メタアナリシスの意義と原理について、解説します。
システマティックレビューの一部が定量的統合、すなわち、メタアナリシスです。
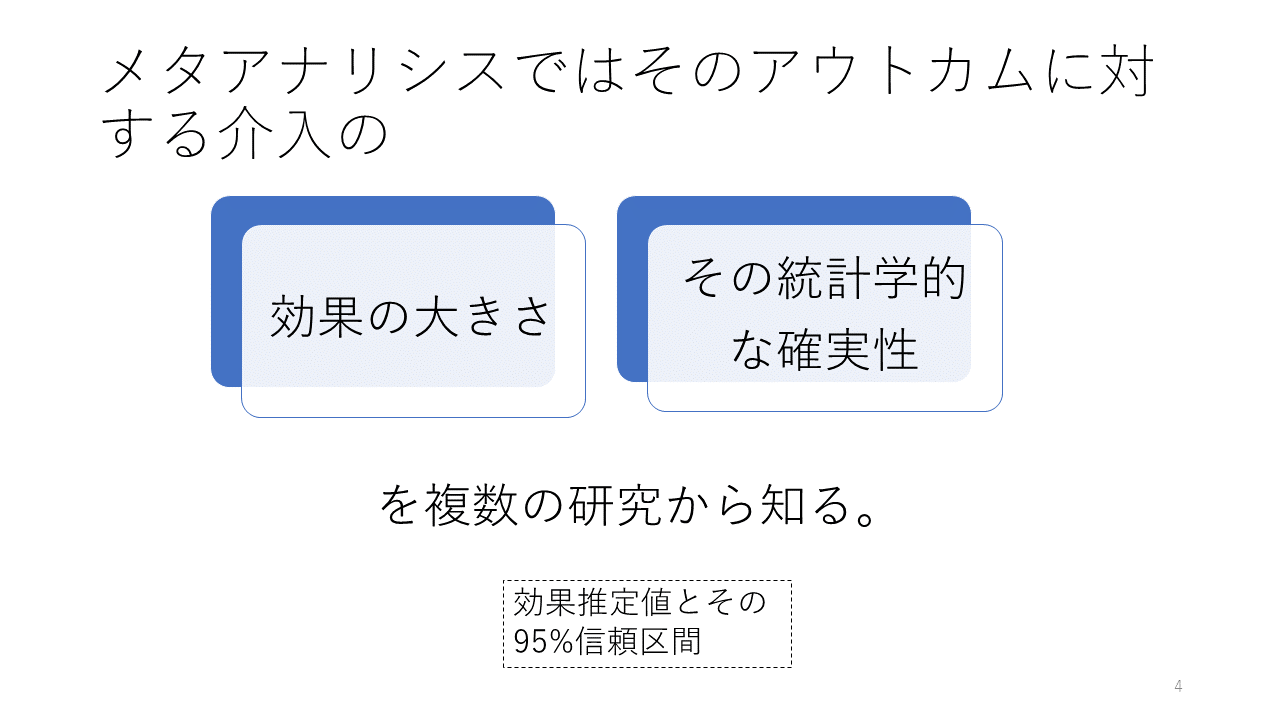
メタアナリシスの目的は、そのアウトカムに対する介入の効果の大きさと、その統計学的な確実性を知ることにあります。メタアナリシスは複数の研究をまとめ、効果推定値 とその95%信頼区間を明らかにする、と言い換えることができます。
効果の大きさを表すために、さまざまな指標が用いられています。アウトカムが治癒・非治癒のような二値値変数の場合にはリスク比、オッズ比、リスク差などが効果指標として用いられ、イベントが起きるまでの時間を比較する場合にはハザード比、アウトカムが連続変数で測定される場合には 平均値差や 標準化平均値差が 効果指標として用いられます。
メタアナリシスでは複数の研究をまとめた、これら効果指標の統合値と95%信頼区間が得られます。
まず、メタアナリシスの原理を簡単に説明します。
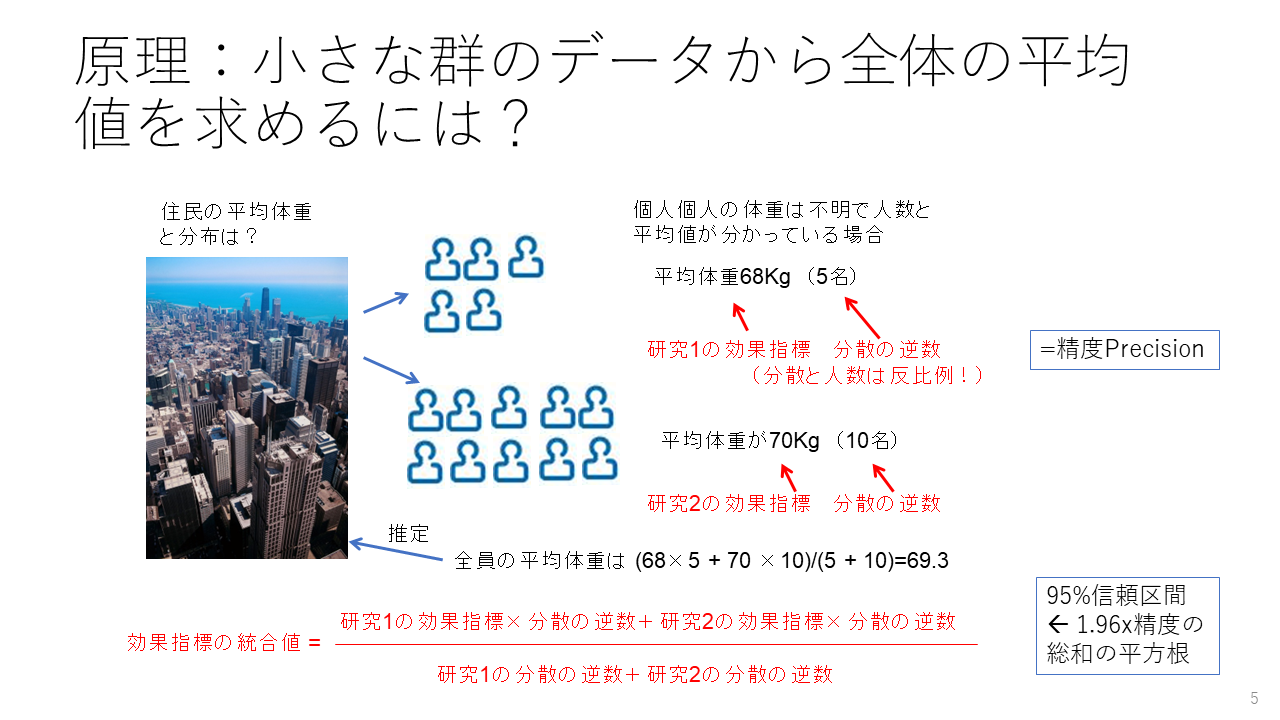
たとえば、ある都市の住民の平均体重を知りたいときに、個々の住民の体重はわかりませんが、ある地区の住民5名の平均体重が68Kgであることがわかっているとします。そして、別の地区の住民10名の平均体重が70Kgであることがわかっているとします。このデータから市の住民の平均体重を知りたい場合、 (68×5 + 70 ×10)/(5 + 10)で算出できます。メタアナリシスでは、各研究の効果指標の値がそれぞれの地区の住民の平均体重に相当し、効果指標の分散の逆数がその人数に相当します。
サンプルの人数が多いほど平均値のばらつきが小さくなり、分散も小さくなり、分散の逆数と人数が比例するということは直感的に理解できると思います。
効果指標の統合値はそれぞれの分散の逆数で重み付けした平均値に相当します。信頼区間は分散の逆数の総和の逆数の平方根を標準偏差として、その1.96倍離れた値になります。
メタアナリシスにはさまざまな統計学的手法があります。統計学的なアプローチの違いとして、頻度論派の伝統的な統計学に基づく方法と、ベイズ統計学に基づく方法があります。
いわゆるアグリゲートデータ、すなわち研究ごとの効果指標の値を統合する、古典的なメタアナリシスと、個々の症例のデータの提供を受けてそれらを統合するIPDメタアナリシスがあります。
また、新しい研究が発表された際にそれをそれまでのメタアナリシスに追加して、順次研究数を増やしていく、累積メタアナリシス、さらに統合値が無効化の方向へ変動しているかどうかを解析するTrial Sequential Analysisが行われる場合もあります。
さらに、近年論文数が増加している、3つ以上の介入を同時に比較するネットワークメタアナリシスがあります。ネットワークメタアナリシスは間接比較のデータも用いるので、理論的にはペア比較の通常のメタアナリシスより確実性が高まるとされています。また、シングルアームの臨床研究のデータも利用できるアームベースネットワークメタアナリシスも用いられることがあります。
