate 真陽性率; FNR False Negative Rate 偽陰性率; FPR False Positive Rate 偽陽性率; TNR True Negative Rate 真陰性率です。
また、研究対象者の真陽性の人数をTrue positives (TP)、偽陰性の人数をFalse negatives (FN)、偽陽性の人数をFalse positives (FP)、真陰性の人数をTrue negatives (TN)と言います。例えば、診断精度研究のメタアナリシスでは各研究からTP, FN, FP, TNの値を抽出します。
さて、感度・特異度を診断でどのように用いるかを見ていきましょう。
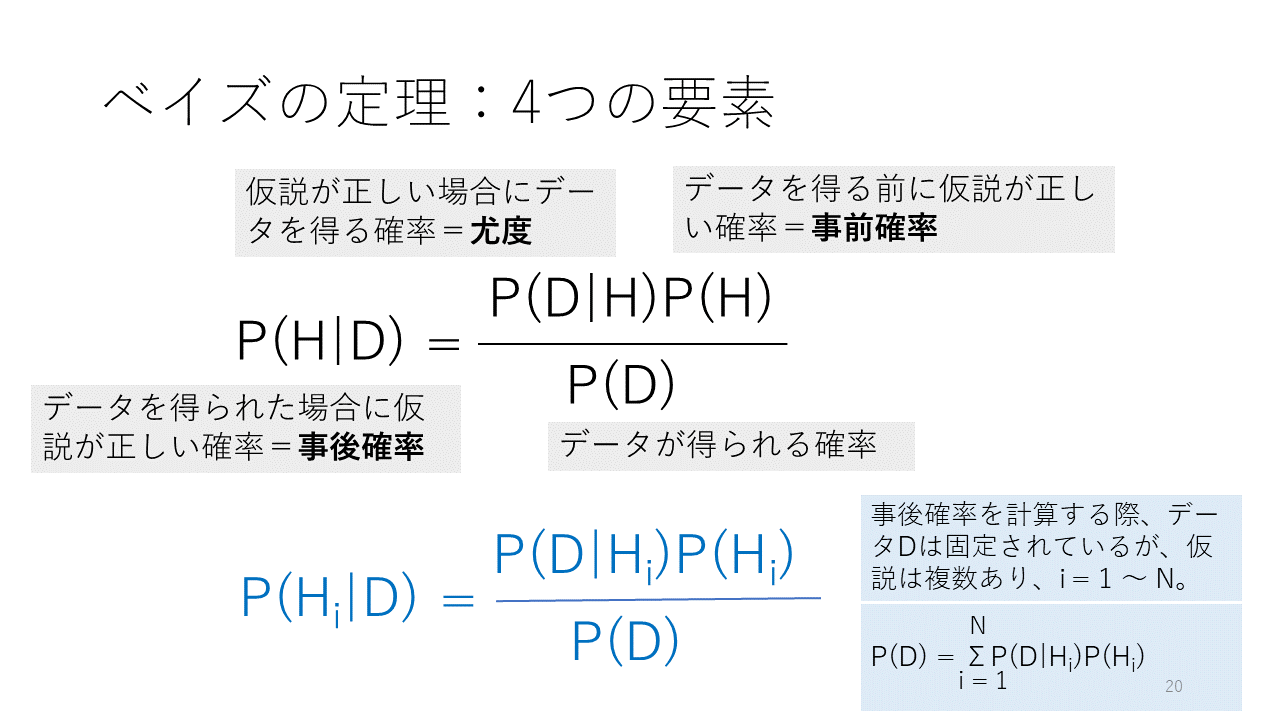
診断法をひとりひとりの対象者に適用し結果が得られると、疾患確率が変化します。その変化はベイズの定理/規則 Bayes’ theorem/rule に従います。ここには、最も一般的なベイズの定理の式を示します。
Hは仮説です。Dは前のスライドとは違ってデータのことです。この式の左辺はデータを得た際の仮説が正しい確率を表します。The probability that the hypothesis is correct given the data. すなわち、データDで条件づけられた仮説Hの正しい確率です。つまり、条件付き確率です。データがわかった後の仮説が正しい確率なので事後確率と呼ばれます。
診断について当てはめると、診断検査の結果がデータDに相当し、想定する疾患に罹患しているという仮説がHに相当します。検査の場合は、事後確率のことを検査後確率と呼ぶこともあります。また、陽性的中率とも呼ばれます。検査が陽性の場合の疾患確率という意味です。
右辺のP(D|H)は仮説が正しい場合にデータを得る確率を表します。診断においては、疾患に罹患しているという仮説を設定したのであれば、感度に相当します。つまり、その疾患に罹患している場合に検査が陽性になる確率です。このP(D|H)は条件付き確率ですが、データの方が固定された値で、仮説Hの方が疾患がある、あるいはないと変動する値なので、そのデータにおいて仮説がどれくらい尤もらしいかと考えることによって、尤度と呼ばれます。
Hが正規分布の平均値、分散といったパラメータの場合は、それらの値を変動させてデータDを得る確率を計算します。頻度論派の伝統的統計学では、仮説は帰無仮説に限定して、それが正しい場合のデータを得る確率を計算しますが、ベイズ統計学はそれとは考え方が異なります。
右辺のP(H)はデータを得る前の仮説が正しい確率で、事前確率を呼ばれます。診断において、検査を実施する前の時点での疾患確率に相当します。有病割合(率)であったり、問診などのデータを得たうえで、Physician’s index of suspicionとして医師が主観的に設定する場合もあります。
P(D)はそのようなデータを得る確率を意味します。診断においては、想定する疾患である場合とない場合それぞれの事前確率と尤度の積の合計になります。鑑別診断のように、複数の疾患を想定する場合は、同様にそれぞれの疾患の事前確率と尤度の積の合計になります。
実臨床では、仮説Hが疾患ある・無しの二つだけでなく、3つ以上の疾患を想定することが普通ですが、その場合、感度・特異度の枠組みで考えるのは難しくなり、スライドの下の方に示す式で考える必要があります。この場合、P(D) はスライド右下の式で計算されます。
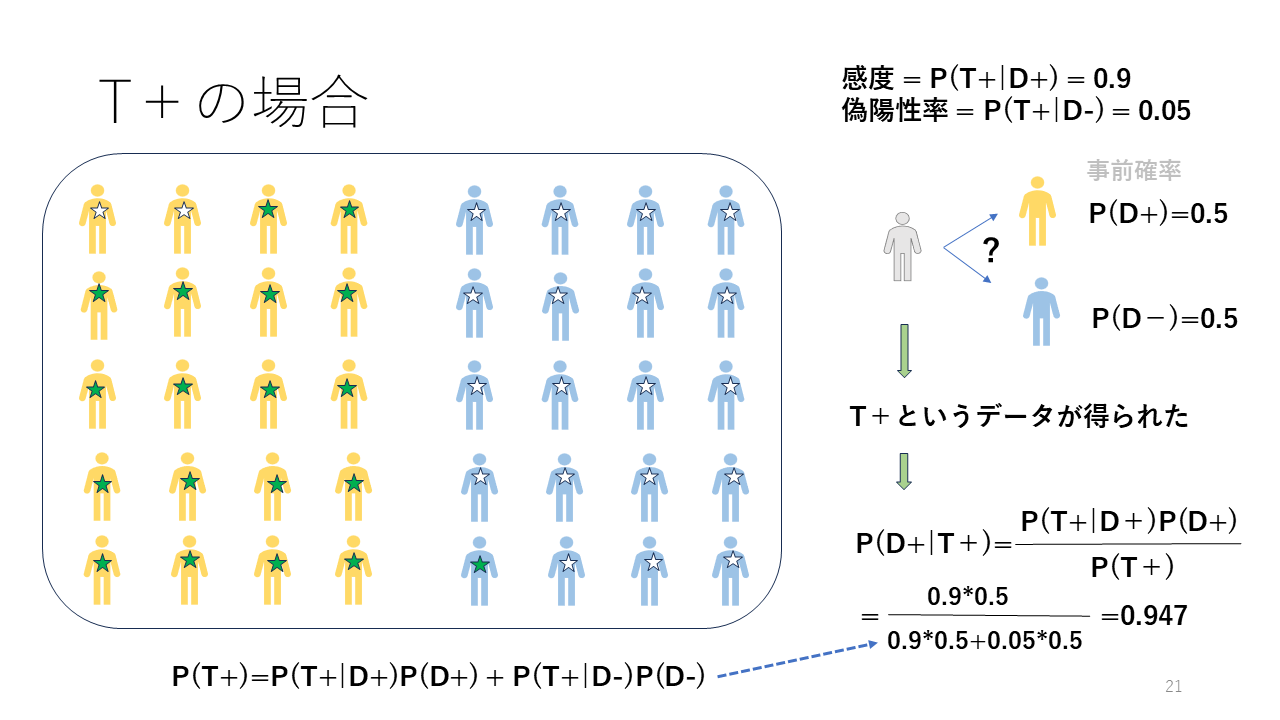
ある疾患に罹患していることをD+、罹患していないことをD-、検査結果が陽性をT+、陰性をT-で表し、ベイズの定理を適用してみましょう。
対象集団からランダムに一人を選択した場合、その人がその疾患に罹患している確率はP(D+)で表すことができます。対象集団が40人で、その半分の20人が疾患に罹患していて、残り半分の20人が疾患に罹患していないとします。そうすると、P(D+)=0.5、P(D-)=0.5となります。
ある検査の結果がその疾患に罹患していると0.9の確率で陽性、つまり感度が90%で、その疾患に罹患していないと0.05の確率で陽性、つまり偽陽性率が0.05、言い換えると特異度=1 - 偽陽性率は0.95だとします。
感度はP(T+|D+)に相当します。偽陽性率はP(T+|D-)に相当します。 特異度はP(T-|D-) = 1 - P(T+|D-)となります。また、偽陰性率はP(T-|D+)で表されます。
P(T+|D+) + P(T-|D+) =1ですし、P(T+|D-) + P(T-|D-) =1です。これらの条件付き確率の合計は1になります。
一方、P(T+|D+) + P(T-|D-) ≒ 1で、尤度の合計は1にはなりません。図の緑の星印は検査結果が陽性であることを表していますが、その疾患のある場合とない場合のそれぞれの条件付き確率の合計は1にならないことは明らかです。
対象集団からランダムに選択した一人が、検査結果が陽性ということがわかりました。その人が疾患に罹患している確率はいくつでしょうか?