診断精度研究のメタアナリシスの場合、感度・特異度の統合値が得られます。感度と特異度の間には通常負の相関があるため、二変量モデルが推奨されており、さらに割合の変数の分布をバイアスなく取り扱うため二項分布を用いる方法が推奨されています。感度と特異度の関係を示すことができるHSROCモデルはSROC曲線のパラメータから任意の特異度に対する感度の値を知ることができます。すなわち、閾値を変動させた際の感度・特異度を知ることができます。
出版バイアスを減らすために、出版された論文だけでなく、学会プロシーディングスなどいわゆるグレイリタラチャーも用いる場合もあります。
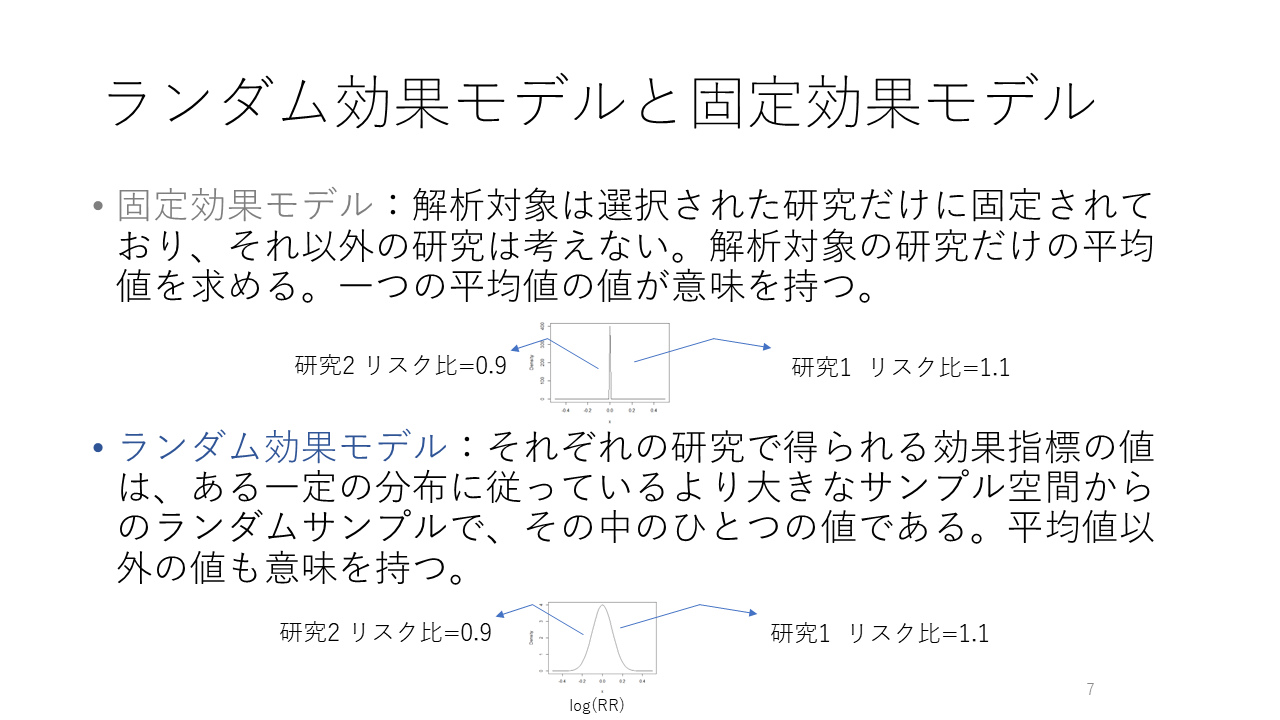
メタアナリシスではランダム効果モデルと固定効果モデルの少なくとも2種類のモデルが用いられています。
まず固定効果モデルを見ていきましょう。固定効果モデルはFixed effects modelとeffectが複数形のeffectsとなっています。それでは、Fixed effect modelと単数形のモデルもあるのでしょうか?
実はありますが、それはFixed effects modelとは異なります。
なぜ、複数形なのでしょうか。メタアナリシスでは複数の研究を統合します。それぞれの研究の効果推定値はeffectと単数形で表すことができます。複数の研究をまとめるとなると、effectsと複数形になります。メタアナリシスに含める研究の平均値を知ることが、固定効果モデルの目的です。メタアナリシスの解析対象は選択された研究だけに固定されていて、それ以外の研究は考えません。平均値を知ることに意義があるのであれば、固定効果モデルを用いることに何の問題もありません。
一方、ランダム効果モデルRandom effects modelはそれそれの研究で得られる効果推定値、すなわち効果指標の値は、ある一定の分布に従っているより大きなサンプル空間からのランダムサンプルで、その中の一つの値であると考えます。より大きなサンプル空間を想定するので、今後の研究の結果を推定することにも使えます。臨床研究のメタアナリシスの場合は、ランダム効果モデルを用いるべきとされています。臨床研究は、研究デザイン、対象者、研究の執行、研究のセッティングなどを同一にすることは困難です。研究結果は、偶然によるサンプリングエラー以外の要素の影響を受けます。そのため、もともと各研究の効果推定値はある一定の分布に従っているより大きなサンプル空間からのランダムサンプルで、その中の一つの値であるという考え方がマッチします。
ランダム効果モデルでは、各研究の効果推定値が計算された後、各研究間の分散が計算され、それが各研究の効果推定値の分散に合算され、その逆数を重みに用いて統合値が算出されます。ランダム効果モデルは統合値が真の値として意味を持つという解釈だけでなく、その分布も実際にありうる値とみなす必要があります。真の値がその値である確率ではなく、その値で効果が認められる確率と考えるべきです。二つの考え方は結果としては同じになるかもしれませんが、
Hedges LV, Vevea JL (1998). “Fixed- and Random-Effects Models in Meta-Analysis.” Psychological Methods, 3(4), 486?504.