その計算にはベイズの定理を適用します。図の右下に示すように、検査結果が陽性の時の疾患確率はP(T+|D+)P(D+)/P(T+)で計算されます。分母のP(T+)は疾患がある場合の検査陽性の確率と疾患がない場合の検査陽性の確率の和になります。
検査結果が陽性の場合の疾患確率は、図を見て、緑の星印全体の中の疾患がある人の割合と同じ値です。
感度・特異度の値を用いる場合は、感度*事前確率/[感度*事前確率 + (1 - 特異度)*(1 - 事前確率)]で計算されます。
感度と偽陽性率の値を用いる場合は、感度*事前確率/[感度*事前確率 + 偽陽性率*(1 - 事前確率)]で計算されます。
診断精度(DTA)研究は普通は横断研究に分類されます。検査を実施する際に疾患、病態など診断標的がすでに存在するので、検査とアウトカムが同じ時点で評価されるからです。
横断研究である診断精度(DTA)研究で、感度・特異度はどのようなデータから計算されるのでしょうか?
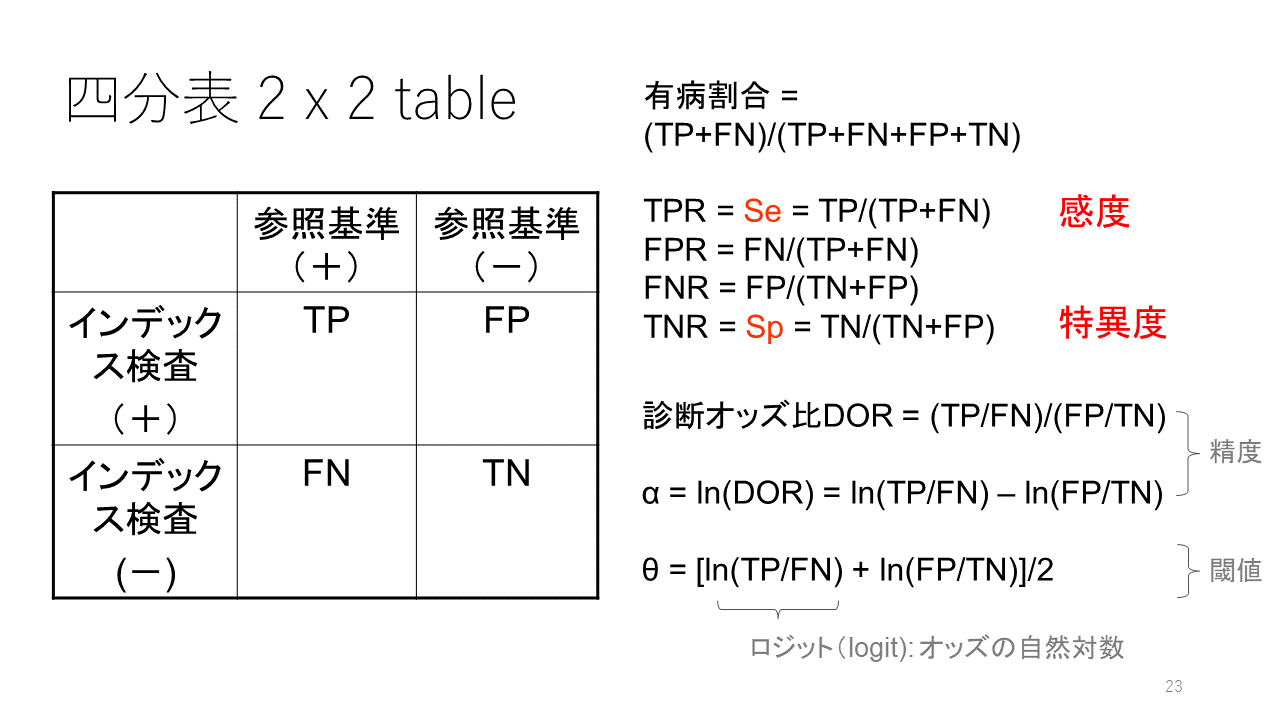
ここに示すような四分表 two-by-two tableのデータから感度・特異度が計算されます。
TPはTrue positives 真陽性の人数、FNはFalse negatives 偽陰性の人数、FPはFalse positives 偽陽性の人数、TNはTrue negatives 真陰性の人数を表します。
疾患の有無は何らかの参照基準を用いて判定されます。感度・特異度が100%の診断法がある場合は、それを至適基準Gold standardとして用いることができますが、至適基準がない場合は、参照基準にはある程度の偽陰性、偽陽性があることを前提として感度・特異度を計算します。
感度sensitivityはTP/(TP+FN)、特異度specificityはTN/(TN+FP)で計算されます。
正診率は(TP + TN)/(TP + FN + FP + TN)、陽性尤度は[TP/(TP + FN)]/[FP/(FP + TN)]、陰性尤度比は[FN/TP + FN)]/[TN/(FP + TN)]です。
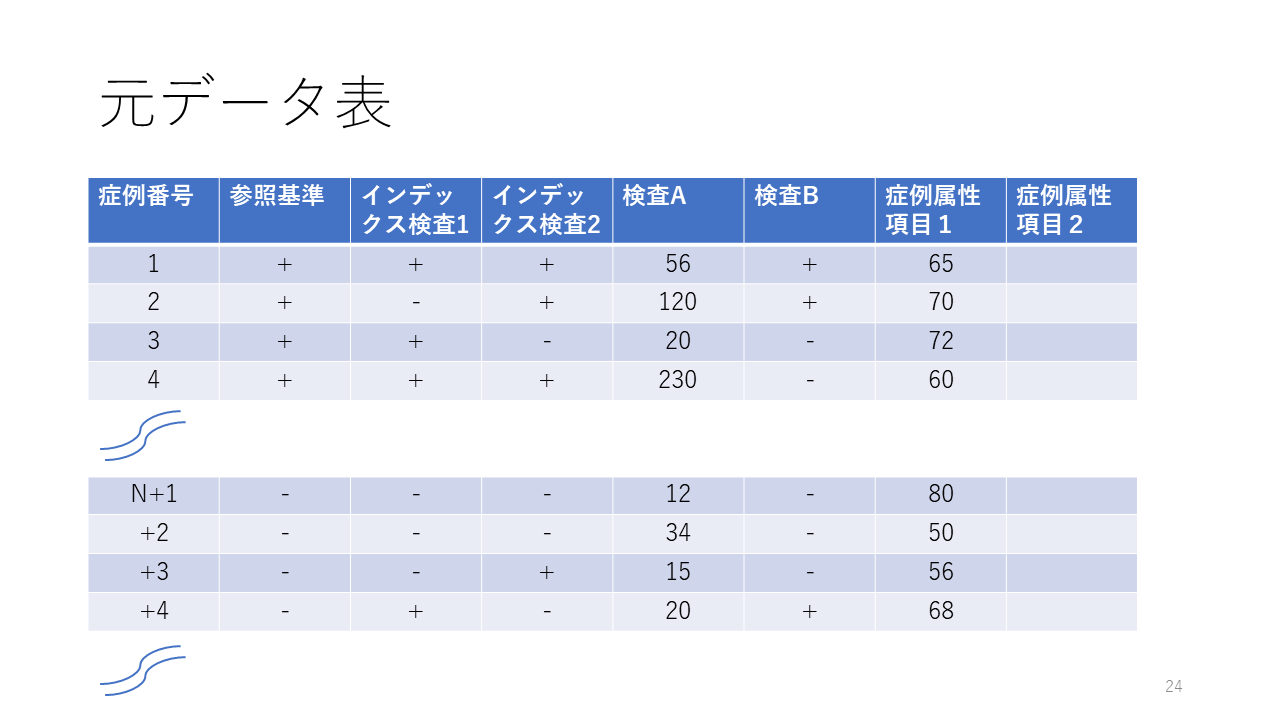
四分表は各症例について記録された多数の項目のデータの中から、2つだけ選択して集計したものです。いわゆるクロス集計表の一つですが、各症例で行われた他の検査の結果や並存疾患、病期などの属性に関するデータは無視されています。
ランダム化比較試験の場合は、治療の有無と主要アウトカムの2つの項目だけで四分表を作成し、治療と主要アウトカムの関係を分析しても、ランダム化が適切であれば、他の要因の影響を考える必要はありません。ランダム化によって他の要因については比較する群間でバランスがとれている可能性が高いからです。
診断精度研究の場合は、一つの検査をインデックス検査として分析の対象にしますが、実臨床の場では、一つの検査だけで、診断が確定するのではなく、症状、診察所見、臨床検査、生理機能検査などさまざまな検査を行って、疾患確率をほぼ1.0にすることが、普通です。2つ以上の検査が陽性、陰性の組み合わせで、結果が得られた際に想定する疾患の確率がどうなるかを計算するには、各検査の相関を考慮する必要があります。相関を知るためには、各症例でそれらの検査を同時に施行する必要があります。ある疾患で陽性に出る検査は、互いに相関がある程度あるのが普通ですから、それぞれの検査の感度と特異度だけでは正確な事後確率を計算できなくなります。
四分表を用いて分析を行う場合は、常に元データに含まれている、あるいは、含めるべき項目は何かを考えるべきだと思います。
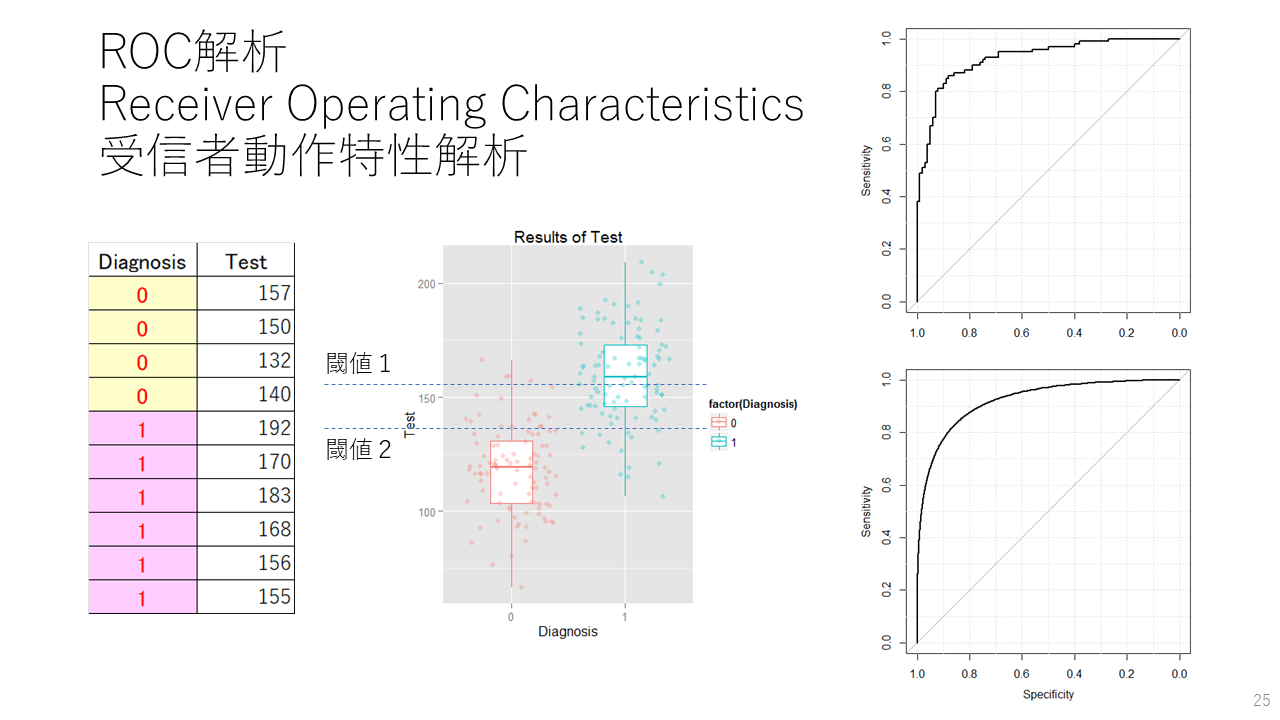
検査結果が連続変数で得られる診断法の診断能の解析には、受信者動作特性解析(Receiver Operating Characteristics analysis, ROC解析)が用いられます。
左側が解析データ、中央に値の分布を示す箱ひげ図、右側にROC解析の結果であるROC曲線を示します。中央の図で青い点は疾患+、ピンクの点が疾患-を表します。
中央の分布で閾値1よりも閾値2の方が、感度が高くなりますが、偽陽性率も高くなり、特異度が下がることが分かります。このように、診断閾値を変動させることによって、感度と特異度(偽陽性率)が変動します。その際に縦軸に感度の値を、横軸に特異度(偽陽性率)をとって、プロットするとROC曲線が得られます。
ROC解析は元データの分布に影響されないので、正規分布を前提にする必要はありません。また、TP, FN, FP, TNのデータから、複数の研究をまとめ、メタアナリシスによて、ROC曲線を描画することもできます。
ここに示すROC曲線はRのpROCパッケージを用いて、2つの正規分布からランダムサンプリングした100例/100例の架空のデータを解析した結果です。右上のROC曲線はDeLongの方法に基づき少しギザギザがあるROC曲線、右下のROC曲線は同じデータですがブートストラップ法で描いたスムーズなROC曲線です。
ROC曲線はグラフの左上の感度1,特異度1(偽陽性率0)の点まで伸びていると、完全な診断法であると言えます。その際の曲線下の面積Areia Under the Curve (AUC)は1.0になります。AUCはその診断法の診断能の指標になりますが、感度・特異度の2つのパラメータを無視して、診断能を議論することは必ずしも正しい結論に到達するとは限りません。
また、閾値の設定は事前確率によって、最適値が異なります。
ここには、RのpROCパッケージを用いたROC解析のためのスクリプトを示します。
Excelで作成した、データは診断標的があるかないかを1または0で変数Diagnosisに入れ、と変数Testには検査結果を数値で入力します。roc()関数で解析を実行し、結果を変数resに格納します。
最適の診断閾値を決めるには、事前確率と診断がついた後受ける治療の益と害の大きさを知る必要がありますが、事前確率は0.5とし、治療の益と害は考慮しないで感度・特異度が最大化する閾値はYoudenの方法で計算できます。
pROCパッケージではcoords()関数で得られます。ここには一例を示しますが、閾値、感度、陽性的中率、特異度、陰性的中率の値が出力されました。この例では、2組の値が得られ、わずかな差ですが、感度を優先する場合と特異度を優先する場合の値が得られました。
もし、診断がついた後受ける治療の益と害を効用値として設定可能な場合は、正味の益を最大化する診断閾値を事前確率とともに検討することができます。診断閾値(カットオフ値)は事前確率と治療の益と害の大きさによって決まってきます。
診断精度研究は多くの場合、一つの診断法について、何らかの参照基準を設定して、その感度・特異度を明らかにする目的で行われます。また、2つの診断法の感度・特異度をhead-to-headで直接比較し、どちらの診断能が優れているかを明らかにすることが目的の場合もあります。
2つ以上の診断法を適用した場合、それぞれの診断法が独立していれば同時確率としてその感度の積を全体の感度として用いることが可能ですが、独立していることはまれです。その場合どのように対処すべきでしょうか?
また、検査結果が陽性・陰性の二値変数ではなく、高・中・低の3つのカテゴリーであったり、それ以上のカテゴリーであったりした場合はどのように取り扱ったらいいでしょうか?