Laird NL, Mosteller F (1990). “Some Statistical Methods for Combining Experimental Results.” International Journal of Technology Assessment in Health Care, 6(1), 5?30.
Higgins JP, Thompson SG, Spiegelhalter DJ: A re-evaluation of random-effects meta-analysis. J R Stat Soc Ser A Stat Soc 2009;172:137-159. doi: 10.1111/j.1467-985X.2008.00552.x PMID: 19381330 https://pubmed.ncbi.nlm.nih.gov/19381330/
Ades AE, Lu G, Higgins JP: The interpretation of random-effects meta-analysis in decision models. Med Decis Making 2005;25:646-54. doi: 10.1177/0272989X05282643 PMID: 16282215 https://pubmed.ncbi.nlm.nih.gov/16282215/
研究間の変動(variation)の原因:
1.アウトカム定義のランダムな変動
2.対象者の変動
3.プロトコールの変動
4.プロトコール実行の変動
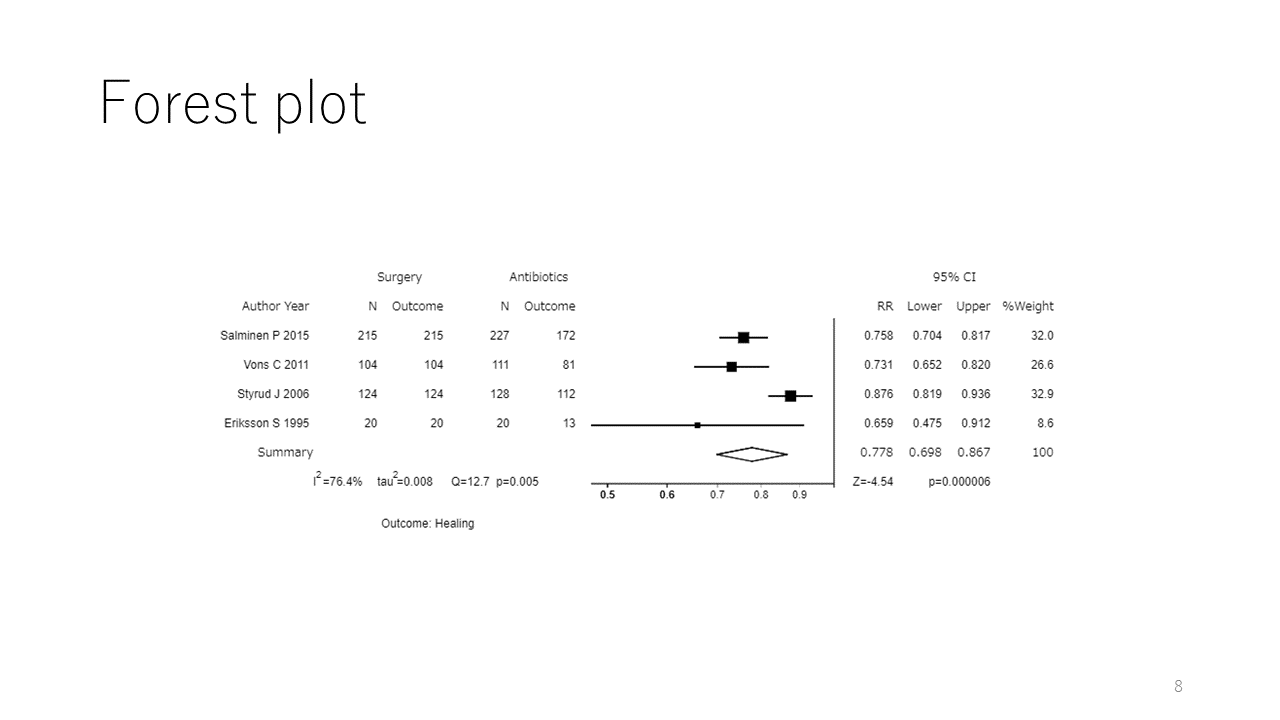
メタアナリシスの結果として、効果指標の統合値と95%信頼区間が得られますが、ここに示すForest plotとして出力されることが一般的です。
この例では、効果の大きさを表すのに、リスク比が用いられています。中央部分の下の方に菱形で示されているのが、統合値と95%信頼区間です。各研究の効果指標の値と95%信頼区間はその上に表示されています。中央の正方形は分散の逆数、すなわちサンプルサイズに応じた大きさで表示されます。バーの長さは95%信頼区間を表しています。右側には実際の値が表示されています。