多項(名義)ロジスティック回帰分析Multinomial logistic regression analysisは応答変数が3つ以上の名義変数の場合に用いることができる方法です。
応答変数が二つのカテゴリーしかない場合にはロジスティック回帰分析を用います。例えば、陽性・陰性のような2つの内のどれかの事象が起きるようなデータに適用しますが、それを3つ以上のカテゴリーがある応答変数に拡張した方法です。応答変数の数がK個であれば、K - 1個の切片と係数の組み合わせが得られます。応答変数は互いに排他的で独立しており、すべてのアウトカムを含んでいることが前提です。
それぞれの応答変数のカテゴリーに対する確率を計算することができます。
説明変数は連続変数、順序変数、名義変数のいずれも取り扱えます。説明変数は互いに強い相関があると多重共線性のため解析ができなくなります。
また、ひとつのカテゴリーをそれ以外のカテゴリーと対比してロジット(オッズの対数)をモデル化する方法もあります。すなわち、応答変数のひとつのカテゴリーの値を1として、それ以外のカテゴリーはすべて0にして、K個の組み合わせで解析する方法です。
なお、応答変数に大きさに順序がある場合、すなわち、順序変数の場合は、順序ロジスティック回帰分析 Ordinal (ordered) logistic regression analysisを用います。その場合は、応答変数のその値の順序以下の値の確率とそれよりも順序が上の値の確率のロジットをモデル化します。
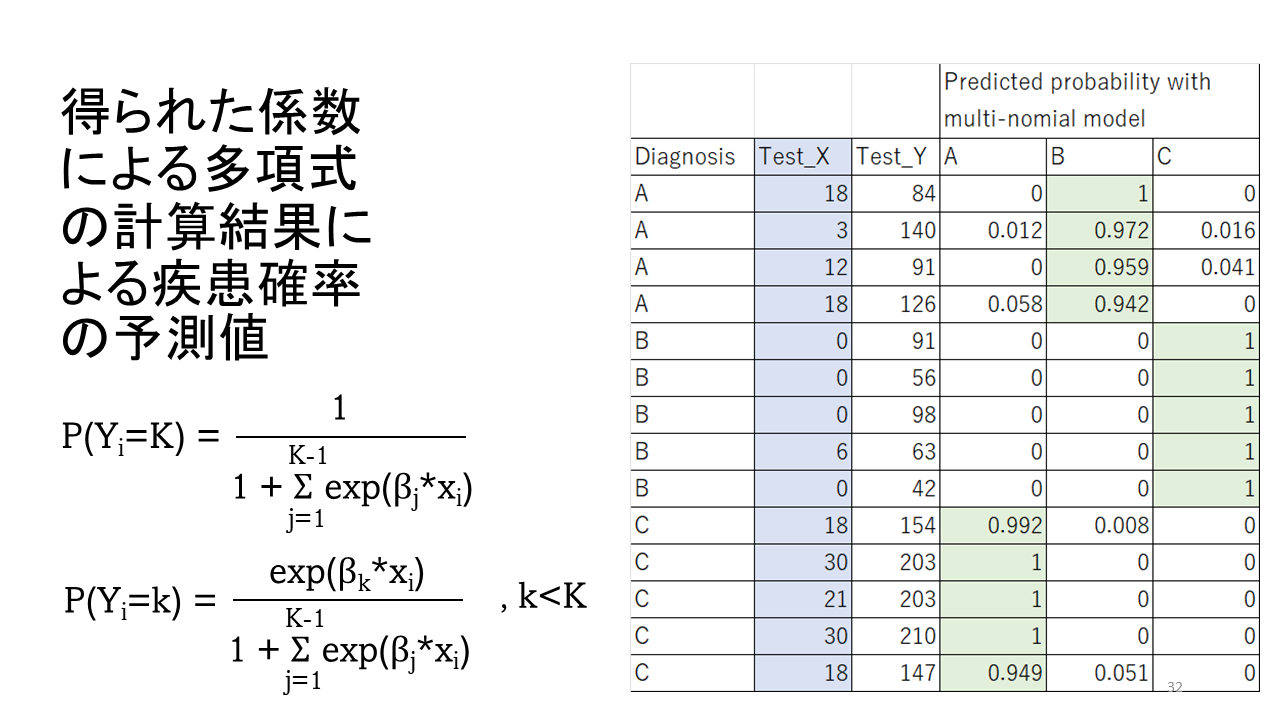
検査結果がA,B,Cの3つのカテゴリーあり、検査法がXとYの2種類ある場合の例です。左側にExcelで用意した、一部の症例の解析データを示します。
右側は、Rで実行するスクリプトです。Rのnnetというパッケージを用い、Excelのデータをクリップボード経由で変数train.datに読み込ませ、変数Diagnosisを応答変数に、変数Test_XとTest_Yを説明変数に設定し、nnetのmultinom()関数で解析します。
変数Diagnosisは名義変数であることをas.factor()関数で指示し、Diagnosis変数の値Cを参照カテゴリーであることをrelevel()関数で指示しています。
multinom()関数の実行結果は変数multinom_modelに格納し、その結果をsummary()関数で表示し、係数のExponentialを計算させ、オッズ比の値を出力させます。
同じデータに対して、fitted()関数で処理させ、Diagnosisの各カテゴリーに入る確率を計算させ、その結果を変数DiagPredictedに格納させ、出力します。
右側の表に疾患確率の予測値を示します。それぞれのカテゴリ-の確率は、ほぼ1.0となり、精度も100%の結果が得られました。
つまり、検査XとYの2つを組み合わせると、ほぼ100%の正診率で診断が可能であることを示しています。
なお、検査X単独では、正診率は80%、検査Y単独では、93%でした。
個々の症例での疾患確率は、検査Xと検査Yの結果から診断Aに対するオッズ比 OR(A)、診断Bに対するオッズ比 OR(B)を計算し、以下の式で計算されます。
P(A) = 1/[1 + OR(A) + OR(B)]
より一般化した式はスライド左下に示します。
2つ以上の検査、3つ以上の検査結果のカテゴリー、診断標的が3つ以上の場合、ここまで述べた多項ロジスティック回帰分析を適用するのがひとつの方法ですが、もう一つの方法が感度・特異度を共分散で調整する方法です。