左側の方には、各研究からのデータが表示されています。アウトカムが治癒という二値変数なので、対照群と介入群の症例数とアウトカムが生起した例数、すなわちイベント数が示されています。
右側には、さらに各研究の相対的な重みの値がパーセントで示されています。これは各研究の効果推定値の分散の逆数から計算されています。
左下には、統計学的な異質性の指標として用いられる、I二乗値、タウ二乗値、Q統計値とそのP値が示されています。右下には、統合値に対するZ値とP値が示されています。
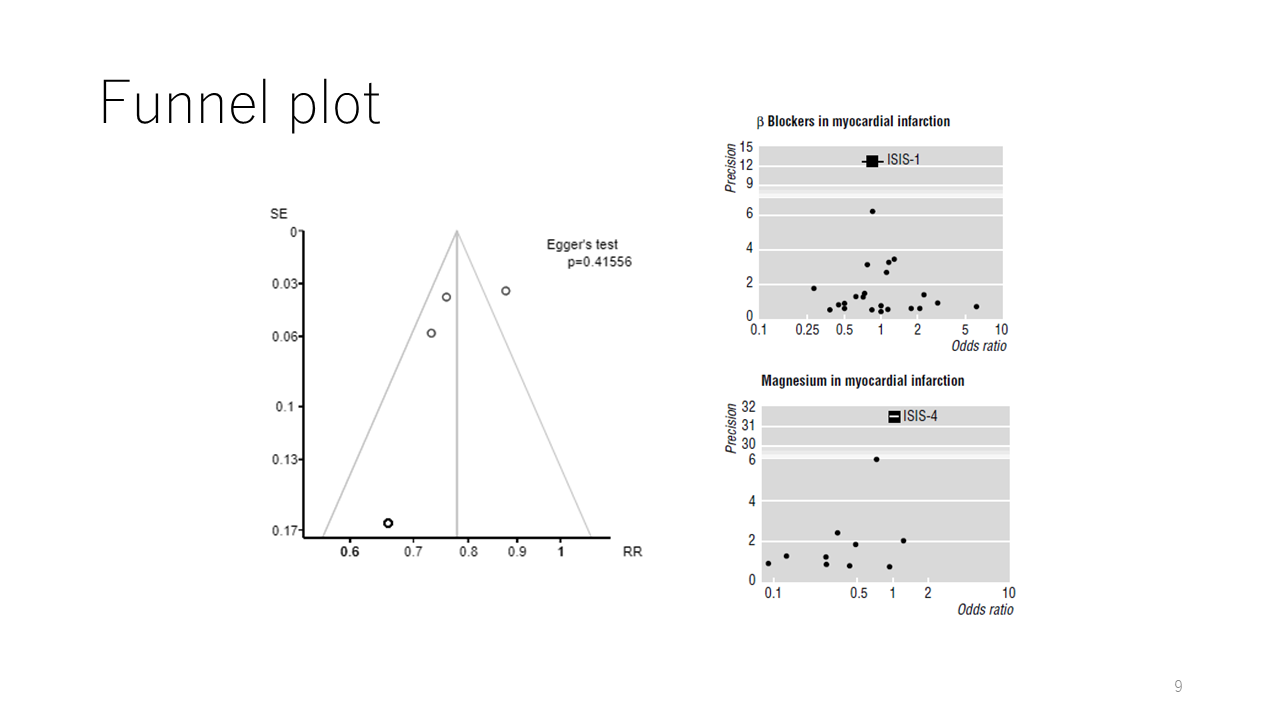
これはFunnel plotです。漏斗を伏せた形からその様に呼ばれています。Funnel plotは出版バイアスの可能性について判断するのに用いられます。丸は個々の研究の効果推定値を表し、横軸がそのスケールになります。左側に示す例では、リスク比を用いており、対数変換した値です。
Funnel plotでは、横軸が効果指標の値、縦軸がサンプルサイズあるいは標準誤差の逆数などの正確度の指標で、下の方ほどサンプルサイズが小さい研究になるため、左右にばらつき、上の方ほど、真の値近づくという分布になります。
右上の例では、下の方の点が左右均等に分布しているので、オッズ比の値が大きい研究も、小さい研究も同じように報告されていると考えられ、出版バイアスはないと判定されます。
もし、例えば、右下の例のように、下の方の点が右側に分布していない場合、大きなオッズ比の値が得られた研究が報告されていなかったことを疑わせることになり、出版バイアス(報告バイアス)が疑われます。
また、この分布に直線回帰を当てはめ、P値を計算するEggerの検定あるいはBeggの検定も出版バイアス判定の際に参照されます。なお、Beggの検定はノンパラメトリック検定の方法です。
ただし、研究数が10件以上(5件以上という専門家もいる)のときに限り、ファンネルプロットや検定を用いるべきとされている。
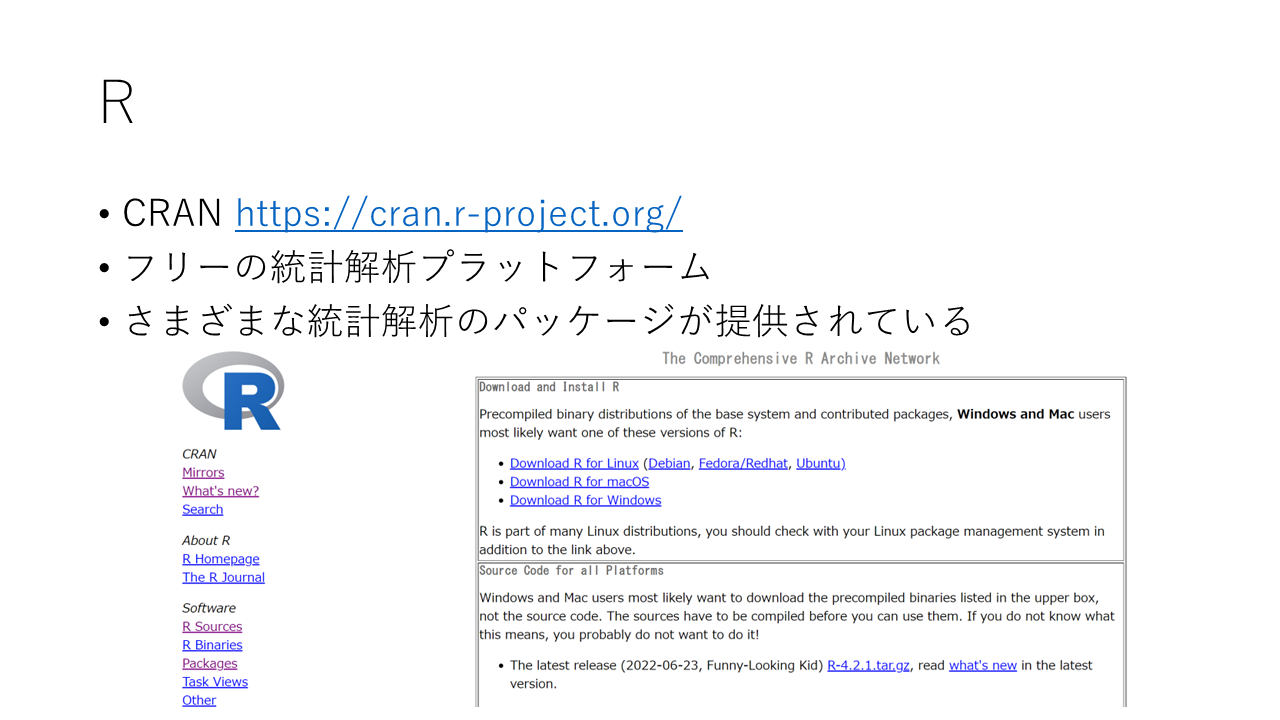
メタアナリシスを行うための、PCプログラムは多数あります。
その前に、クイズをやってみましょう。
Quiz 1
Quiz 2
MA-IZ解説動画 https://youtu.be/NI0JCuUe58s
YouTube URL:
VIDEO
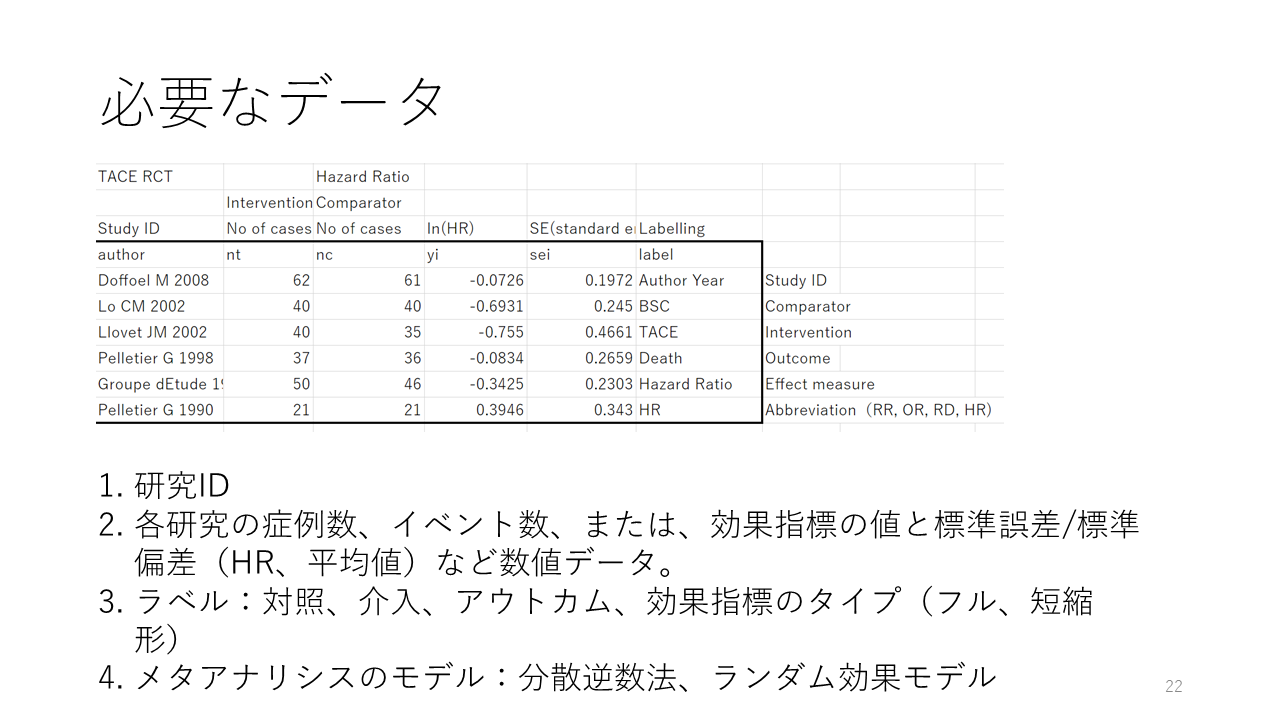
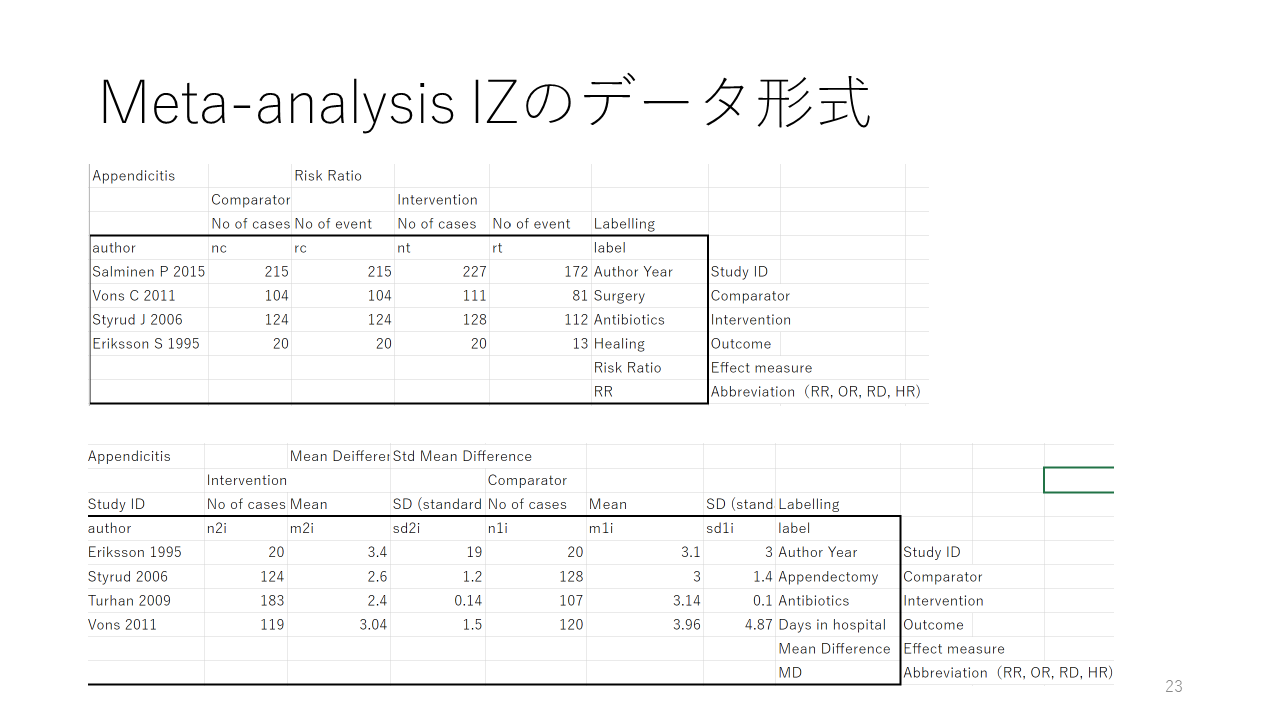
メタアナリシスに必要なデータは各研究から抽出し、Excelなどでまとめる必要があります。解析データの準備について解説します。
システマティックレビュー/メタアナリシスを論文化する場合は、研究プロトコールができた時点で、PROSPERO International rospective register of systematic reviesに登録しましょう。
システマティックレビュー/メタアナリシスの構想の段階でも、PROSPEROで類似の研究があるかどうか調べることが必要です。出版される前の時点の研究も検索することができるので、もしすでに類似の研究が進行中の場合は、別のテーマを取り扱うべきだということを知ることができます。
PROSPERO https://www.crd.york.ac.uk/PROSPERO/
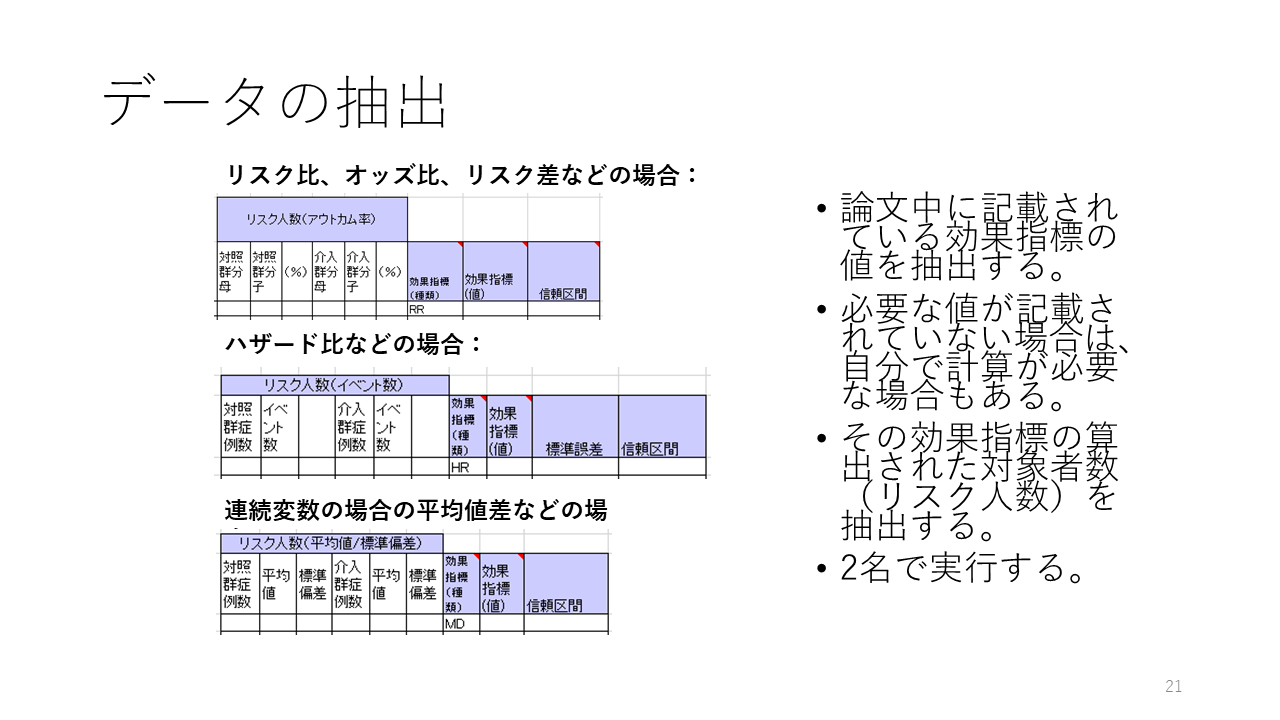
論文中に記載されている効果指標の値、リスク人数すなわち対象者数のデータを抽出します。
リスク比、オッズ比、リスク差などの場合は、人数のデータを抽出します。対照群の症例数とイベント数、すなわちアウトカムが生起した症例数、および、介入群の症例数とイベント数です。
ハザード比の場合にはハザード比の対数の値と、対数スケールでの標準誤差の値を抽出します。
連続変数の場合には、平均値と標準偏差の値を抽出します。
リスク比、オッズ比、リスク差の自然対数とその標準誤差(95%信頼区間から計算することも可能)がわかれば、それらから統合値を計算することもできます。
Forest plotを作成するためには、効果に関連する数値データ以外の情報も必要になります。