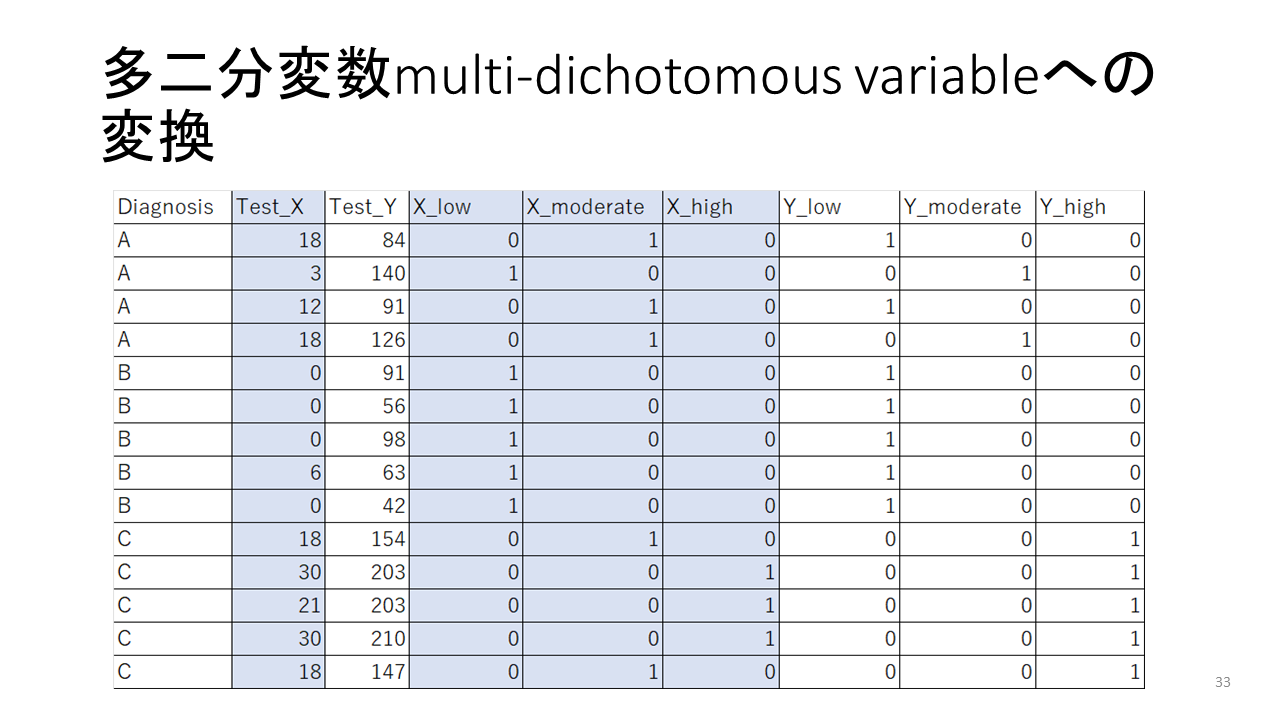
スライドの表は、数値変数で得られる二つの検査XとYの結果をlow, moderate, highの3つのカテゴリーの多二分変数 Multi-dichotomous variable に変換したデータを示します。low, moderate, highの値は互いに排他的です。検査結果が、陽性、陰性の二値ではなく、low, moderate, highの3つの値のいずれかになるということになります。
3つのカテゴリーに分類する際の閾値の決め方ですが、この例では、ROC解析を行って、Youden’s Indexを計算しそれを用いる方法を採用しました。診断が3つのカテゴリーあるので、A対B+C、C対A+Bで2つのROC解析を実行し、Youden’s Indexを計算し、それを閾値に設定し、low, moderate, highの3つのカテゴリーに分けることができます。
また、もともと結果が3つあるいはそれ以上のカテゴリーに分かれる検査もあります。
今回は、詳細を解説することはできませんが、共分散を考慮しないと、正確な疾患確率の計算はできないということを例を挙げて、解説したいと思います。
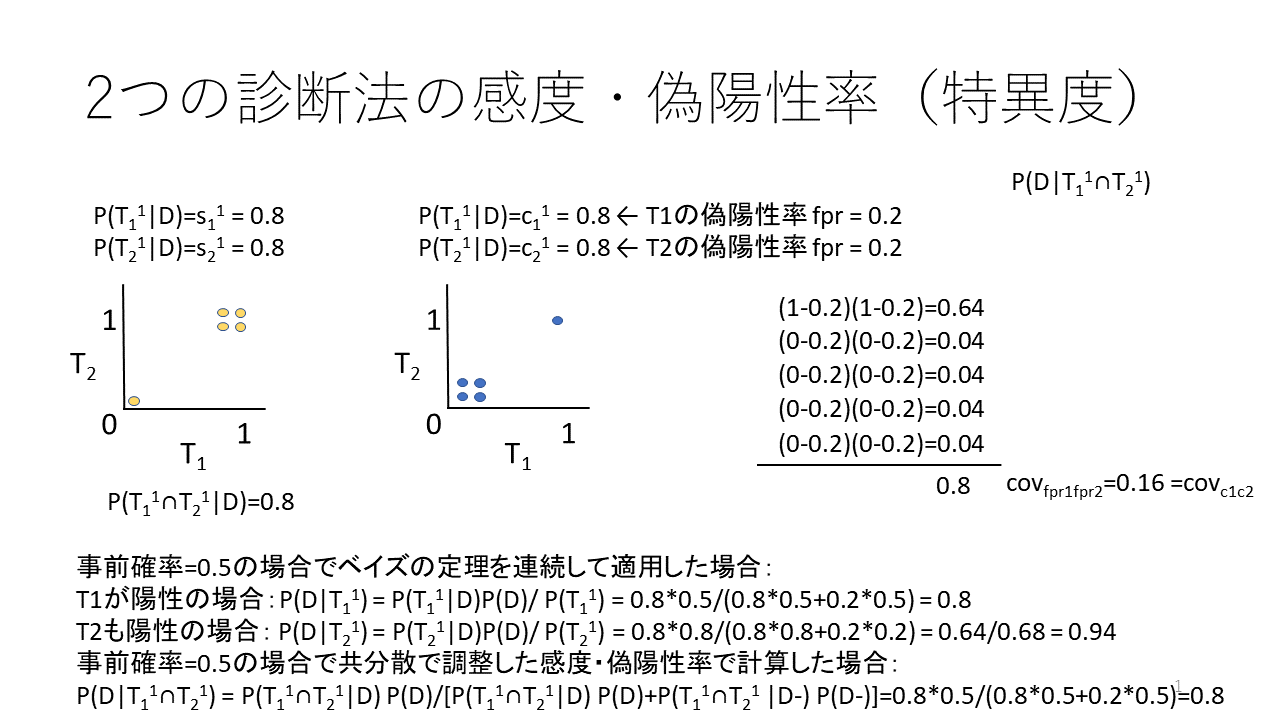
共分散は、2種類の検査、T1とT2があり、その結果が陽性の場合は1,陰性の場合は0とした場合、2つの検査の結果の相関の程度を表す指標です。共分散の値をそれぞれの標準偏差で割り算すると相関係数になるので、共分散も相関の程度を表す指標と考えてください。各症例のT1の結果の値からT1の結果の平均値を引き算した値とT2の結果の値からT2の結果の平均値を引き算した値の積の症例数分の平均値が共分散になります。
このスライドでは、分かりやすくするために、症例数が5つの場合を示しています。T1の感度が0.6、T2の感度も0.6で共分散が-0.16の例を示します。
グラフを見るとわかるように、T1もT2も陽性の例は、5例中1例なので、青字で示す、2つの検査が陽性の確率は0.2です。しかし、T1の感度が0.6で、T2の感度が0.6なので、両者が同時陽性になる確率、すなわち同時確率を確率の掛け算の法則で、0.6×0.6=0.36と求めると違う値になってしまいます。そこで、T1とT2の共分散を中央に示す式で計算すると、つまり、各症例の1または0の値から平均値である感度0.6の値を引き算して、それらの積を合計すると-0.8になり、それを症例数5で割り算すると、共分散-0.16が得られます。この共分散の値を同時確率に加算すると、0.36-0.16=0.2で正しい感度の値が得られます。
すなわち、2つ以上の検査を用いる場合は、共分散で調整しないと、正しい感度の値は得られないということが分かります。
そして、複数の診断法の共分散、(あるいは相関)を明らかにするには、個々の症例でそれら複数の診断法を同時に実施する必要があるにもかかわらず、そのような研究データはあまりないのが現状です。
また、診断法の結果が陰性・陽性の2つのカテゴリーではなく、3つ以上のカテゴリーがある場合、疾患がある・ないの二つの状況ではなく、複数の疾患を鑑別しようとする場合、感度・特異度の枠組みには限界があるといえます。
関連スライド:
診断法を比較する際に、感度・特異度の両方がより高い診断法がより望ましい診断法と考えることは多くの場合、適切ですが、もし診断法に伴う害が大きい場合は、必ずしも適切とは言えないかもしれません。また、感度と特異度にトレードオフがあり、片方の診断法が感度では優れているが、特異度では劣っている場合や、その逆の場合があります。そのような場合、感度・特異度だけで優劣を決めることは困難です。
診断検査法の臨床的価値を直接証明するために、患者中心アウトカムに対する診断検査法の実施効果を明らかにする、ランダム化比較試験を行うことはほとんどの場合、困難です。そこで、間接的な証明にはなりますが、診断検査法を実施し、診断が確定した後受ける治療法の益と害も含めて、分析する方法が提案されています。疾患確率と治療する場合、しない場合の効用値の関係、そして、疾患確率と診断検査法の実施の効用値の関係を分析する方法です。
同じ診断検査法であっても、実施する対象の事前確率によって、その有用性は異なってきます。
例えば、ほぼ健康な人を対象にするスクリーニング、疾患のリスクがある程度高い人を対象にするサーベイランス、症状があり、ある疾患が想定される人を対象にする診断は、事前確率が後の方ほど、高くなります。スクリーニングでは特異度が十分高くないと、偽陽性者が多くなり、その対処が問題になります。
3種類の事前確率を設定して、TP, FN, FP, TNの人数に基づいて診断法の臨床的有用性について議論し、実施すべきかどうかを決める方法も提案されています。
より定量的なアプローチで、想定される治療の益と害を効用値として設定して、治療閾値や診断閾値を分析することができます。
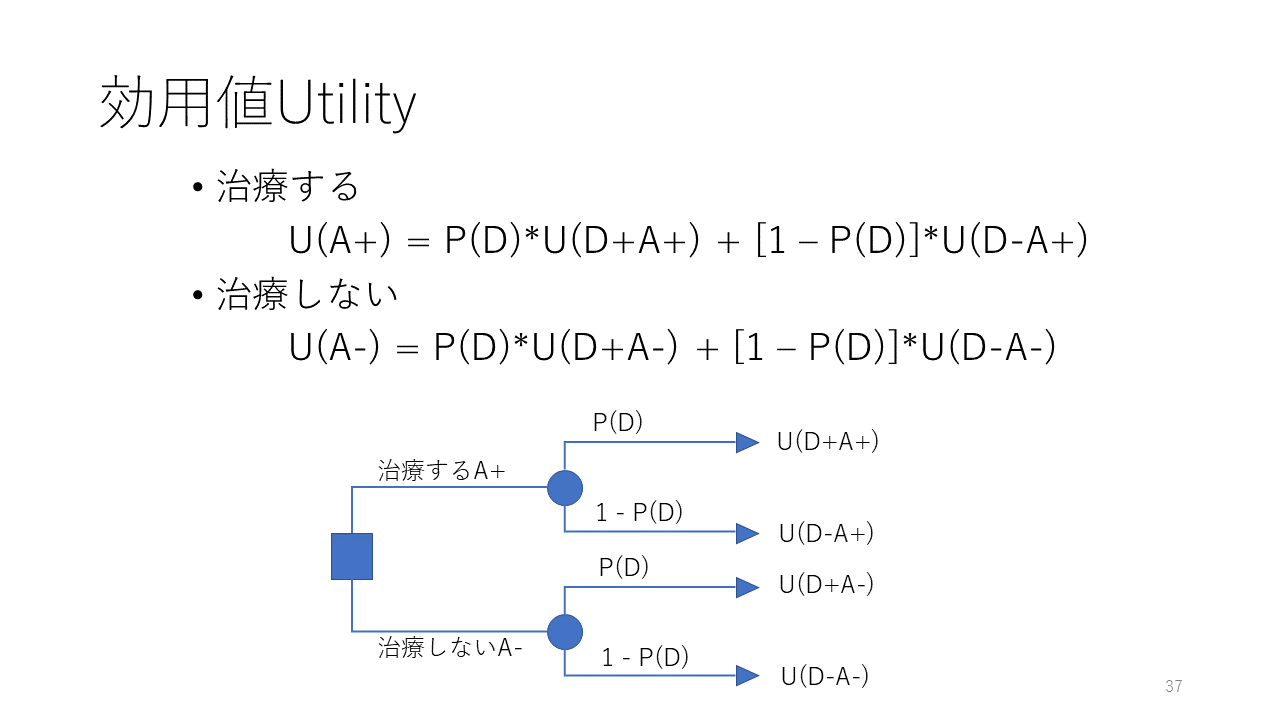
まず、治療閾値を理解するために、疾患確率と治療する場合と治療しない場合の効用値の関係を分析します。そのための、決定木Decision treeをこの図に示します。
決定木の枝の終末は4つに分かれ、U(D+A+)は疾患があり治療を受ける効用値、U(D-A+)は疾患が無いのに治療を受ける効用値、U(D+A-)は疾患があるのに治療を受けない効用値、U(D-A-)は疾患が無く治療も受けない効用値です。
治療することをA+、つまりAction+で示し、治療しないことをA-出示します。疾患である場合をD+、疾患でない場合をD-で示します。疾患確率はP(D)で示します。
治療する効用値U(A+)は上に示す式で、治療しない効用値U(A-)はその下の式で示します。
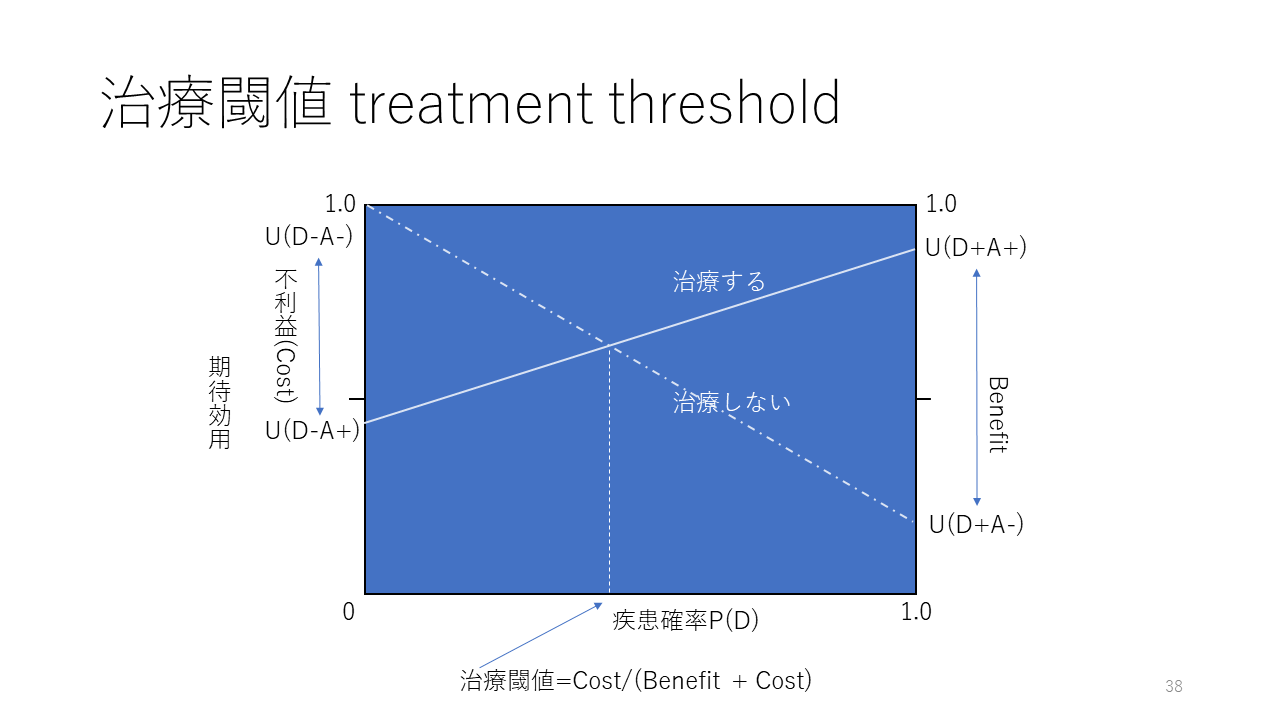
前の決定木に従って、治療する場合と治療しない場合の疾患確率と効用値の関係をグラフで表すと、このようになります。
U(D-A-)は疾患が無く治療も受けない効用値で、一番望ましい状態であり、その効用値は最大値である1.0になります。もし疾患確率P(D) = 1.0で治療を受けない場合の効用値U(D+A-)は疾患によって異なりますが、ほぼ100%死亡するような疾患であれば0になります。それら2点間を結ぶ直線が治療をしない場合の疾患確率と効用値の関係を表します。疾患確率と効用値は直線関係にあります。
一方、U(D-A+)は疾患が無く治療を受ける効用値で、疾患確率が0の場合に治療を受けるコストが発生し、副作用などの害が発生することもあります。ここでは、害、負担、費用をまとめて不利益と呼ぶことにします。その不利益の分だけ、効用値をU(D-A-)から減じた点にU(D-A+)が置かれます。そして、疾患確率が1.0の場合、U(D+A+)は治療によるベネフィットの分だけより高い値になりますが、疾患による不利益、治療というコストが発生するので、効用値は1.0よりは小さな値になります。U(D-A+)とU(D+A+)を結んだ直線が疾患確率と治療を受ける際の関係を表します。この場合も、疾患確率と効用値は直線関係にあります。