研究IDは多くの場合第一著者と年度が用いられます。そして、解析対象の数値データ、Forest plotのレベル用のデータが必要です。すなわち、対照・介入の名称、アウトカムの記述、効果指標のタイプ、例えば、Risk Ratio、などとその短縮形、Risk RatioであればRR。
そして、多くの場合、Forest plot内にメタアナリシスのモデルについての情報が書かれています。今回は、分散逆数法でDerSimonian-Laird法によるランダム効果モデルを用います。
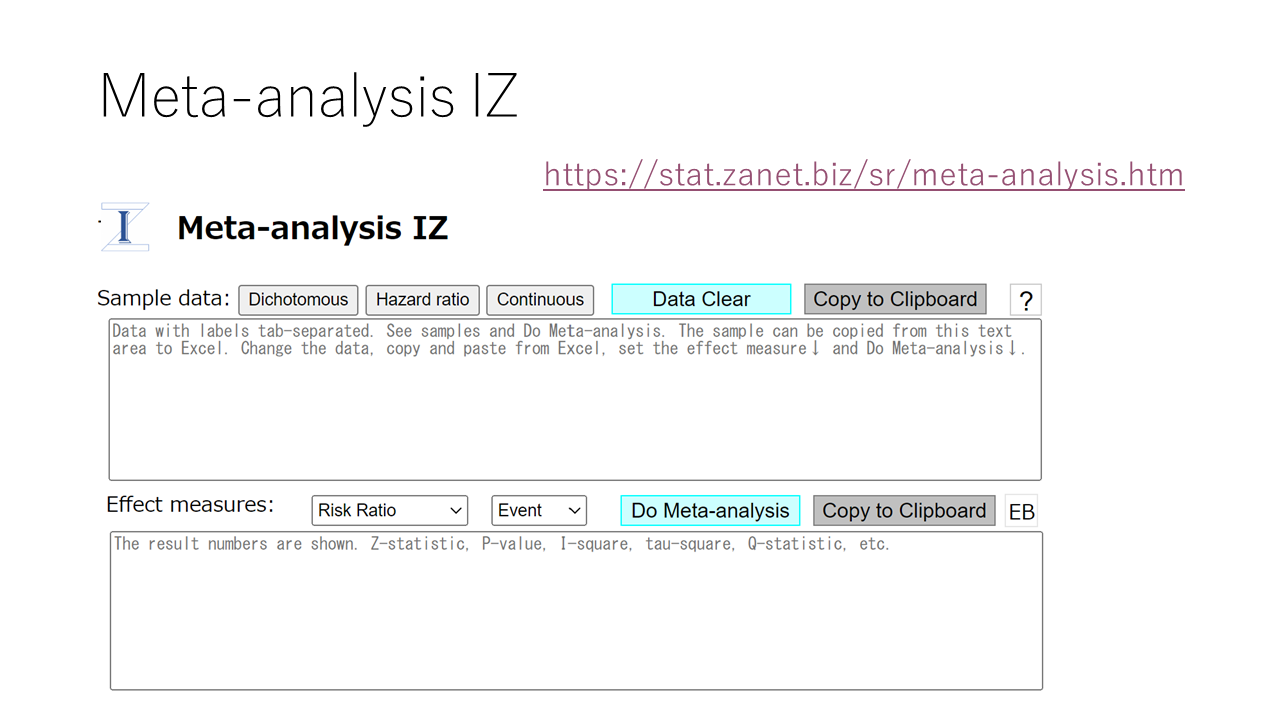
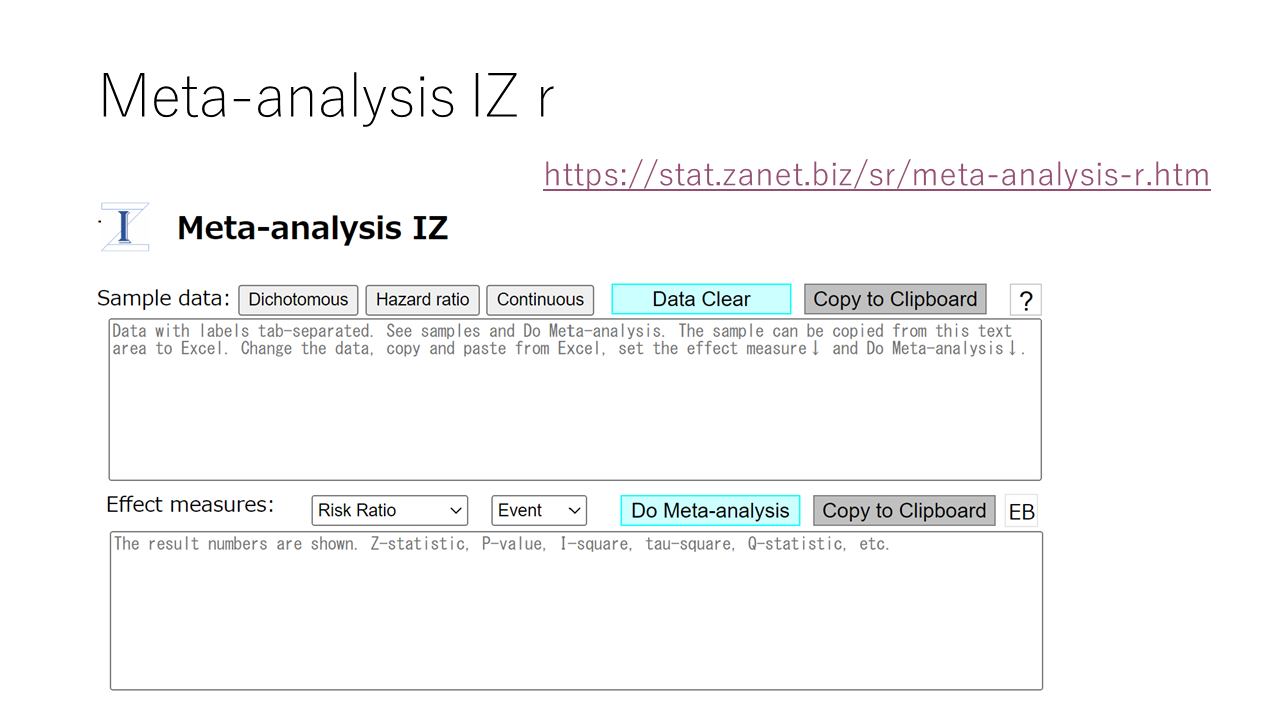
MA-IZの解析データはデータサンプルをコピーしてExcelに貼り付けることで確認できます。Excelで自分のデータに書き換えて、それに対してメタアナリシスを実行し、解析結果の数値データとForest plotとFunnel plotを出力します。
各自Meta-analysis IZのウエブページを開いて、実際にメタアナリシスを実行してみてください。
その前に、クイズをやってみましょう。
Quiz 3
リスク比、オッズ比、ハザード比は自然対数に変換して計算が行われるます。リスク差、平均値差は元のスケールのまま統合の計算が行われます。
学習終了後にこの学習ユニットの評価をお願いします。1分ほどで終了します。学習ユニット評価
close
回答はこちら
close
単純に症例数を合計して効果指標の値を計算すると“シンプソンのパラドックス”として知られる矛盾した結果が得られることがあります。
統合値の分散は分散の逆数すなわち精度を合計し、その逆数を求めることで計算されます。95%信頼区間を計算するには、その平方根を求め、1.96倍して、統合値に加算あるいは減算します。リスク比、オッズ比、ハザード比の場合は、対す変換した上で、計算し、エクスポネンシャルを求めます。
例えば、各研究の効果推定値の分散の逆数(精度)はリスク比であれば、以下の式で計算されます。
1/rc + 1/rt - 1/nc - 1/nt
ncは対照群の症例数、ntは介入群の症例数、rcは対照群のイベント数、rtは介入群のイベント数