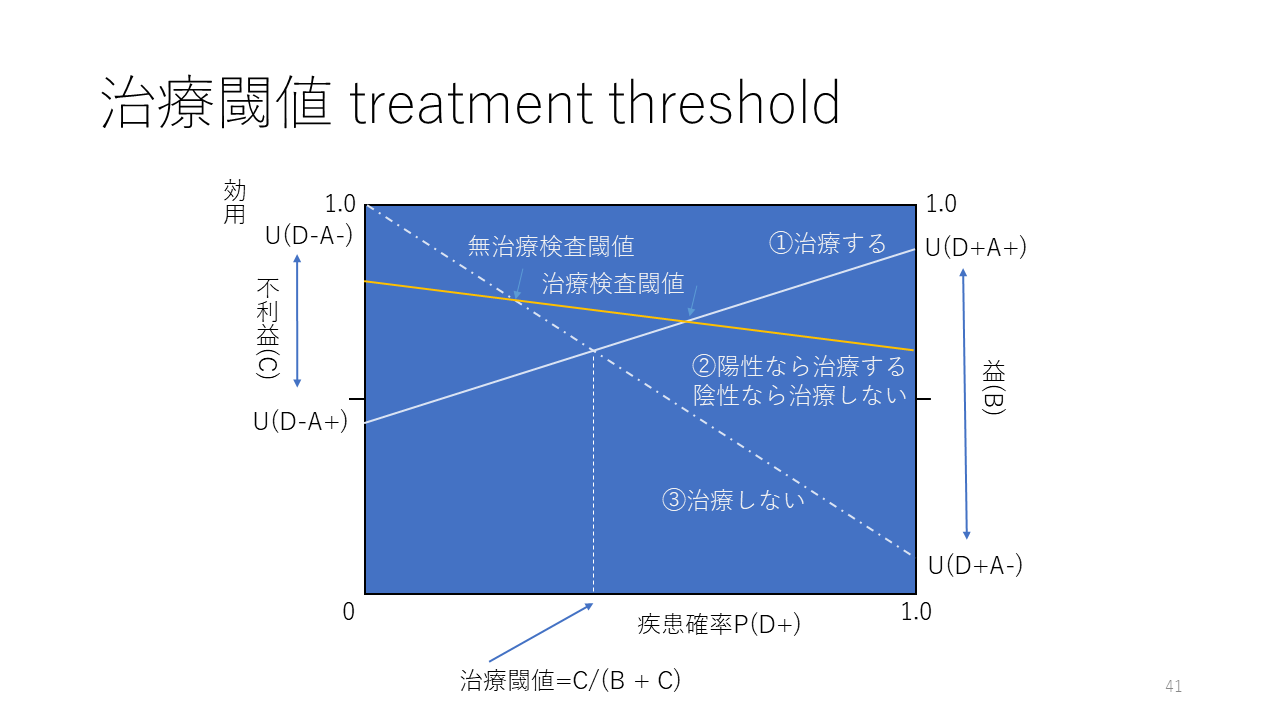
これら2つの直線、すなわち治療する場合の疾患確率と効用値の関係を表す直線と、治療をしない場合の疾患確率と効用値の関係を表す直線は交差します。そして、交差する点の疾患確率を超えると、治療する効用値が治療しない効用値を上回るので、治療すべきと言え、この交点の疾患確率を治療閾値と呼びます。
U(D-A-) - U(D-A+)はコストの大きさに相当し、U(D+A+) - U(D+A-)がベネフィット(益)の大きさに相当します。そして、治療閾値はコスト/(ベネフィット+コスト)になります。
コストが大きいほど治療閾値は高くなり、ベネフィットが小さいほど治療閾値は高くなります。逆に、コストが小さいほど、治療閾値は低くなり、ベネフィットが大きいほど、治療閾値は低くなります。
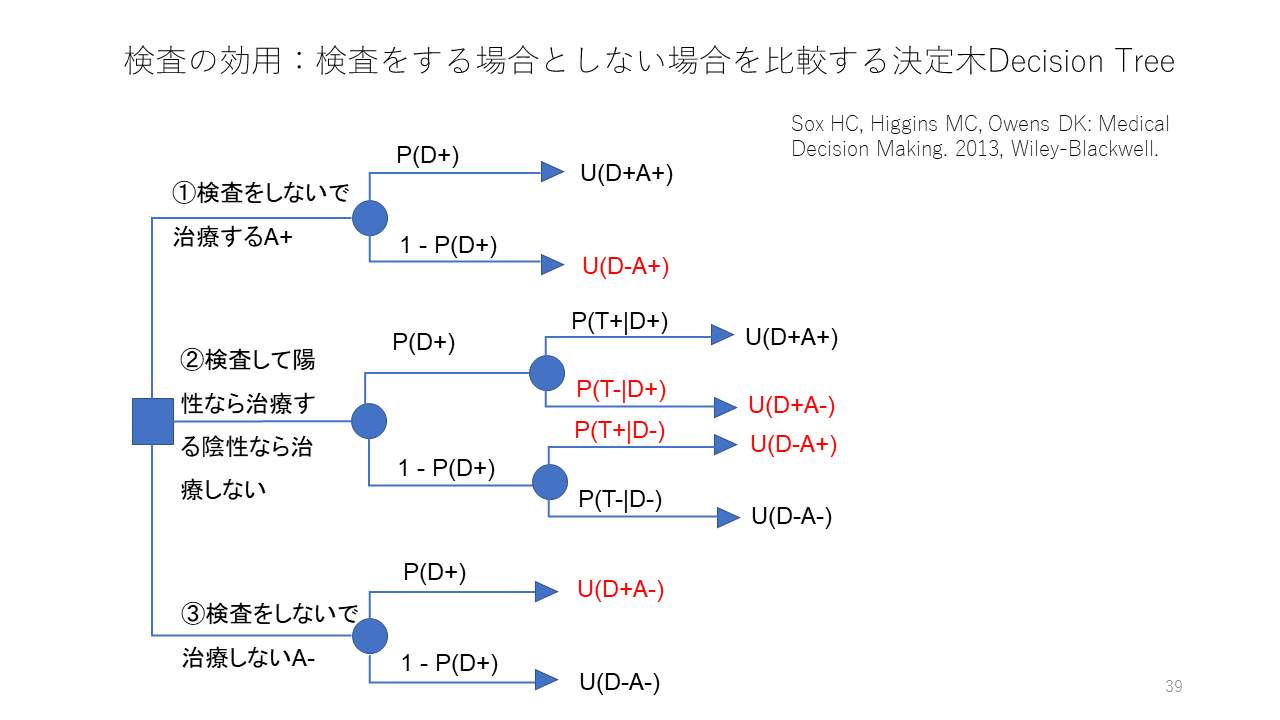
さて、今度は、検査をする場合の疾患確率と効用値の関係を考えてみましょう。ここに示す、②検査して陽性なら治療する陰性なら治療しないという選択肢の、効用値は疾患確率と感度、特異度、そして先ほどの4つの効用値、U(D+A+)=疾患があり治療を受ける効用値、U(D+A-)=疾患があるのに治療を受けない効用値、U(D-A+)=疾患が無いのに治療を受ける効用値、U(D-A-)=疾患が無く治療も受けない効用値から決まることが分かります。
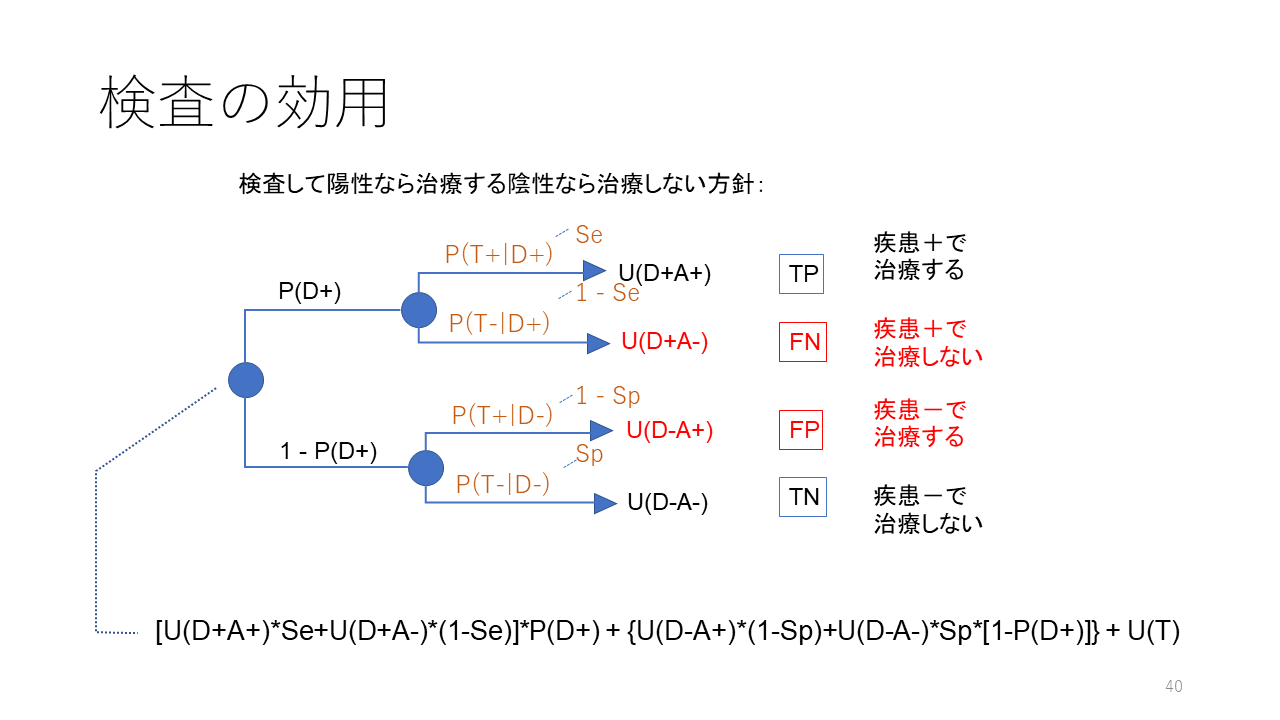
②の部分だけを示します。P(T+|D+)は感度Se、P(T-|D+)は偽陰性率FNR、P(T+|D-)は偽陽性率FPR、P(T-|D-)は特異度Spに相当します。
検査して陽性なら治療する陰性なら治療しない方針の効用値は、[U(D+A+)*Se+U(D+A-)*(1-Se)]*P(D+) + {U(D-A+)*(1-Sp)+U(D-A-)*Sp*[1-P(D+)]} + U(T)となります。U(T)は検査自体に伴う効用値で多くの場合は、マイナスの値ですが、検査を受けるだけで、不安が解消するというようなプラスになる場合もあります。
この式からわかるように、検査して陽性なら治療する陰性なら治療しない方針の効用値は疾患確率P(D+)の関数になっており、先ほどの治療閾値のグラフに重ねて描画することができます。
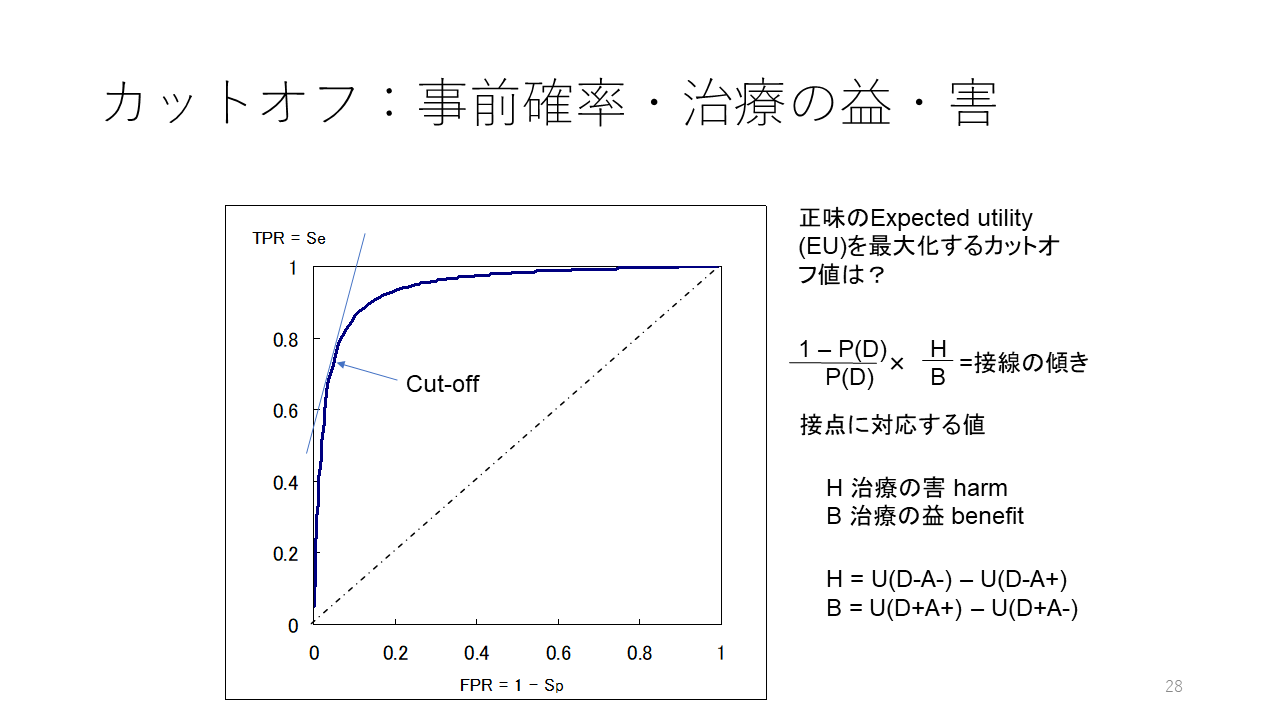
この図が、治療閾値を示すグラフに、検査して陽性なら治療する陰性なら治療しない方針の効用値と疾患確率の関係を示す直線(オレンジ色)を重ねて描画したものです。
これら3つの直線の関係から、検査して陽性なら治療する陰性なら治療しない方針の効用値が治療をしない場合の効用値を超える疾患確率と治療をする場合の効用値を超える疾患確率があることが分かります。前者が無治療検査閾値で後者が治療検査閾値です。この2点の間の疾患確率は、検査して陽性なら治療する陰性なら治療しない方針の効用値が他の2つの方針を上回るので、その検査をすべきと言えます。