従って、リスク比 RR=(rt/nt)/(rc/nc)、ln(RR)=ln(rt/nt) - ln(rc/nc)
lnは自然対数。
close
回答はこちら
close
リスク比、オッズ比、ハザード比は対数変換しないと左右対称にはなりません。多くの場合、対数変換してプロットされているので、左右対称ですが、横軸の間隔は等間隔ではありません。
非一貫性の評価の際に、Forest plotで各点推定値の分布と、信頼区間の重なり具合を見ます。
各研究の症例数、さらに重みづけをパーセントで提示することが一般的です。各研究の信頼区間を示す横バーは標準誤差に基づき長さが決まりますが、各研究の重みは分散の逆数をパーセントで表しています。
close
回答はこちら
close
個々の症例のデータではなく、研究ごとの効果指標の値を統合する場合は、効果指標の値とその分散の値が分かればメタアナリシスで統合値を信頼区間を計算することは可能です。
close
正規分布に従う変数xのランダム標本がn個ある場合、平均値、標本分散、不偏分散はここに示す式で計算されます。
分散は、各標本の値と平均値の差の平方和を標本数または標本数から1を減じて割り算した値です。平均値より小さな値も、大きな値も二乗することで、すべて正の値になり、その総和を標本数で割り算するので、それぞれの標本の値がどれくらいばらついているかを表す指標になります。
標本分散は標本の値そのものがどれくらいばらついているかを示します。標本数が少ないと標本分散は母分散より小さくなるのを補正したのが不偏分散で、母分散の推定値になります。
close
メタアナリシスの統合値の分散を計算するには、分散逆数法の場合、各研究の効果推定値に分散の逆数を掛け算して、その総和を分散の逆数の総和で割り算します。言い換えると、分散の逆数で重みづけ平均を計算します。
各研究の効果推定値に係数として、各研究の効果推定値の分散の逆数÷各研究の効果推定値の分散の逆数の総和を掛け算して、総和を計算することになります。
変数xに係数aを掛け算した値の平均値と分散をどのように計算するかを知る必要があります。
それをここに式で示します。結論としては、各研究の効果推定値の分散に係数の2乗値を掛け算すると、その研究の効果推定値の分散が得られるということになります。
close
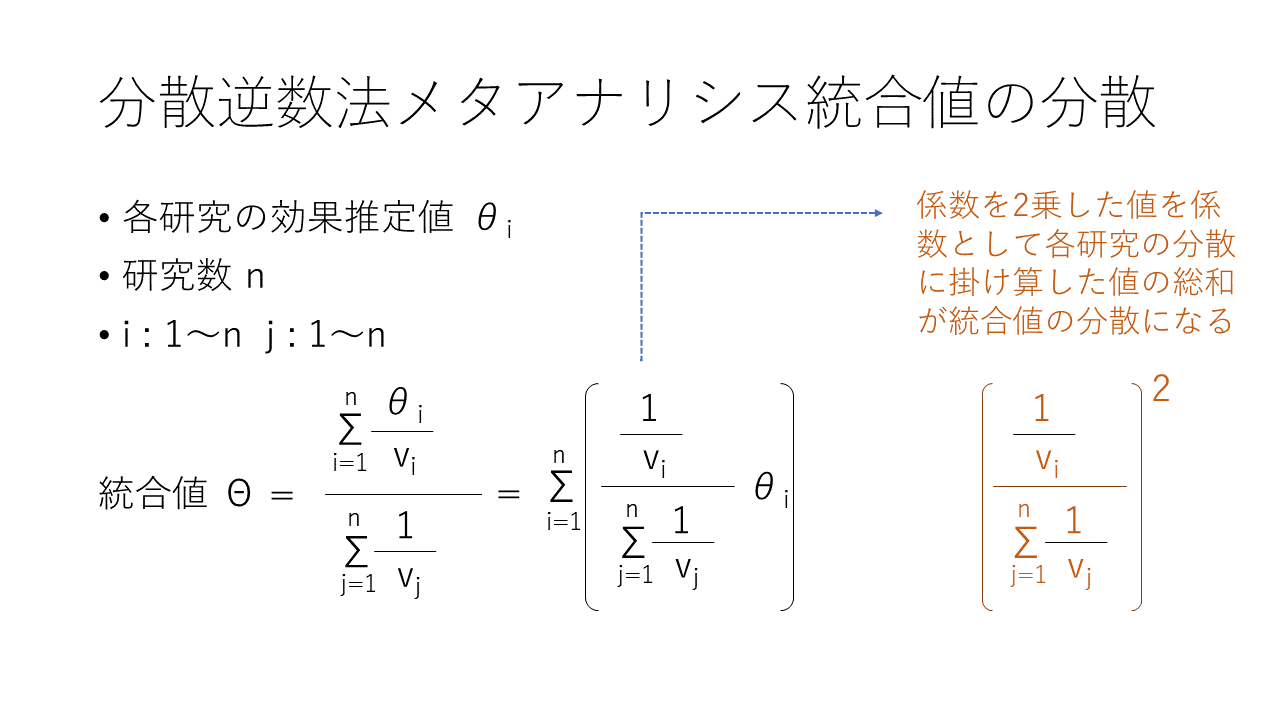
メタアナリシスで分散逆数法を用いる場合は、統合値として各研究の効果推定値θを分散vの逆数で重みづけした平均値を求めます。
分散の逆数の総和はひとつの値です。従って、各研究の効果推定値に各研究の分散の逆数と分散の逆数の総和を掛け算した値を各研究の効果推定値に係数として掛け算してその総和を求めれば統合値が得られます。
統合値の分散は各研究の効果推定値に掛け算する係数、すなわち、各研究の分散の逆数と分散の逆数の総和を掛け算した値を二乗した値を各研究の分散に掛け算して総和を求めることで得られます。、黄色のマーカーを付けた部分を計算すると、次の行に示すように各研究の分散の逆数の総和になり、それを各研究の分散の逆数の総和の二乗で割り算することになり、各研究の分散の逆数の総和の逆数になります。
各研究の分散の逆数は各研究の効果推定値に対する重みの値なので、統合値の分散は各研究の効果推定値の重みの総和の逆数になります。
そして、統合値の分散の平方根(ルート)が統合値の標準誤差になり、表儒誤差の値に1.96を掛け算した値を±すると95%信頼区間の値が得られます。
close
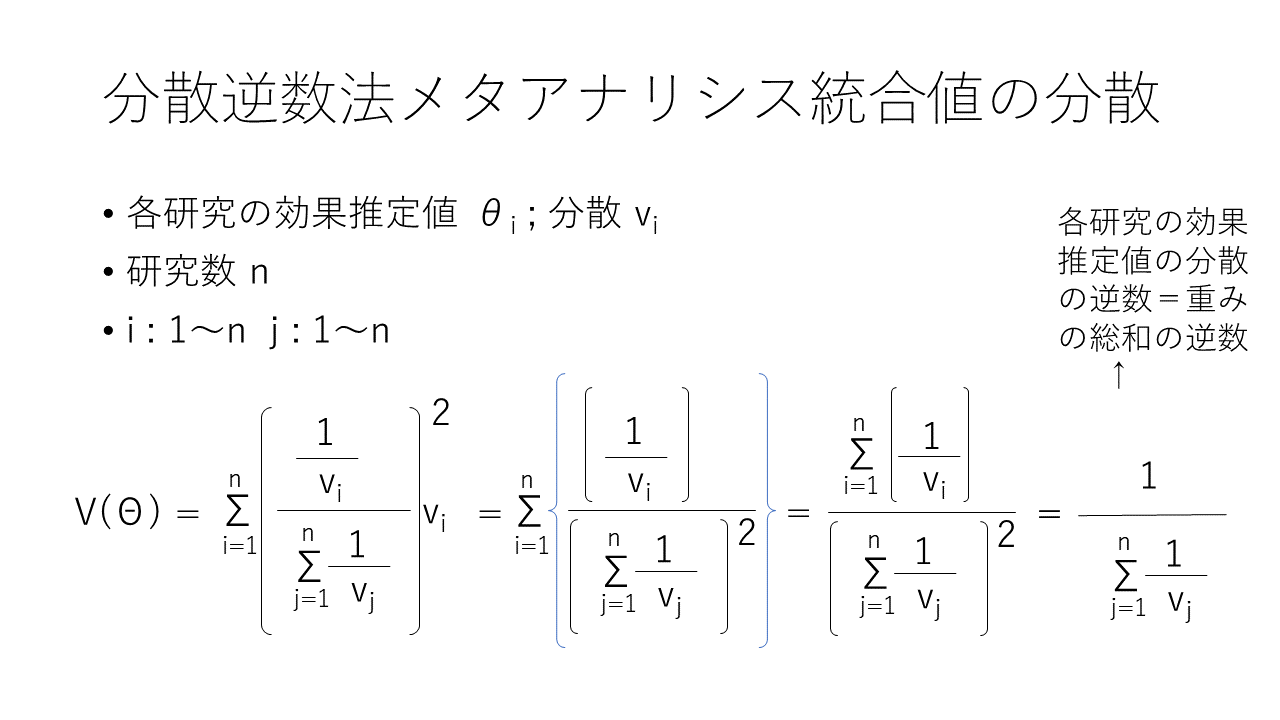
分散逆数法によるメタアナリシスの統合値の分散は、各研究の効果推定値に掛け算される係数を2乗した値を係数として各研究の分散の値に掛け算した値の総和が統合値の分散になります。
close
分散逆数法によるメタアナリシスの統合値の分散は、各研究の効果推定値に掛け算される係数を2乗した値を係数として各研究の分散の値に掛け算した値の総和が統合値の分散になります。
式を展開すると、統合値の分散の値V(θ)は各研究の効果推定値の分散の逆数の総和の逆数になる。すなわち、重みの総和の逆数となります。



 分散Variance
分散Variance
 xiに係数aを掛け算した値の分散Variance
xiに係数aを掛け算した値の分散Variance
 分散逆数法のメタアナリシス統合値の分散
分散逆数法のメタアナリシス統合値の分散