また、無治療検査閾値は検査をしない場合の治療閾値より低値なので、もし、検査をしない場合と比べ、より疾患確率が低い時点で、治療を開始できるということになります。また、事前確率が、無治療検査閾値より低い時点では、検査をしても意味がないと考えることができます。事前確率が、治療検査閾値を超えていれば、検査をしても意味がないし、治療閾値は超えているので、検査はしないで治療を開始すべきということになります。
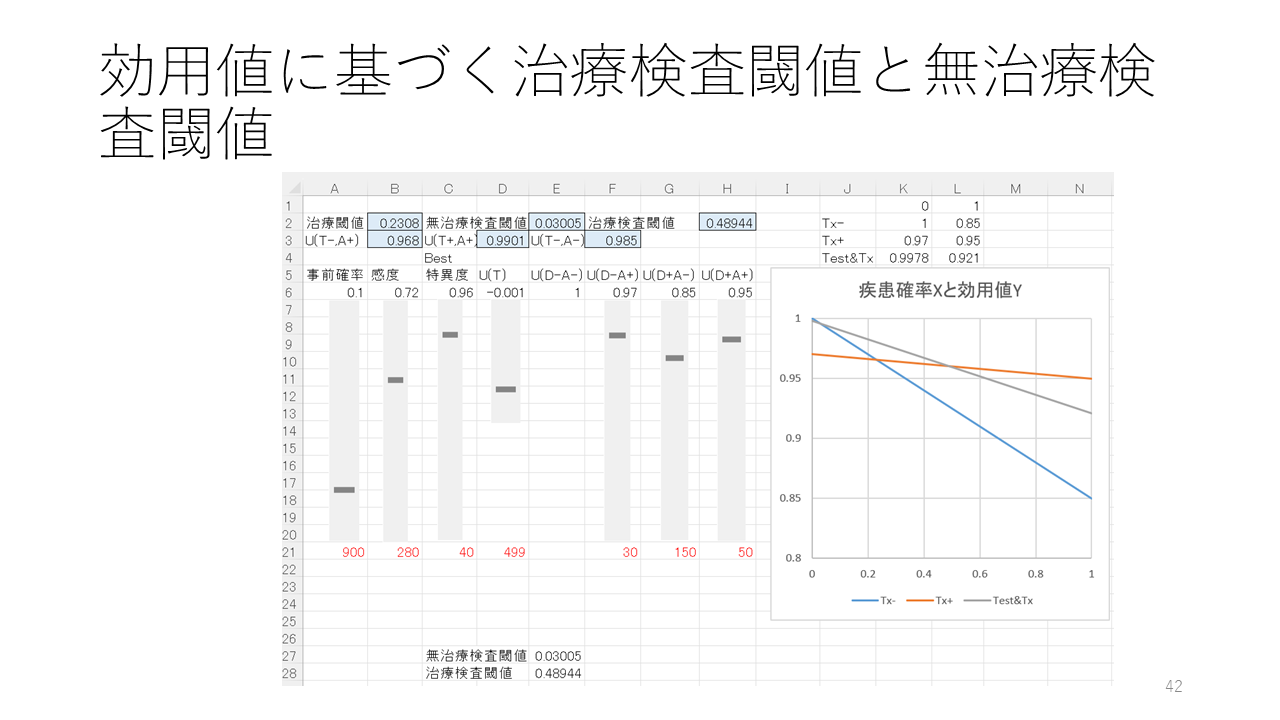
無治療検査閾値と治療検査閾値は以下の式で計算されます:
無治療検査閾値=[(1ーSp)・C] - U(T)]/[(1ーSp)・C+Se・B] = [FPR・C - U(T)]/(FPR・C+TPR・B)
治療検査閾値=[Sp・C + U(T)]/[Sp・C+(1ーSe)・B] = [TNR・C+U(T)]/(TNR・C+FNR・B)
以上述べてきたように、理論的には、事前確率、感度、特異度、疾患が無い時の治療を受けない効用値U(D-A-)、疾患が無い時の治療を受ける効用値U(D-A+)、疾患がある時に治療を受けない効用値U(D+A-)、疾患がある時に治療を受ける効用値U(D+A+)、そして検査自体の伴う効用値、これら8つの値によって、検査の有用性が決まり、検査をすべきかどうかの意思決定が可能になります。
感度・特異度は診断精度研究およびそれらのシステマティックレビュー/メタアナリシスによって値を得られます。効用値については、個人の価値観によって変動し、価値観によって決まる益と害のアウトカムの重要性と、そして治療の絶対効果の大きさによって決まります。今後、これらすべての要素を統合して意思決定を支援する方法論とシステムの確立が望まれます。
このスライドで示すExcelファイルはこちらです:https://info.zanet.biz/lec/stat/stat_diagnosis/tests_utility.xlsx
ダウンロードしてExcelで開いて使ってください。
最後にまとめです。
Quizはこちらです Link
学習終了後にこの学習ユニットの評価をお願いします。1分ほどで終了します。
close
疾患(ー)群については、真陰性あるいは偽陽性を1、そうでない場合を0にして、同様に取り扱えます。
診断結果のカテゴリーが3つの場合であれば、ひとつのカテゴリーの値を1にして、その他を0にして同様に取り扱えます。
close
J個の診断法の感度=陽性率の共分散の計算式です。
close
3つの診断法の感度を共分散で調整する式です。
規則性があるので、4つ以上の場合もこの式を拡張して対処できます。
close
調整後の感度が0~1の範囲になるようにするため、共分散の値に対しTえここに示すような制限が必要な場合もあります。
close
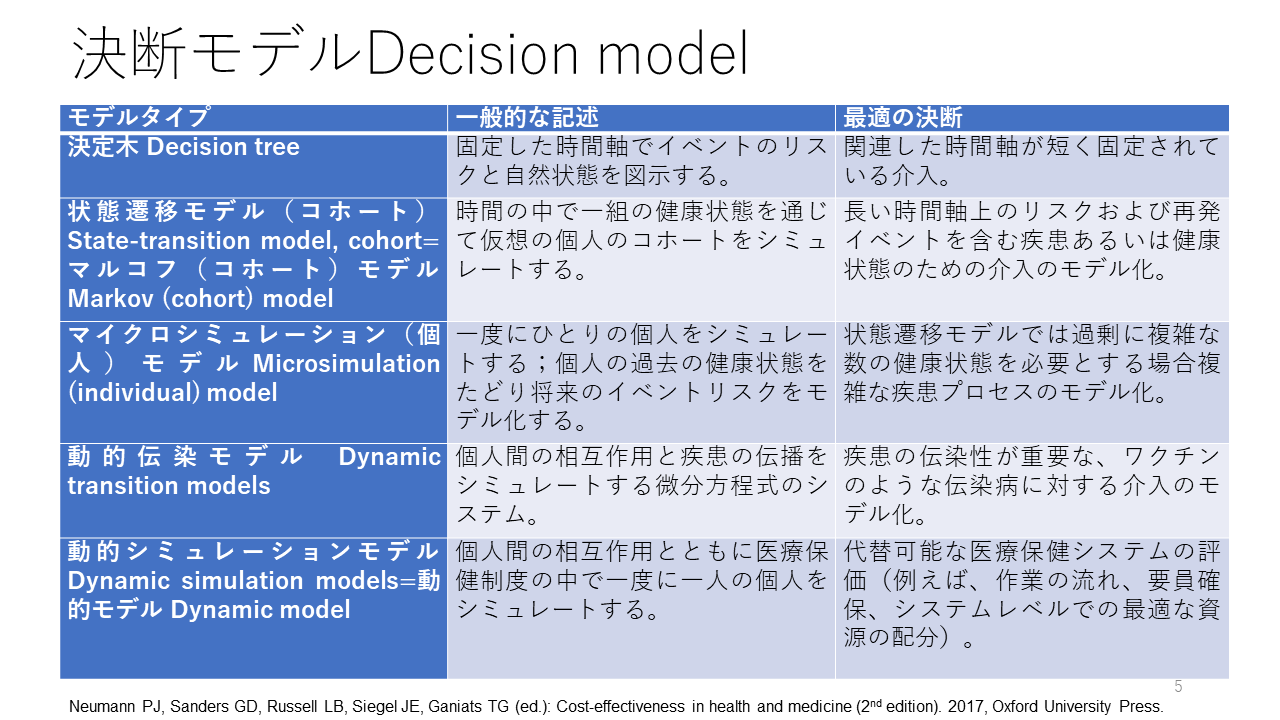
診断法の益と害の評価方法には決定木以外にマイクロシミュレーションなど、いくつかの決断モデルがあります。
例えば、USPSTFの大腸癌スクリーニングの推奨に関してはマイクロシミュレーションが用いられています。


















 2つの診断法の感度・偽陽性率(特異度)
2つの診断法の感度・偽陽性率(特異度)
 J個の診断法の感度のCovariance 共分散
J個の診断法の感度のCovariance 共分散
 共分散による感度の調整:3つの診断法の場合
共分散による感度の調整:3つの診断法の場合
 共分散に対する制限: 3つの診断法の場合
共分散に対する制限: 3つの診断法の場合
 決断モデルDecision model
決断モデルDecision model